一种基于互联网公开数据的企业关联信息挖掘方法与流程
本发明涉及数据挖掘领域,具体涉及一种基于互联网公开数据的企业关联信息挖掘方法。
背景技术:
1、目前现有的企业关联信息获取方法一般是人工到特定的网站查询,但这种方法受限于站点信息更新频率及数据来源单一等原因,会造成获取信息时效性较差、主观因素影响较大等问题。而通过互联网数据采集技术,自动化的从多站点采集特定的企业信息、企业最新新闻报道,然后将这些数据进行进一步的综合处理即可获取特定企业最新的更加全面、客观的关联信息。
2、申请201810735344 .5的发明专利申请虽然提供了一种企业关联关系信息挖掘方法,但是该方法中待检测文本仍旧需要工作人员自行采集并输入相应装置,而且确实对挖掘结果的验证环节,对现有技术中获取信息时效性较差、没有面向标题和段落进行分阶段的进行企业关联关系识别,资源占用量大,主观因素影响较大等问题仍旧没有太大改善。
技术实现思路
1、为了解决现有的企业关联关系信息挖掘中获取信息时效性差、信息量大、筛选信息困难、主观因素影响较大以及最终企业信息验证繁琐的问题,本发明提出了一种基于互联网公开数据的企业关联信息挖掘方法,资源占用小,速度快。
2、本发明的技术方案如下:
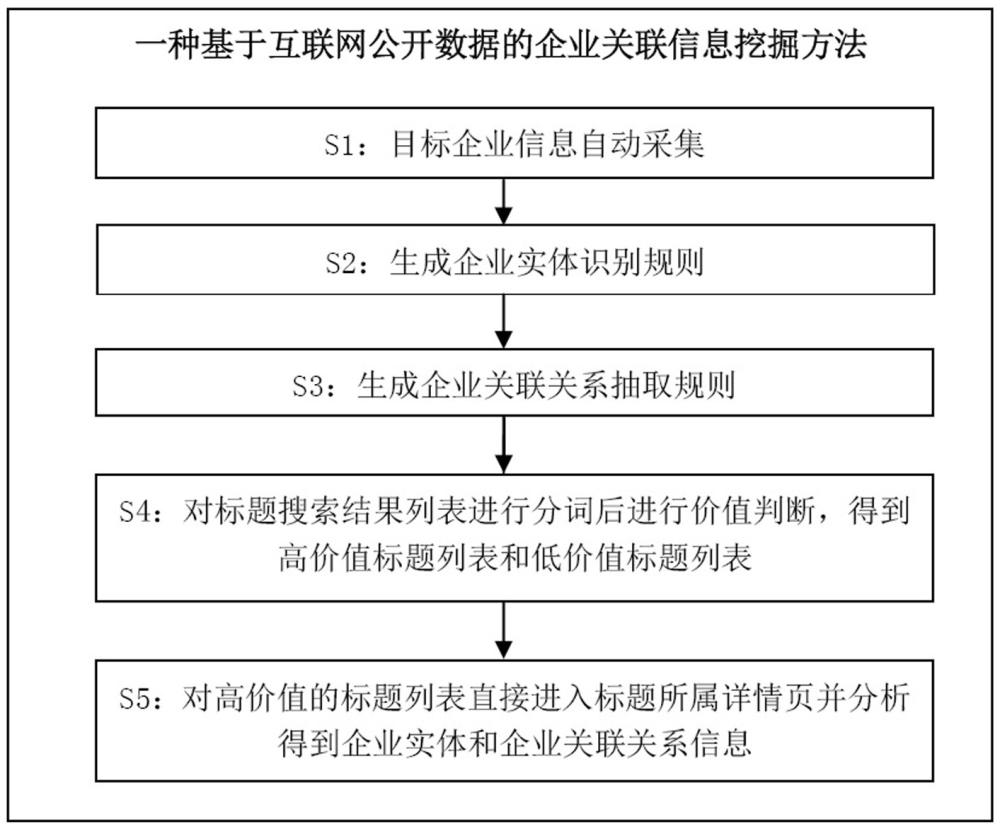
3、一种基于互联网公开数据的企业关联信息挖掘方法,具体步骤如下:
4、s1:目标企业信息自动采集:采用selenium(自动化测试工具)+ chrome自动化工具,模拟人工对浏览器的操作,对目标企业基本信息使用搜索引擎自动搜索得到标题搜索结果列表;
5、s2:生成企业实体识别规则;人工筛选s1中包含标题和详情页的企业基本信息的合规数据,对企业基本信息中的标题文本和详情页中的段落文本分别进行分词,收集形成对应的特征词词典,对文本分词后的词语进行序列标注,总结序列标注生成面向标题和面向段落的企业实体识别规则;
6、s3:生成企业关联关系抽取规则:基于互联网语料库、同义词和近义词表构建企业关联关系抽取关系规则;包括基于触发词的企业关联关系规则和基于依存句法的企业关联关系规则;
7、s4:基于s2中面向标题的企业实体识别规则对s1标题搜索结果列表进行分词后的文本是否符合现有的企业实体识别规则,以及文本的企业实体间的关联关系强弱进行价值判断,得到高价值标题列表和低价值标题列表;
8、s5:对高价值的标题列表直接进入标题所属详情页,基于s2中面向段落的企业实体识别规则和s3中面向段落的企业关联关系抽取规则进一步分析所述标题所属详情页段落,得到企业实体和企业关联关系信息。
9、优选的,s1中所述目标企业信息为:企业名称、法人、企业联系方式,企业邮箱等。
10、优选的,s2中所述构造企业实体识别规则的方法为:
11、s21:文本分词:人工筛选s1中企业基本信息的合规数据,并分类成标题文本和详情页文本作为训练文本;使用分词工具对企业基本信息中的标题文本和详情页中的段落文本分别进行分词;
12、s22:创建企业实体库,用于存储企业实体名称;
13、s23:收集特征词词典:抽取所述训练文本中的企业实体,对每一个企业实体进行分词后取最后一个词存入特征词词典并去重;所述特征词词典储存能够识别出实体词中包含的企业特征词语的词典;
14、s24:对s21中文本分词后的词语进行序列标注:并查询分词后的词语是否在s23的特征词词典里,并根据词语所处的条件分别对所述词语进行条件标注;
15、s25:根据s24所述标注情况,总结并分别生成面向标题和面向段落的企业实体识别带有序列标注的表达式,作为企业实体识别规则。
16、优选的,所述分词工具为jieba分词工具,所述特征词词典中特征词包括:企业、集团以及借助hanlp词典生成的特征词。
17、优选的,s24中所述该词语所处的条件包括:在特征词词典、不在特征词词典但在国家企业信用信息公示系统可查询到该词语、其他情况。
18、优选的,s25中生成的企业实体识别规则的表达式包括的信息有:企业公司词,企业公司词是否在特征词词典,企业公司词是否可以添加到特征词词典中。
19、优选的,一种企业实体识别规则的表达式设定方法为:o*n+o*e*o*e;其中,名词:n; 企业公司:q;如果企业公司词q在所述特征词词典里,则标记为e,否则拿q去国家企业信用信息公示系统查询,若能查询到,将q添加进特征词词典并将q重新标记为e,其他情况标记为o。
20、优选的,对于s4中标题搜索结果列表的企业实体名称,在s22所述企业实体库或者国家企业信用信息公示系统查询确认存在后方可正式确定为企业实体,确认企业实体的名称要存入所述企业实体库。
21、优选的,s3中所述基于触发词的企业关联关系规则的构造方法为:
22、s311:通过互联网公开语料库构建关于企业关联关系的触发词并建立企业关联关系触发词库;
23、s312:基于触发词的不同类型设定企业关联关系提取规则,所述企业关联关系包括:业务往来关系、合资企业和合作伙伴关系、供应链关系、股权关系、企业与政府之间的关系、企业与非盈利组织之间的关系。
24、优选的,s3中所述基于依存句法的企业关联关系规则的构造方法为:
25、s321:使用jieba、hanlp对训练语句进行依存句法分析,获取文本词对应的依存树;
26、s322:使用正则表达式语法确定企业关联关系提取三元组;所述三元组包括:实体*动词+实体、实体*和实体*动词+实体;
27、s323:对于基于依存句法规则提取的关系三元组经过人工审核,确认有效后将新发现的动词,加入触发词库。
28、本发明所产生的有益的技术效果
29、本发明提出了一种基于互联网公开数据的企业关联信息挖掘方法,使用基于规则的命名实体识别以及实体关系提取的技术,对目标企业信息自动采集后通过序列标注生成面向标题和面向段落的企业实体识别规则以及生成基于触发词的企业关联关系规则和基于依存句法的企业关联关系规则,通过企业名称特征词库构建和企业关联关系规则实现快速提取企业关联关系;同时根据文本中文本是否符合现有的企业实体识别规则,以及文本的企业实体间的关联关系强弱进行价值判断,得到高价值标题列表和较价值标题列表;实现了更准确的基于标题的抽取,节约了资源;再对高价值的标题列表直接进入标题所属详情页,基于面向段落的企业实体识别规则和面向段落的企业关联关系抽取规则进一步分析所述标题所属详情页段落,得到企业实体和企业关联关系信息。本发明实现从互联网采集数据中发掘企业关联信息,最大程度的解决了现有企业关联信息获取方法中存在的个人主观因素影响较大、特定站点数据不够全面等问题。在实践过程中该方法完美规避了在使用深度学习方法实现命名实体识别以及实体关系提取的过程中所面临的数据标注难题、冷启动等问题。另外,基于人工设置规则实现命名实体识别及实体关系提取,充分利用了人工经验,并且在基于依存句法规则提取关系的过程中又在一定程度上弥补了人工规则的主观性,使得关系提取规则更加全面。
- 还没有人留言评论。精彩留言会获得点赞!