一种文档处理方法、装置及设备与流程
本发明涉及大数据处理与人工智能,尤其涉及一种文档处理方法、装置及设备。
背景技术:
1、在人们日常工作中,富文本的图像文档随处可见,例如各种数字海报、电子发票、电子版的简历、电子报表、扫描文件、ppt格式的pdf文档等。这些文档除了包含文本信息外,往往也包含丰富的结构信息和视觉信息,例如字体的颜色和大小、文本的位置、表格的结构、图表数据以及图像信息等。传统的文档问答方法是将文档的内容进行光学符号识别,提取出文档的文本内容然后利用大语言模型完成基于文本问答任务。传统的基于光学符号识别的视觉文档问答,只是利用了文档中文本信息,从而导致基于光学符号识别的视觉文档问答方法性能不佳。
技术实现思路
1、本发明实施例提供一种文档处理方法、装置及设备,解决现有技术中基于光学符号识别的视觉文档问答方法性能不佳的问题。
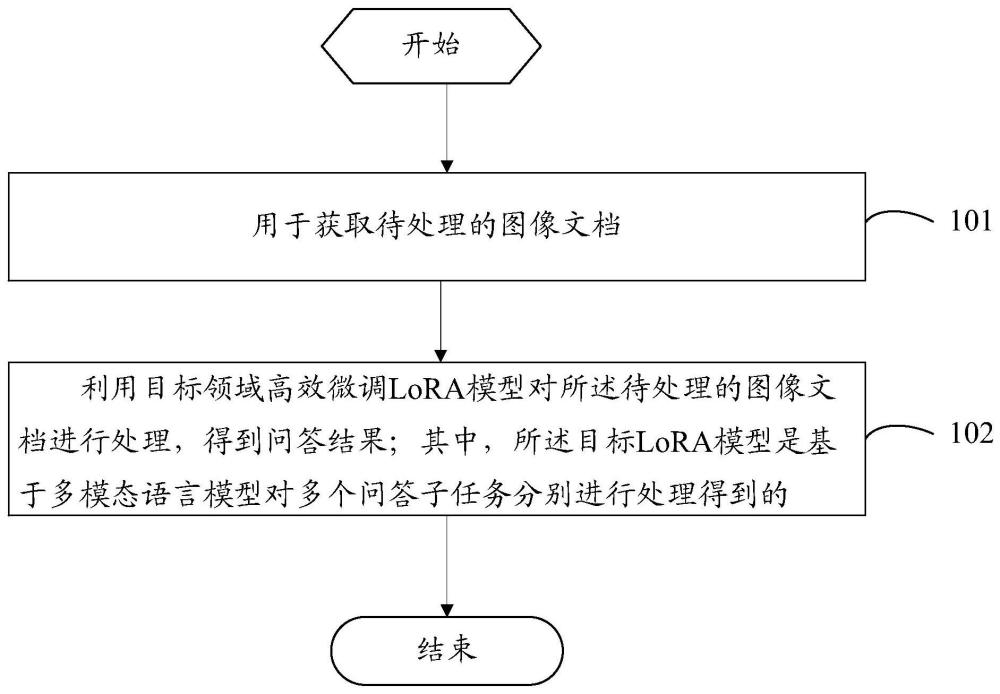
2、为解决上述技术问题,本发明提供一种文档处理方法,所述方法包括:
3、获取待处理的图像文档;
4、利用目标领域高效微调lora模型对所述待处理的图像文档进行处理,得到问答结果;
5、其中,所述目标lora模型是基于多模态语言模型对多个问答子任务分别进行处理得到的。
6、可选地,在获取待处理的图像文档之前,所述方法包括:
7、获取目标图像文档;
8、基于所述目标图像文档获取不同问答子任务对应的训练数据集;
9、利用多模态语言模型对所述不同问答子任务分别进行领域高效微调lora,得到与所述不同问答子任务分别对应的多个目标子lora;
10、基于所述不同问答子任务对应的训练数据集以及所述多个目标子lora生成所述目标lora模型。
11、可选地,所述基于所述目标图像文档获取不同问答子任务对应的训练数据集包括:
12、利用布局解析模型对所述目标图像文档进行解析,得到表格图像、文本图像和图表图像;
13、基于所述表格图像、所述文本图像和所述图表图像分别生成图像表格问答任务的训练数据集、图像文字问答任务的训练数据集以及图像图表问答任务的训练数据集。
14、可选地,基于所述表格图像生成图像表格问答任务的训练数据集包括:
15、利用表格光学字符模型识别所述表格图像的表格数据;
16、利用大语言模型对所述表格数据进行处理,生成表格问题和答案;
17、基于所述表格问题和答案以及所述表格图像构建所述图像表格问答任务的训练数据集。
18、可选地,基于所述文本图像生成图像文字问答任务的训练数据集包括:
19、利用光学字符模型识别所述文本图像的文本;
20、利用大语言模型对所述文本进行处理,生成文本问题和答案;
21、基于所述文本问题和答案以及所述文本图像构建所述图像文字问答任务的训练数据集。
22、可选地,基于所述图表图像生成图像图表问答任务的训练数据集包括:
23、利用图生文模型对所述图表图像进行处理,得到所述图表图像的描述;
24、利用大语言模型对所述图表图像的描述进行处理,生成所述图表图像的描述的问题和答案;
25、基于所述图表图像的描述的问题和答案以及所述图表图像构建所述图像图表问答任务的训练数据集。
26、可选地,所述利用多模态语言模型对不同问答子任务分别进行领域高效微调lora,得到与所述不同问答子任务分别对应的多个目标子lora包括:
27、利用多模态语言模型分别在所述图像表格问答任务的训练数据集、图像文字问答任务的训练数据集以及图像图表问答任务的训练数据集上进行lora微调,得到所述图像表格问答任务对应的第一目标子lora、所述图像文字问答任务对应的第二目标子lora以及所述图像图表问答任务对应的第三目标子lora。
28、可选地,所述基于所述不同问答子任务对应的训练数据集以及所述多个目标子lora生成目标lora模型包括:
29、使用softmax算法对所述图像表格问答任务的训练数据集、图像文字问答任务的训练数据集、图像图表问答任务的训练数据集、所述第一目标子lora、所述第二目标子lora、所述第三目标子lora进行融合处理,得到目标lora模型。
30、第二方面,本发明实施例还提供一种文档处理装置,所述装置包括:
31、第一获取模块,用于获取待处理的图像文档;
32、第一处理模块,用于利用目标领域高效微调lora模型对所述待处理的图像文档进行处理,得到问答结果;
33、其中,所述目标lora模型是基于多模态语言模型对多个问答子任务分别进行处理得到的。
34、可选地,所述装置还包括:
35、第二获取模块,用于获取目标图像文档;
36、第三获取模块,用于基于所述目标图像文档获取不同问答子任务对应的训练数据集;
37、第二处理模块,用于利用多模态语言模型对所述不同问答子任务分别进行领域高效微调lora,得到与所述不同问答子任务分别对应的多个目标子lora;
38、生成模块,用于基于所述不同问答子任务对应的训练数据集以及所述多个目标子lora生成所述目标lora模型。
39、可选地,第三获取模块包括:
40、解析子模块,用于利用布局解析模型对所述目标图像文档进行解析,得到表格图像、文本图像和图表图像;
41、生成子模块,用于基于所述表格图像、所述文本图像和所述图表图像分别生成图像表格问答任务的训练数据集、图像文字问答任务的训练数据集以及图像图表问答任务的训练数据集。
42、可选地,所述生成子模块还用于:
43、利用表格光学字符模型识别所述表格图像的表格数据;
44、利用大语言模型对所述表格数据进行处理,生成表格问题和答案;
45、基于所述表格问题和答案以及所述表格图像构建所述图像表格问答任务的训练数据集。
46、可选地,所述生成子模块还用于:
47、利用光学字符模型识别所述文本图像的文本;
48、利用大语言模型对所述文本进行处理,生成文本问题和答案;
49、基于所述文本问题和答案以及所述文本图像构建所述图像文字问答任务的训练数据集。
50、可选地,所述生成子模块还用于:
51、利用图生文模型对所述图表图像进行处理,得到所述图表图像的描述;
52、利用大语言模型对所述图表图像的描述进行处理,生成所述图表图像的描述的问题和答案;
53、基于所述图表图像的描述的问题和答案以及所述图表图像构建所述图像图表问答任务的训练数据集。
54、可选地,所述第二处理模块具体用于:
55、利用多模态语言模型分别在所述图像表格问答任务的训练数据集、图像文字问答任务的训练数据集以及图像图表问答任务的训练数据集上进行lora微调,得到所述图像表格问答任务对应的第一目标子lora、所述图像文字问答任务对应的第二目标子lora以及所述图像图表问答任务对应的第三目标子lora。
56、可选地,所述生成模块具体用用于:
57、使用softmax算法对所述图像表格问答任务的训练数据集、图像文字问答任务的训练数据集、图像图表问答任务的训练数据集、所述第一目标子lora、所述第二目标子lora、所述第三目标子lora进行融合处理,得到目标lora模型。
58、第三方面,本发明实施例还提供一种电子设备,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的程序;所述处理器,用于读取存储器中的程序实现如第一方面所述的文档处理方法中的步骤。
59、第四方面,本发明实施例还提供一种可读存储介质,用于存储程序,所述程序被处理器执行时实现如第一方面所述的文档处理方法中的步骤。
60、第五方面,本发明实施例还提供一种计算机程序产品,包括计算机指令,该计算机指令被处理器执行时实现如第一方面所述的文档处理方法中的步骤。
61、本发明实施例利用基于多模态语言模型对多个问答子任务分别进行处理得到的lora模型对图像文档进行处理,既保留了通用多模态语言模型的基本能力,同时提升了通用多模态语言模型在不同子任务上的性能,且提升了视觉文档问答方法的性能。
- 还没有人留言评论。精彩留言会获得点赞!