一种统计信息数据与影像数据的模态特征对齐融合方法
本发明涉及多模态数据融合领域,特别涉及一种统计信息数据与影像数据的模态特征对齐融合的方法,用于进行目标分类预测。
背景技术:
1、在当今的信息时代,我们面临着大量的多模态数据,包括图像、文本、语音等。这些多模态数据的融合分析对于提取更全面、准确的信息和实现更高级的数据处理任务至关重要。然而,多模态数据融合面临着一系列挑战,如数据异构性、特征融合、数据不平衡、语义对齐以及可解释性等问题。
2、传统的风险评估目标分类模型主要依赖于传统指标信息和影像学数据,如年龄、性别、心功能、主动脉瓣的解剖特征此类的传统信息等。然而,这些传统模型的预测能力受到限制,难以充分利用多模态数据之间的互补信息提高目标的分类预测性能。随着深度学习技术的快速发展,基于深度神经网络的目标分类预测模型逐渐成为一种新的研究方向。深度学习模型具有强大的学习能力和自适应性,能够从大规模的数据中自动学习和提取特征,并建立复杂的非线性关系,从而提供更准确的预测结果。
3、在复杂目标分类预测领域,多模态数据的使用具有显著的优势。传统上,统计信息数据和影像数据被独立地应用于分类预测和诊断。然而,这两种数据源各自具有一些局限性,限制了其在目标分类中的准确性和可靠性。因此,采用多模态数据的综合分析已成为一种有前景的方法,可以克服这些局限性,提高分类的准确性和效能。通过结合统计信息数据和影像数据,可以获得更全面、准确的特征,提高预测模型的准确性和敏感性。同时,多模态数据的融合还可以提高模型的鲁棒性和稳定性,为目标分类预测提供更可靠的支持。因此,采用多模态数据融合的方法在多种复杂分类预测领域具有广阔的应用前景和商业价值。
技术实现思路
1、本发明的目的在于提供一种克服上述问题或者至少部分地解决上述问题的技术方案。提出了一种创新的多模态数据融合方法,该方法结合了特征对齐和基于注意力机制的特征融合。特征对齐旨在将不同模态的特征映射到一个共享的表示空间中,以实现模态间的语义对齐。通过特征对齐,不同模态的数据可以在语义层面上进行比较和融合,从而充分利用多模态数据的信息。而基于注意力机制的特征融合能够自动学习不同模态数据的重要性权重,并将这些权重应用于特征的融合过程中。通过注意力机制,能够灵活地处理模态间的不平衡和异构性,以及提高融合后特征的表达能力和鲁棒性。
2、本发明是采用以下技术手段实现的:
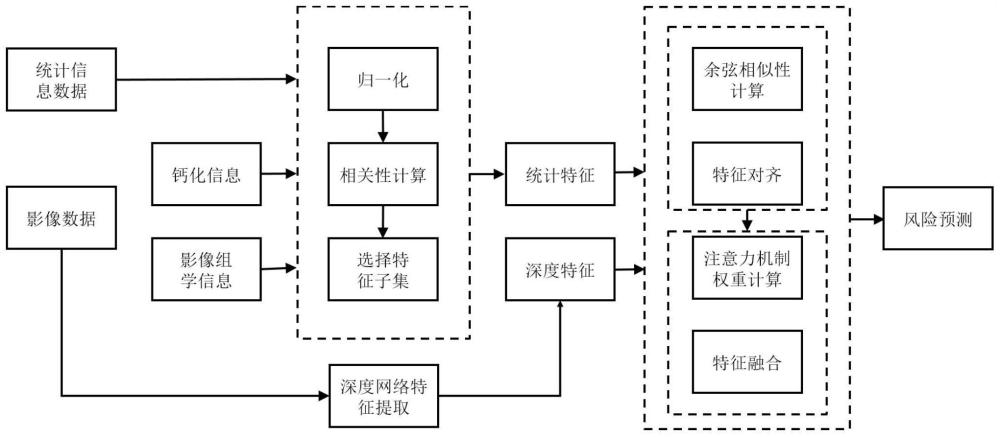
3、一种统计信息数据与影像数据的模态特征对齐融合的方法,应用于目标分类预测。该方法整体分为4个阶段:统计信息特征选择阶段、影像深度特征提取阶段、多模态特征对齐阶段和模态间交叉注意力机制的多模态数据融合进行目标分类预测阶段。整体流程图如附图1所示。
4、该方法具体包括以下步骤:
5、1)统计信息特征选择阶段:
6、本发明对统计信息特征采用相关特征选择(cfs),通过综合考虑特征与目标变量之间的相关性和特征之间的冗余性,选择与目标变量高度相关且具有较低冗余的特征子集,假设理想的鉴别特征子集包含与分类高度相关的特征,特征间不相关。这样可以在保留鉴别信息的同时减少特征维度,提高分类的性能和模型的可解释性。附图2所示为统计信息特征选取阶段的整体流程。具体步骤如下。
7、第一步,计算特征与目标变量之间的相关性,对于给定的特征集合,计算每个特征与目标变量之间的相关性。使用pearson相关系数度量特征与目标变量之间的线性相关程度。首先,确定两个变量的数据集,对于两个变量x和y,它们的数据集分别为x={x1,x2,...,xn}和y={y1,y2,...,yn},其中n是数据点的数量,对数据进行归一化后,分别计算x和y的平均值,记为meanx和meany;然后,计算每个数据点与对应变量的平均值的差值,对于每个数据点i,计算xi-meanx和yi-meany的差值;接下来,计算差值的乘积,对于每个数据点i,将得到的差值相乘,得到(xi-meanx)*(yi-meany)。最后根据pearson相关系数的计算公式(公式1),得到系数值,记为rcf;
8、
9、第二步,计算特征之间的相关性。通过计算特征之间的pearson相关系数,以评估它们之间的冗余程度,记为rff;
10、第三步,计算子集的评估度量,对于给定的特征子集,通过启发式方程进行度量,启发式方程如公式2所示;
11、
12、其中,merit为k个特征子集的度量结果,k为子集特征的个数,rcf为特征与类之间的平均相关系数,即特征与类别之间的相关性,rff为特征与特征之间的平均相关系数,即特征间冗余程度;
13、第四步,选择统计特征子集,通过最佳优先搜索算法在特征子集空间中寻找最佳子集,最佳子集为计算的启发式方程数值最大值所对应的特征,搜索算法通过在每一步选择最优的特征进行迭代地构建统计特征子集;
14、2)影像深度特征提取阶段:
15、第一步,通过编码器对ct影像中的深度特征进行提取。本发明选取的特征提取网络模型为efficientnet。efficientnet网络是通过网络结构搜索技术搜索网络的图像输入分辨率、网络深度以及通道宽度3个参数,得到efficientnet-b0~b7网络结构。通过增加网络宽度,卷积核的个数,即增加特征矩阵的通道数,或者增加输入网络的分辨率,能够获得更高细粒度的特征,更容易进行网络训练。增加网络深度,可以得到更加丰富、复杂的特征,但是会面临梯度消失,训练困难的问题。网络中采用mbconv模块进行下采样操作。mbconv结构包括:1个1×1的卷积(包含bn层和swish激活层),用于提高维度;1个3×3的深度卷积(包含bn层和swish激活层);1个se模块,由1个全局平均池化,2个全连接层组成;1个1×1的卷积(包含bn层和线性激活层),用于降低维度;最后连接1个dropout层。本发明选用的数据大小为128×128×60,选取输入图像分辨率较小且参数量最少的efficientnet-b0作为训练网络。efficientnet-b0网络的width,depth,resolution,dropout参数为(1.0,1.0,128,0.2)。网络由9个stage组成,stage1是3x3的卷积;stage2-8为重复堆叠mbconv块,重复次数为1、2、2、3、3、4、1,卷积核大小为3、3、5、3、5、5、3;stage9由1x1卷积、平均池化层和全连接层三部分组成。stage1-8的stride为2、1、2、2、2、1、2、1。
16、第二步,深度特征降维。本阶段采用的efficientnet-b0网络去掉分类器层将得到1280维深度特征,为了进行特征对齐将通过神经网络中的隐藏层将其降维到与cfs特征选择后的统计特征子集相同的维度,从而进行对齐相关计算。
17、3)基于余弦相似性的多模态数据的特征对齐阶段:
18、第一步,特征提取。对于每个模态的数据,进行特征提取,将其转换成适合余弦相似性计算的向量表示。针对图像数据,采用第二阶段提取到的深度特征;对于统计数据,采用第一阶段选择的统计特征子集作为特征;
19、第二步,特征归一化。对于每个模态的特征向量,进行归一化操作,将其转换为单位向量。这样可以消除向量长度对余弦相似性的影响,使得相似性度量更加准确和可比较。
20、第三步,余弦相似性计算。对于两个不同模态的特征向量(向量a以及向量b),利用余弦相似性公式计算它们之间的相似度。余弦相似性可以通过计算两个向量的内积除以它们的范数来得到。如公式3所示:
21、
22、其中,a·b表示向量a和向量b的内积(即对应元素相乘后求和),||a||表示向量a的范数(即向量a的长度)。
23、第四步,特征对齐。根据计算得到的余弦相似性,选择相似度最高的特征对进行对齐,将它们映射到同一个表示空间中。特征对齐通过线性变换、投影来实现。
24、4)多模态数据融合阶段:
25、第一步,特征提取。该阶段特征提取与第三阶段相同。
26、第二步,注意力权重计算。a.特征映射:将两个模态数据的特征表示分别表示为f(对于模态1)和g(对于模态2)。b.通过分别对f和g进行线性变换得到q、k、v。线性变换通过矩阵乘法来实现,得到q=wqf、k=wkg、v=wvg,其中wq、wk和wv是权重矩阵,它们通过反向传播算法和训练数据来进行学习和更新。c.相似度计算:计算查询q和键k之间的相似度得分,通常使用点积方法来度量特征表示之间的相关性,得到相似度矩阵。d.注意力权重计算:将相似度矩阵的每一行(或每一列)应用于softmax函数,获得注意力权重,确保注意力权重在0到1的范围内,并且所有权重的总和为1。
27、第三步,特征融合。将注意力权重与另一个模态数据的特征表示进行加权融合。通过将注意力权重乘以特征表示的每个元素,然后对结果进行求和,得到最终的融合特征表示。
28、第四步,模态特征更新。将融合后的特征作为新的模态数据特征,并通过网络的反向传播进行特征更新,添加线性层以及softmax函数用于最终分类预测任务的执行。
29、本发明与现有技术相比,具有以下明显的优势和有益效果:
30、本发明提出了一种统计信息数据与影像数据的模态特征对齐融合的方法,用于目标分类预测。通过cfs特征选择方式结合最佳优先搜索算法选择出与疾病预测结果最相关的特征子集。通过引入了多模态交叉注意力机制,用于自动学习和融合不同模态数据之间的相关性。在这种机制中,不同模态的特征通过交叉注意力机制进行交互,使得模型能够更加关注重要的特征,并减少对无关特征的关注。这种注意力机制可以帮助我们识别和强调与疾病风险密切相关的特征,从而提高风险预测模型的性能和准确性。在我本发明所提出的模型中,深度神经网络将通过多层次的卷积和池化操作,自动学习来自不同数据模态的高级抽象特征。然后,多模态交叉注意力机制将被引入,用于自动学习和调整不同模态数据之间的权重,以更好地关注与疾病风险相关的特征。通过这种方式,该模型能够综合考虑来自不同数据模态的信息,并提供更准确的风险预测结果。
31、本发明的特点:
32、1.多模态数据融合:本发明提出了一种创新的多模态数据融合方法,通过特征对齐和基于注意力机制的特征融合,充分利用不同模态数据的信息。特征对齐实现了模态间的语义对齐,而注意力机制自动学习不同模态数据的重要性权重,优化特征的融合过程;
33、2.特征融合和特征加权:通过特征对齐和融合,本发明能够在语义层面上比较和融合不同模态的特征,克服模态间的不平衡和异构性。同时,基于注意力机制的特征加权使得模型更关注与疾病风险密切相关的特征,提高风险预测的准确性和鲁棒性。
34、3.综合考虑多模态信息:本发明综合考虑来自不同数据模态的信息,通过深度神经网络学习高级抽象特征,并利用多模态交叉注意力机制调整不同模态数据之间的权重。这种综合考虑能够更好地关注与分类更加相关的特征,提供更准确的预测结果。
- 还没有人留言评论。精彩留言会获得点赞!