视频生成方法、装置及设备与流程
本技术涉及人工智能,更具体地说,涉及一种视频生成方法、装置及设备。
背景技术:
1、在人工智能领域,ai视频的生成属于当下的热点技术。现有技术中通过扩散模型基于原视频每一帧图片的提示词和图片特征生成新的一帧一帧的图片,最后将这些图片组合成ai视频。
2、但由于扩散模型生成的图片随机性较大,导致ai视频的连贯性较差,视频质量较差。
技术实现思路
1、有鉴于此,本技术提供了一种视频生成方法、装置及设备,用于解决现有技术中生成的视频连贯性较差的缺点。
2、为了实现上述目的,现提出的方案如下:
3、一种视频生成方法,包括:
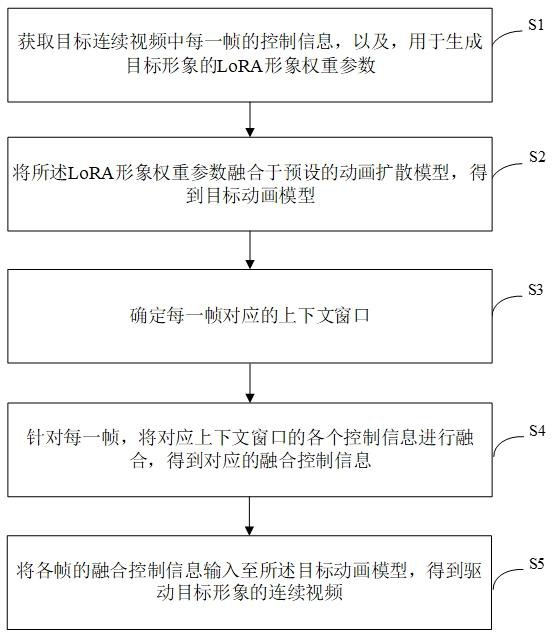
4、获取目标连续视频中每一帧的控制信息,以及,用于生成目标形象的lora形象权重参数;
5、将所述lora形象权重参数融合于预设的动画扩散模型,得到目标动画模型;
6、确定每一帧对应的上下文窗口,每个上下文窗口中包含对应的当前帧以及环绕所述当前帧的若干帧;
7、针对每一帧,将对应上下文窗口的各个控制信息进行融合,得到对应的融合控制信息;
8、将各帧的融合控制信息输入至所述目标动画模型,得到驱动目标形象的连续视频。
9、可选的,获取用于生成目标形象的lora形象权重参数,包括:
10、获取指定主体的脸部lora权重参数,所述脸部lora权重参数用于绘制指定主体的脸部;
11、获取指定造型的造型lora权重参数以及面部lora权重参数,所述造型lora权重参数用于绘制搭配有指定造型的主体,所述面部lora权重参数用于绘制搭配有指定造型主体的脸部;
12、计算所述造型lora权重参数与所述面部lora权重参数间的权重参数差值;
13、将所述权重参数差值与所述脸部lora权重参数整合,整合后得到lora形象权重参数,所述目标形象为搭配有指定造型的指定主体。
14、可选的,所述获取指定主体的脸部lora权重参数,包括:
15、获取包含指定主体脸部的多个主体图像;
16、提取每个主体图像的脸部描述文本以及主体脸部蒙版;
17、利用每个主体图像的脸部描述文本以及主体脸部蒙版,对潜在扩散模型的lora层级进行训练,所述脸部lora权重参数为训练后lora层级的权重参数。
18、可选的,所述利用每个主体图像的脸部描述文本以及主体脸部蒙版,对潜在扩散模型的lora层级进行训练,包括:
19、针对每个主体图像,在前向扩散阶段,向所述潜在扩散模型输入添加有真实噪声的输入图像,所述输入图像基于所述主体图像得到;利用所述潜在扩散模型基于所述主体图像的脸部描述文本及上一阶段的预测结果,预测当前阶段添加的随机噪声,并利用预测的所述随机噪声,对上一阶段的预测结果进行去噪,形成当前阶段的预测结果;在反向传播阶段,基于主体脸部蒙版内部区域的随机噪声,以及,主体脸部蒙版内部区域的真实噪声,计算损失值;基于所述损失值,对所述潜在扩散模型lora层级的权重参数进行更新。
20、可选的,基于主体脸部蒙版内部区域的随机噪声,以及,主体脸部蒙版内部区域的真实噪声,计算损失值,包括:
21、利用预先设置的损失值计算函数,计算得到所述损失值;
22、损失值计算函数如下所示:
23、;
24、其中,h为预测结果所对应的高;w为预测结果所对应的宽; predij为第i行第j列的随机噪声值;gtij为第i行第j列的真实噪声值;maskij为主体脸部蒙版第i行第j列所对应的特征值。
25、可选的,所述将对应上下文窗口的各个控制信息进行融合,得到对应的融合控制信息,包括:
26、基于正态分布,控制所述上下文窗口中各帧所对应的权重,所述上下文窗口的当前帧的权重为最大;
27、基于所述上下文窗口的每个控制信息及其对应的权重,计算所述当前帧的融合控制信息。
28、可选的,所述基于正态分布,控制所述上下文窗口中各帧所对应的权重,包括:
29、获取预设的基于正态分布构建的权重计算函数,并基于所述权重计算函数,计算所述上下文窗口中每一帧的权重;
30、所述权重计算函数如下所示:
31、;
32、其中,为所述当前帧在所述上下文窗口的序号;为预设的标准差;x表示上下文窗口中序号为x的帧;为第x帧的权重。
33、可选的,每一帧的融合控制信息包括躯干融合控制信息、手部融合控制信息及面部融合控制信息;
34、所述将各帧的融合控制信息输入至所述目标动画模型,得到驱动目标形象的连续视频,包括:
35、将所述躯干融合控制信息、手部融合控制信息及面部融合控制信息分层注入至所述目标动画模型,得到驱动目标形象的连续视频。
36、可选的,所述目标动画模型包含有8×8的middle block、8×8的decoder block、32×32的decoder block、64×64的decoder block及16×16的decoder block;
37、将所述躯干融合控制信息、手部融合控制信息及面部融合控制信息分层注入至所述目标动画模型,包括:
38、将所述躯干融合控制信息注入至8×8的middle block及8×8的decoder block;
39、将所述手部融合控制信息及面部融合控制信息注入至32×32的decoder block及64×64的decoder block;
40、将所述融合控制信息注入至16×16的decoder block。
41、可选的,将所述lora形象权重参数融合于预设的动画扩散模型,得到目标动画模型,包括:
42、将所述lora形象权重参数融合于所述动画扩散模型的lora层级,融合后得到目标动画模型。
43、一种视频生成装置,包括:
44、控制信息获取模块,用于获取目标连续视频中每一帧的控制信息,以及,用于生成目标形象的lora形象权重参数;
45、参数融合模块,用于将所述lora形象权重参数融合于预设的动画扩散模型,得到目标动画模型;
46、窗口确定模块,用于确定每一帧对应的上下文窗口,每个上下文窗口中包含对应的当前帧以及环绕所述当前帧的若干帧;
47、控制信息融合模块,用于针对每一帧,将对应上下文窗口的各个控制信息进行融合,得到对应的融合控制信息;
48、连续视频生成模块,用于将各帧的融合控制信息输入至所述目标动画模型,得到驱动目标形象的连续视频。
49、一种视频生成设备,包括存储器和处理器;
50、所述存储器,用于存储程序;
51、所述处理器,用于执行所述程序,实现上述视频生成方法的各个步骤。
52、从上述的技术方案可以看出,本技术提供的视频生成方法,该方法可以先获取用于生成目标形象的lora形象权重参数,随后,将所述lora形象权重参数融合于预设的动画扩散模型,得到目标动画模型;基于此,本技术可以通过融合有lora形象权重参数的目标动画模型,在视频的每一帧中生成指定形象的数字人,保证视频的形象稳定性;在此基础上,可以目标连续视频中每一帧的控制信息;确定每一帧对应的上下文窗口,每个上下文窗口中包含对应的当前帧以及环绕所述当前帧的若干帧;针对每一帧,将对应上下文窗口的各个控制信息进行融合,得到对应的融合控制信息;基于此,可以在确定每帧的融合控制信息时,参考环绕当前帧的若干帧控制信息,进一步保证各个融合控制信息间的连贯性;最后,可以将各帧的融合控制信息输入至所述目标动画模型,得到驱动目标形象的连续视频;可见,本技术可以从数字人形象以及驱动控制信息两个方面,保证生成的连续视频的连贯性,提高生成连续视频的质量。
53、此外,本技术可以通过lora形象权重参数,保证连续视频中的形象为指定的目标形象,基于此,可以通过本技术生成驱动指定形象的连续视频。
- 还没有人留言评论。精彩留言会获得点赞!