联邦学习中边缘计算节点的动态子图优化方法
本发明属于联邦学习,尤其是联邦学习中边缘计算节点的动态子图优化方法。
背景技术:
1、在联邦学习(federated learning,fl)的技术领域中,数据在边缘机器上存在设备异构性(设备之间的资源差异)和数据异构性(设备之间的训练数据分布不均匀)等因素;这直接导致了聚合效率下降以及资源利用率低的问题。
2、对于上述存在的不足,现有技术大多从调度侧去处理,例如:使用节点选择机制,选择合适的客户端参与训练;比如:reisizadeh等人则提出了一种只选择部分客户端进行模型训练的方法,并使用低精度量化来压缩上传的模型参数;使用梯度更新策略处理异步训练中的过期梯度问题。
3、上述方式虽然能够得到一定程度的效率提高,但是这些方式都只是从调度侧去处理;即,上述方式在选择更加合适的机器或者为了在机器更新时有更好的效果,对于一台机器本身来说,都没有方案关注在联邦学习的边缘计算场景下,在计算侧让机器本身根据不同设备异构性以及数据异构性,来进行单机的训练效率提升。
4、通过设计基于性能感知的计算侧模型训练动态优化方案,能够在数据异构性和设备异构性上,得到优于现有技术的效率提高,即能够更好的实现聚合效率的提升以及充分的资源利用率。
技术实现思路
1、为了解决上述技术问题,本发明提供一种联邦学习中边缘计算节点的动态子图优化方法,突破性的从计算侧进行优化,通过训练计算时动态调整训练图的方法,收集此节点的设备性能以及训练数据分布概率;同时通过分别区分cpu、gpu等多种异构资源,针对embedding训练子图的消耗进行预期建模,从而最终获得预期最优的计算图训练流程。
2、联邦学习中边缘计算节点的动态子图优化方法,包括:
3、步骤一、启动边缘训练节点:在边缘计算环境中,启动边缘训练节点;
4、作为一种举例说明,所述边缘训练节点包括:物联网设备、智能手机和/或平板电脑等,它们将参与联邦学习的训练过程。
5、步骤二、收集相关数据:在训练开始前以及训练后的前一段时间,边缘训练节点会收集本地的设备异构性和数据异构性的相关数据,这些相关数据用于训练过程中的embedding子图的优化;
6、作为一种举例说明,所述相关数据包括:各种feature数据概率分布、训练中的超参数以及计算芯片种类等等。
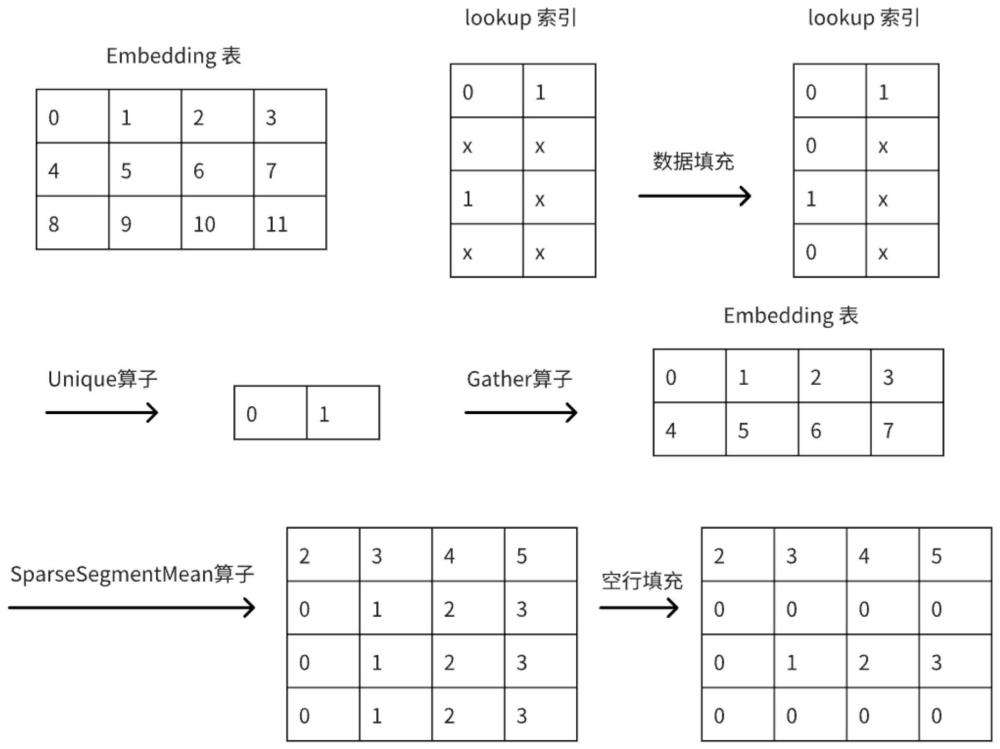
7、作为一种举例说明,所述embedding是目前在各个领域模型中常用的方法之一,也是在工业级训练中消耗不小的计算流;在联邦学习中,针对多样的异构机器群,通过测试不同的计算单元的性能以及数据分布概率赋予不同的计算图,以此获得计算侧辅助来加速我们的训练;embedding子图指:特征变换成embedding索引并拼接成embedding向量的过程,以经典的流程为例,我们可以将整体流程简化为图1所示。
8、步骤三、进行计算侧的优化,包括:
9、①算子识别与分析:在训练开始后,算法首先识别embedding子图中的关键算子;
10、作为一种举例说明,所述关键算子包括:sparsesegmentmean、gather和unique算子;这三个算子是embedding向量生成过程中的核心组成部分,对整体计算效率有显著的影响。
11、②在到达训练中期时,进行建模预估;
12、将前期获得的所有的所述相关数据以及获得的算子的平均消耗,带入下列预估函数中并反解方程得出各个变量的值;
13、其中:tu、tg、ts分别指代unique、gather和sparsesegmentmean三个算子建模后预估的时间消耗;launchu、launchg、launchs分别指代三个算子在被调用前的消耗;xu、xg、xs分别代表三个算子与实际机器有关的权重超参数,需要前期收集过程中进行拟合;dim指训练时的embedding dim大小,是超参数;
14、进一步的,所述sparsesegmentmean算子的预估最为特殊,其建模需要考虑缓存的问题,采用传统的二八概率模型作为标准,假设平均不同的类别(unique)有n个,每个的概率分别为p(i),ec就是被缓存的概率有几次,tc和tm分别表示在数据访问工作中被缓存的时间耗时和没被缓存的时间耗时;batch是数据训练的每轮多少,是超参数;unique表示这个计算节点上的获得数据属性中的unique属性(即每轮数据有多少不一样的数据的比率期望)。
15、tu=launchu+xu*batch (1)
16、tg=launchg+xg*dim*unique(batch) (2)
17、ec=(n-1)*∑i∈sp(i)2 (3)
18、ts=launchs+tc*ec+tm*(unique(batch)-ec)+xs*unique(batch)*dim (4)
19、t=tu+tg+ts (5)
20、③unique算子展开;
21、根据边缘训练节点的设备异构性来判断计算资源的种类;
22、作为一种举例说明,当采用的是gpu类型的计算资源时,在全部的场景下直接舍弃unique算子。
23、作为一种举例说明,当采用的是cpu类型的计算资源的时候,通过前一步相关的建模数据来获取优化后的预估时间消耗,然后根据现在的时间消耗进行比较做出决定;即假设现在的时间消耗可以视为t:
24、tep1:假设去除unique算子后的预估时间消耗为:t°=tg+ts;此时tg与ts的预估的几个变量值需要进行改变,因为unique算子的取消而导致的需要重复处理的数据数量的增加,而数据数量增加的多少取决于各个训练节点所获得的数据异构性;
25、作为一种举例说明,通过前期的测试来获取此节点的数据性质;包括此时需要获得的unique性质的大小(某组数据一轮下来重复的多少)。
26、tep2:通过t与t°的时间消耗进行对比,了解是否应该进行优化;这涉及到对优化前后的性能进行评估,以确定去除unique算子是否会带来实际的性能提升;
27、tep3:假设不需要去除unique算子,在原生的一些方案实现中,cpu的情况下是使用hash map的机制实现的,这时使用数据异构中的每个节点的unique性质,从而预先在hash map中分配合理的空间大小以避免哈希碰撞和空间浪费。(当然gpu的情况下我们直接不使用此算子)。
28、tep4:如果需要去除unique算子,且现在是在gpu类型计算资源的使用情况下,可对sparsesegmentmean算子进行优化,没有使用unique算子的情况下,可以默认为从0开始到结束,以获取更好的内存访问优化。
29、作为一种举例说明,当需要unique算子的情况下,需要传入unique idx来表示处理后的位置。
30、步骤四、评估与持续迭代:针对决定的优化embedding子图进行动态的更改,对优化前后的性能进行对比,评估优化效果是否有额外误差,同时根据实验结果和实际应用中的反馈,不断调整和完善优化建模模型,以进一步提高评估能力;
31、作为一种举例说明,本发明对期望优化能力结果做出实验检测,实验测试情况下,在gpu的计算节点中,能够获得40%左右的性能提升;在cpu的计算节点中,能够获得20%左右的性能提升。
32、本发明的有益效果:
33、本发明通过对于联邦学习中边缘节点的数据收集以及计算设备能力的检测,实现在训练中进行动态的子图优化,针对于不同类型的边缘节点,分别提供动态运行时不同的训练子图,实现性能的充分利用,以及提供对于以后多异构场景的适配方案。
34、本发明在以下两个方面提供了优化,根据边缘计算时的特点而提升单机训练性能:
35、针对数据异构性:方案通过在训练时的数据分布信息的收集,针对不同的数据分布类型设计不同的建模最适合的训练图;
36、针对设备异构性:方案通过在训练时的设备计算能力/计算芯片种类等信息的收集,针对不同的计算单元建模最适合的训练图;
37、最终会从计算侧在这两方面进行突破,解决训练中设备性能利用率不高,异构场景下优化复杂等问题。
38、本发明将主要的算子提取出来并建模,在训练启动前后先进行一段时间的数据收集,以此得到可以预估耗时的相关数据的期望,并进行算子耗时建模。我们会通过不同的数据样本更改unique的适用与否,以及提供sparsesegmentmean算子的访存优化方式等方法。
- 还没有人留言评论。精彩留言会获得点赞!