一种加权融合文本分类方法及装置与流程
本发明涉及文本分类领域,具体提供一种加权融合文本分类方法及装置。
背景技术:
1、文本分类指:用计算机对文本(或其他实体)按照一定的分类体系或标准进行自动分类标记,并伴随着信息的爆炸式增长,人工标注数据已经变得耗时、质量低下,且受到标注人主观意识的影响。因此,利用机器自动化的实现对文本的标注变得具有现实意义,将重复且枯燥的文本标注任务交由计算机进行处理能够有效克服以上问题,同时所标注的数据具有一致性、高质量等特点。其应用场景众多,包括:情感分析、文本分类、问答任务、意图识别、自然语言处理等。
2、本文主要对新闻文本分类技术,输入一段文本,对该段文字进行文本分类,以判断该文本属于财经、科技、体育、法律、历史、游戏、音乐、影视等类别。在新闻分发、新闻存储、新闻检索等领域具有重要的应用价值。
3、对文本“2023年2月16日,斯诺克威尔士公开赛继续进行,16强决出八席,塞尔比、吉尔伯特、乔.佩里三大名将爆冷输球,临场发挥不如预期,尤其是排名第2位的塞尔比,没能发挥最佳水平,中国小将再创佳绩,两位00后球员庞俊旭、袁思俊双双晋级,届时表现如何值得期待。”,进行文本分类解析,结果是体育类别。
4、常用的文本分类方法包括:tf-idf模型、nb模型、随机森林等机器学习模型,line模型,fasttext、textrnn、textcnn、bert等深度学习模型。每类方法结合具体实现策略演化为多种实现方案,例如序列标注法包括bi-lstm、bi-lstm-attention等实现方案。采用相同实现方案训练不同的数据集,所得到的模型具有不同的偏好,它们在具有不同分布特征的数据集上存在性能差异,从而限制了文本分类模型的适用范围。
5、集成学习(ensemble learning)训练并融合多个模型,从而消除模型偏好所带来的性能分布不均衡,扩大模型的适用范围。其核心思想是即使某个模型预测错误,其它模型也能将错误纠正过来。因此,在文本分类中,通过集成学习来融合不同模型,可以得到性能分布均衡的文本分类模型,具有较好的普适性。
6、采用集成学习法融合不同文本分类模型时,需要将不同模型输出的多个分值融合为一个分值,常用方法是加权融合,如何设置合适的融合权重是模型融合的关键因素。准确率和召回率、精确率等都可以作为模型融合权重的参考,当单一因素作为模型的参考显得不够全面,f1值融合准确率和召回率,可以更加科学、全面地度量模型质量。
技术实现思路
1、本发明是针对上述现有技术的不足,提供一种实用性强的加权融合文本分类方法。
2、本发明进一步的技术任务是提供一种设计合理,安全适用的加权融合文本分类装置。
3、本发明解决其技术问题所采用的技术方案是:
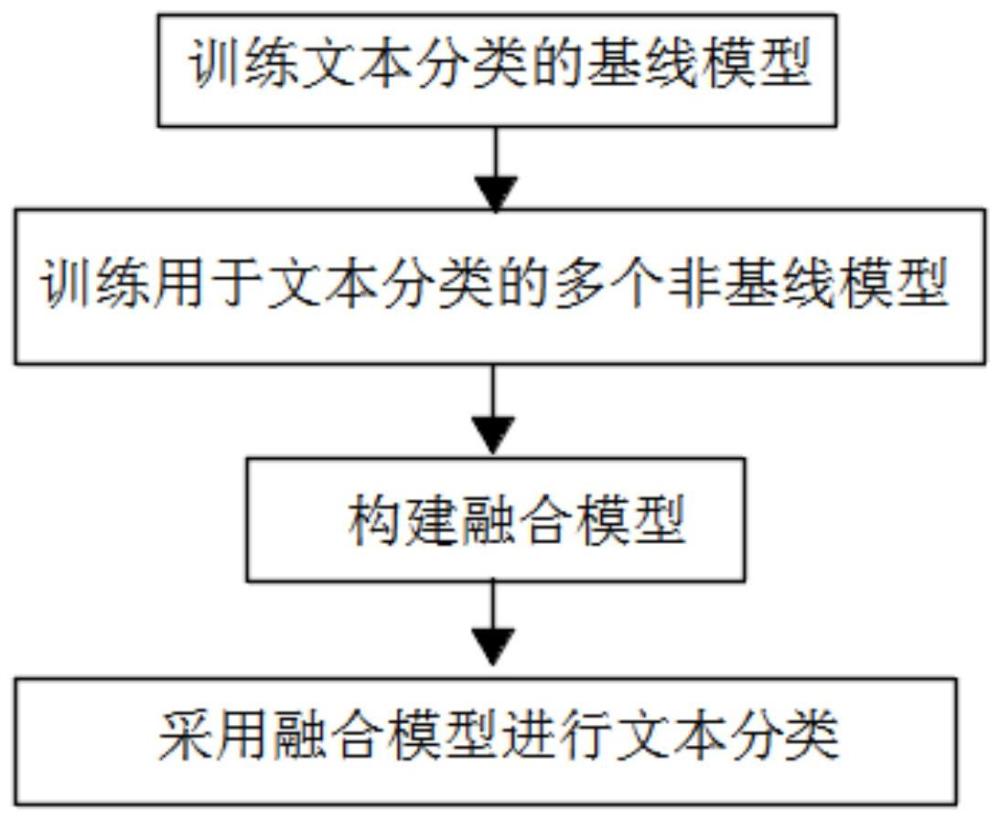
4、一种加权融合文本分类方法,具有如下步骤:
5、s1、训练文本分类的基线模型;
6、s2、训练用于文本分类的多个非基线模型;
7、s3、构建融合模型;
8、s4、采用融合模型进行文本分类。
9、进一步的,在步骤s1中,在训练dtrain上训练适用于文本分类的基线模型;
10、在步骤s2中,在训练集dtrain上训练适用于文本分类的多个非基线模型。
11、进一步的,在步骤s3中,集成多个文本分类的非基线模型,将不同模型在文本分类上的多个分值融合为单个分值;
12、用modelbase表示基线模型,其f1值为f1base,用model1、model2、…、modeli…、modeln表示n个待融合的非基线模型,其f1值分别为f1、f2、…、fi…、fn,1≤i≤n,用modelmerge表示融合模型,用dtrain和ddev表示文本分类训练集和验证集;
13、用tag1、tag2、…、tagj…、tagm表示ddev中的m类分类标签,1≤j≤m。
14、进一步的,在步骤s3中,进一步的包括:
15、s31、计算文本分类基线模型的f1值;
16、s32、计算多个待文本分类模型分类的f1值;
17、s33、计算待融合文本分类解析模型的权重;
18、s34、融合不同文本分类模型输出的分值;
19、s35、返回融合模型。
20、进一步的,在步骤s31中,在验证集ddev上计算基线模型的micro-f1值,用ybase,j表示modelbase所预测的第j类分类标签的个数,用zbase,j表示modelbase预测正确的第j类分类标签的个数,用pbase和rbase表示modelbase在ddev上的准确率和召回率,据此计算modelbase的micro-f1值,则有:
21、
22、进一步的,在步骤s32中,在验证集ddev上计算多个待融合模型的micro-f1值,用yi,j表示modeli所预测的第j类分类标签的个数,用zi,j表示modeli预测正确的第j类分类标签的个数,用pi和ri表示modeli在ddev上的准确率和召回率,1≤i≤n,据此计算modeli的micro-f1值,则有:
23、
24、进一步的,在步骤s33中,计算待融合模型在集成时的权重,用δf1i,base表示模型modeli和modelbase的f1值差异,用αi表示模型modeli在集成时的权重,1≤i≤n,则有:
25、
26、δf1i,base=f1i-f1base。
27、进一步的,在步骤s34中,根据待融合模型在集成时的权重αi来融合不同模型输出的分值,得到融合模型modelmerge,用si,j表示modeli在文本分类标签上的分值,用smerge,j表示modelmerge在分类标签tagj上的融合分值,1≤i≤n,1≤j≤m,则有:
28、
29、进一步的,在步骤s4中,使用融合模型modelmerge进行文本分类,用w表示待进分类,用smerge,j(w)表示modelmerge解析w时在文本分类标签tagj上的融合分值,用nmerge(w)表示modelmerge解析w时输出的分类标签编号,1≤j≤m,则有:
30、
31、根据w对应的分类标签,就可以确定其文本分类的类型。
32、一种加权融合文本分类装置,包括:至少一个存储器和至少一个处理器;
33、所述至少一个存储器,用于存储机器可读程序;
34、所述至少一个处理器,用于调用所述机器可读程序,执行一种加权融合文本分类方法。
35、本发明的一种加权融合文本分类方法及装置和现有技术相比,具有以下突出的有益效果:
36、本发明引入文本分类基线模型,根据不同文本分类模型和基线模型的f1值差异来计算融合权重,用于融合不同模型输出的分值,解决了仅根据准确率或者、召回率等单一评估参数计算文本分类模型的融合权重不全面、无法体现融合时模型质量的差异等问题,提高了文本分类的效果。
- 还没有人留言评论。精彩留言会获得点赞!