一种基于跨尺度图对比学习的好友推荐方法
本发明涉及网络科学,尤其涉及一种基于跨尺度图对比学习的好友推荐方法。
背景技术:
1、社交网络在过去几年中取得了巨大的发展和普及,成为人们日常生活中重要的一部分。随着社交网络的快速增长,人们更加需要在网络中寻找和建立新的社交关系。而好友推荐系统作为社交网络的重要功能之一,可以帮助用户发现与自己兴趣爱好相似的潜在好友,提供更丰富、有意义的社交体验。
2、然而,传统的好友推荐系统往往面临着用户兴趣爱好难以准确捕捉、冷启动问题和隐私保护等挑战。近年来为了解决这些问题,图表示学习作为一种强大的机器学习技术,在好友推荐领域取得了显著的进展。图表示学习将拓扑图映射到低维向量空间,同时保持原始图结构并支持图推理。传统图分析方法具有计算和空间成本高等问题,且很难捕获网络中高度非线性的结构特征。这就推动了图神经网络方法的出现,图神经网络在处理不规则的非欧几里得数据上极具优势。图神经网络将图数据的结构特性融入算法模型,并利用样本实例之间的结构性特征将不同样本之间的关系信息进行有效且充分地表示,从而最大化利用现实图的结构特性。
3、在现实生活中,由于用户信息收集困难而导致的数据缺失的情况十分常见,而标签这一重要信息也正是经常缺失的数据之一,标签的缺失会导致现有的图神经网络方法产生训练困难的问题,这是由于在图神经网络的模型训练过程中需要依赖标签来设计损失函数,通常根据学习到的节点表示向量来预测该节点的标签,当缺失真实的标签时,依赖于标签的损失函数就无法指导模型的训练。而对比学习可以通过拉近正节点对的距离,推开负节点对来指导模型的训练,在这一过程中不需要使用标签信息。目前对比学习在图神经网络上的应用仍处于起步阶段,且由于图的复杂的结构特性,将对比学习应用于图神经网络中还面临着许多的挑战:1)数据增强方法的选择,目前的增强方法多使用抛弃节点、边或掩盖节点属性信息等方法,而对于不同的任务盲目地使用增强方法会导致图中信息严重丢失并引入过多的偏差,降低模型在下游任务的性能。2)当前图对比学习方法多是通过对比节点之间的向量进行训练,而图的全局语义结构这一重要信息并未得到充分利用。
4、目前,图对比学习的工作大多基于有标签的监督学习,忽略了图底层具有丰富结构和属性信息的数据特性,且标记图上的标签成本昂贵,这使得大多数现有方法不能应用于真实数据。随着对比学习在多个领域取得成功,研究对比学习如何应用于图结构数据的领域具有重要意义。
技术实现思路
1、针对上述现有技术的不足,本发明提出了一种基于跨尺度图对比学习的好友推荐方法,解决了图对比学习中忽略图的整体结构信息的问题。
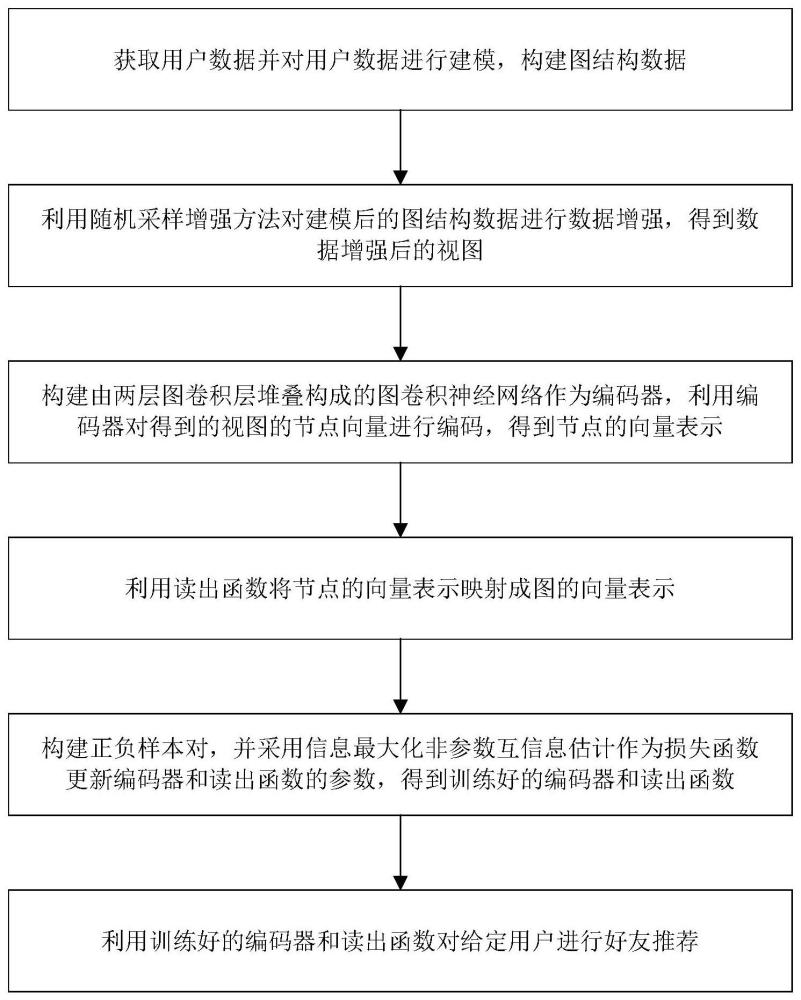
2、本发明提出的一种基于跨尺度图对比学习的好友推荐方法,该方法包括如下步骤:
3、步骤1:获取用户数据并对用户数据进行建模,构建图结构数据;
4、步骤2:利用随机采样增强方法对建模后的图结构数据进行数据增强,得到数据增强后的视图;
5、步骤3:构建由两层图卷积层堆叠构成的图卷积神经网络作为编码器,利用编码器对得到的视图的节点向量进行编码,得到节点的向量表示;
6、步骤4:利用读出函数将节点的向量表示映射成图的向量表示;
7、步骤5:根据节点的向量表示和图的向量表示构建正负样本对,并采用信息最大化非参数互信息估计作为损失函数更新编码器和读出函数的参数,得到训练好的编码器和读出函数;
8、步骤6:利用训练好的编码器和读出函数对给定用户进行好友推荐;
9、步骤1中所述图结构数据包括:节点、节点向量和节点间的边:其中所述节点表示用户,所述节点向量表示用户数据,所述节点间的边表示用户之间的好友关系,若两个用户之间存在好友关系则对应的两个节点之间存在一条边;
10、步骤2中所述数据增强的方法为:根据现有的数据增强方法对应的增强函数构建增强函数集合,记为t=(t1,t2,…,tk),其中t1表示第1个增强函数;t2表示第2个增强函数;tk表示第k个增强函数;对t进行两次随机采样得到两个不同的视图,其中每次随机采样从t中选取两个增强函数tm和tn来对建模后的图结构数据进行数据增强,再将数据增强后的图结构数据合称为一个视图,将数据增强后的图结构数据分别记为和其中g表示建模后的图结构数据;表示采用增强函数tm进行数据增强后的图结构数据;表示采用增强函数tn进行数据增强后的图结构数据;
11、所述图卷积层根据输入视图确定节点的邻接矩阵a,利用邻接矩阵a与该层的特征矩阵h(l)将节点的特征信息传播给邻居节点,再利用权重矩阵w(l)和激活函数σ获得下一层的特征矩阵h(l+1);
12、所述图卷积层获得下一层的特征矩阵的过程如下式所示:
13、
14、其中为度矩阵;是带有自环的邻接矩阵,且其中in为单位矩阵;h(l+1)为下一层的特征矩阵;h(l)为当前图卷积层根据节点的节点向量构成的特征矩阵;w(l)是该图卷积层独立的权重矩阵;σ为激活函数;
15、步骤5中所述构建正负样本对的方法为:对于图结构数据中的某一节点b,从数据增强后的视图中选取对应的节点b′,利用节点b的向量表示、节点b′的向量表示和节点b′所在视图的图的向量表示组成正样本对;对于节点b,从图结构数据和数据增强后的视图中任意选取若干个节点组成若干个负样本对,其中每个负样本对包括:节点b的向量表示、任意一个已选取节点的向量表示和节点b′所在视图的图的向量表示;
16、步骤5中所述损失函数表示为:
17、
18、其中为损失函数;zi和zj分别为视图中的第i个节点和第j个节点经过数据增强之后产生的投影向量;1[k≠i]为一个指示器函数,且当k≠i时该指示器的函数值为1,否则函数值为0;s( )为度量两个嵌入向量之间相似性的函数;为损失函数中的温度系数;
19、步骤5中所述得到训练好的编码器和读出函数的方法为:利用损失函数分别计算正样本对之间的相似性以及正样本对与若干个负样本对之间的相似性,通过最大化正样本对之间的相似性和最小化正样本对与负样本对之间的相似性,完成编码器和读出函数的训练;
20、所述步骤6进一步包括:
21、步骤6.1:对于给定用户,随机选取若干个用户构建待推荐用户集合。
22、步骤6.2:判断待推荐用户集合中是否存在不属于步骤1构建的图结构数据中的用户;若是则执行步骤6.3;若否则对不属于图结构数据中的用户执行步骤2-5来更新该用户对应的节点的向量表示,再执行步骤6.3。
23、步骤6.3:使用相似性计算函数分别计算给定用户和待推荐用户集合中各用户的相似性,将计算结果从大到小排序并选取相似性前s个用户作为本次推荐的好友。
24、采用上述技术方案所产生的有益效果在于:
25、本发明方法一种新的机器学习方法,即自监督学习方法,该学习方法不依赖于人工标注,通过设计代理任务并利用输入数据本身作为监督,根据丰富的无标签数据进行学习,从而获得更具有泛化性的图嵌入应用于下游任务中。
26、与现有方法在样本上进行对比学习的思想不同,本发明方法并非简单地使用一种或两种增强方法进行数据增强;而是在训练过程中不断利用随机采样增强方法进行数据增强,探索出适应输入的图的增强方法,减少了图中重要信息的损失,缓解了对不同下游任务盲目使用不合适的增强方法而导致模型性能下降的问题;同时,本发明方法不只通过对比节点级的信息进行模型训练,而是使用读出函数对图编码器编码后的节点向量进一步编码得到图级别的向量表示,然后通过节点级别信息和图级别信息的对比进行模型的训练,使模型在训练过程中融入了图的全局语义结构信息,从而提升下游任务的性能。
27、本发明方法针对同构网络,将跨尺度的对比学习引入到图表示学习中,提出一种面向同构图的跨尺度图对比学习算法,解决了盲目使用增强方法导致图中信息损失以及忽略图的全局语义结构信息的问题。
- 还没有人留言评论。精彩留言会获得点赞!