基于低频特征和难样本调制策略的小样本目标检测方法
本发明涉及模式识别与计算机视觉领域,具体涉及一种基于低频特征和难样本调制策略的小样本目标检测方法。
背景技术:
1、小样本目标检测是当前计算机视觉领域备受瞩目的课题,其指的是在数据集中目标示例数量非常有限的情况下,仍然能够精确地识别和定位目标物体。传统的目标检测方法通常依赖于大规模丰富的数据集来进行训练,然而,当面临小样本情景时,这些方法的性能往往会显著下降。小样本目标检测在现实生活中的应用领域广泛,包括监控摄像头、自动驾驶汽车、医学影像分析以及工业质检等多个领域。在这些应用中,可用的大规模数据集通常是有限的,这进一步加剧了小样本问题。传统的目标检测方法在这些场景中难以表现出令人满意的性能。
技术实现思路
1、本发明的目的在于提供一种基于低频特征和难样本调制策略的小样本目标检测方法,该方法可以在少量样本的情况下,获得较好的目标检测性能。
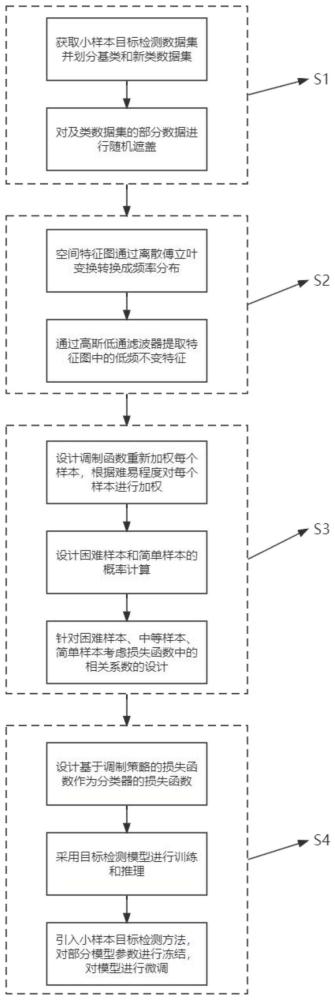
2、为了实现上述目的,本发明采用的技术方案是:一种基于低频特征和难样本调制策略的小样本目标检测方法,包括以下步骤:
3、步骤s1:获取小样本目标检测数据集并划分为基类数据集和新类数据集,并采用随机概率方式对图像中的部分像素进行遮盖,遮盖后的图像用来训练特征提取网络,以提高网络的泛化性能;
4、步骤s2:采用已训练的特征提取网络作为特征提取模块,引入低频模块,以提取图像中的不变特征;
5、步骤s3:针对难以识别的样本,设计调制策略来进行识别,避免模型过多关注难以识别的样本而过拟合;
6、步骤s4:设计基于调制策略的损失函数,并采用faster-rcnn目标检测模型进行训练;首先在基类数据集中对获取到的特征进行分类和回归,得到目标检测结果,然后在新类数据集中冻结有关模块,对模型进行微调,得到小样本目标检测结果。
7、进一步地,步骤s1具体包括以下步骤:
8、步骤s11:从网络上获取公开的小样本目标检测数据集,并获得小样本数据的划分标准;将小样本目标检测数据集按照划分标准划分为基类数据集和新类数据集,其中基类数据集含有大量样本数据,而新类数据集是在小样本目标检测数据集中与基类数据集类别不相交的数据集,新类数据集中每个类别的样本数量少,新类数据用于步骤s4中的模型微调;
9、步骤s12:在仅用基类数据集进行目标检测模型训练的情况下,对输入图像进行非线性掩码变换处理,将图像中的40%的区域进行遮挡;遮挡的策略为:将原始图像分成m个不重叠的黑色小掩码单元块,使用蒙特卡洛法选择n个小单元进行遮盖,实现设定比例区域的遮盖,同时不改变标签的真实值;
10、步骤s13:为了加速在小样本目标检测任务上的模型训练,采用预训练的resnet101特征提取网络来初始化网络权重和参数,以加快模型收敛速度。
11、进一步地,步骤s2具体包括以下步骤:
12、步骤s21:将特征提取网络得到的空间特征图通过离散傅立叶变换转换成频率分布;当输入特征图在频域分布时,将其通过高斯低通滤波器,输出的高频信息被滤除;最后,通过离散傅里叶逆变换获得输出特征图;
13、步骤s22:数字低通滤波器采用核为m×m的高斯低通滤波器;为了减少计算量,将高斯低通滤波器从频域转换到空间域;数字空间高斯低通滤波器g(·)的功能定义为:
14、
15、其中,x表示输入空间,y表示可能的标签集;
16、步骤s23:提取到深度特征后,将深度特征转化为低频特征,以提取要素图中包含的低频信息;具体过程如下:
17、
18、f(θf,θg)=l(g(pool(lf(f(xdft,θf),θg))),ydft)
19、其中,θg是线性分类层g(·)的参数,θf是特征提取网络f(·)的参数;和是在数据集上训练的线性分类层g(·)和特征提取网络f(·)的优化参数,用于后续的训练;f(·)是参数优化所使用的函数;l(·)是交叉熵损失;pool(·)是全局平均池化层;xdft是经过离散傅里叶变换的特征图,ydft是经过离散傅里叶变换后的特征图所对应的真值;lf(·)是低频模块,即进行离散傅里叶变换和高斯低通滤波器的模块。
20、进一步地,步骤s3具体包括以下步骤:
21、步骤s31:用调制函数fadd(·)重新加权每个样本;调制函数将分类器预测p作为输入,p∈[0,1]是样本属于某个类别的概率,并为每个预测输出加权标量fadd(p);对每个样本应用适当的权重,以更好地调制难样本;根据训练样本的置信度来调制损失;总损失函数表示为:
22、
23、其中,l(·)是交叉熵损失函数;fadd(·)是调制函数;fadd(p)≥0;
24、步骤s32:定义ph为难样本的概率,定义pe为简单样本的概率;引入相关系数和敏感系数ρ,和ρ的定义如下:
25、
26、p=((f′add(ph))/(f′add(pe))
27、其中,f'add(·)表示fadd(·)的导数;相对系数衡量难样本权重与简单样本权重之比;的值越大表明网络更倾向于解决困难的例子而不是简单的例子;敏感系数ρ衡量难样本的权重变化与简单样本的权重变化之比;
28、对于小正值δ,从具有ph+δ的难样本到具有ph的另一个较难样本,较难样本的权重方差公式化为:
29、
30、对于简单的样本,权重的方差是:
31、
32、其中,ρ越大,表示难样本的权重比简单样本的权重增加得越快;当ρ较大时,网络将对难样本更敏感,在难样本中,稍低的置信度可能导致其权重的显著放大;
33、步骤s33:调制函数fadd考虑三种情况:
34、首先是难样本的学习情况:强调难样本的学习;与fadd(pe)相比,fadd(ph)的值越大,对难样本施加的惩罚就越大;从而使网络能够更好地对难样本进行分类;
35、其次是中等难样本的学习情况:∈是表示相对系数上限的一个中等因子;∈大于1,且∈的值不应太大,∈如果太大那么网络将只学习难样本而忽略简单样本,会导致学习具有偏向性;
36、最后是简单样本的学习情况:ρ<ξ;ξ是限制权重方差的敏感因子;ξ小于1,否则调制函数会对难样本引入过于敏感的惩罚。
37、进一步地,步骤s4具体包括以下步骤:
38、步骤s41:引入交叉熵损失函数l作为监督损失来训练模型;l的定义如下:
39、
40、其中,xi表示输入图像中的第i个物体,yi表示输入图像中的第i个物体的真值,m表示一张图像中识别到的目标数量;
41、步骤s42:假设α和β分别表示自适应斜率和偏差项;α和β按一般适度因子τ进行调整;θ是调制损失函数的超参数,用于调整调制函数对损失的影响;定义调制函数为:
42、fadd(ploss)=(αp+β)θ+1
43、其中,ploss是交叉熵损失函数l计算出来的样本概率,当α=0的时候,fadd(ploss)变为常数值,总的损失函数退化为交叉熵损失函数;
44、步骤s43:使用区域建议损失函数计算预测得到的带分割物体的位置与实际位置之间的差异并得到损失值liou,其计算公式如下:
45、
46、其中,liou表示检测目标的预测定位与实际定位的交并比,a和b分别表示预测框和真实框;
47、步骤s44:将训练好的模型在验证集上进行测试,得到最终的检测准确率;在训练好的模型的基础上,引入小样本的机制,将步骤s3之前的模型参数均进行冻结,在新类数据集上进行模型微调,得到适应于新类数据集的目标检测模型。
48、与现有技术相比,本发明具有以下有益效果:
49、1.能够在拥有少量样本的情况下快速收敛,获得较好的目标检测性能,通过对训练图像进行部分遮盖,防止了模型过拟合。
50、2.由于低频信息更具有特征不变性,更适合于小样本目标检测任务,而高频信息可能会损害模型的泛化性能和稳定性。为了能够适应不同数据的分布情况,通过将特征分布转化成频率分布,并提取低频率的特征,从而提取到图像中的不变特征,从而提高模型的检测能力。
- 还没有人留言评论。精彩留言会获得点赞!