一种薄互层油藏合采井产量预测方法与流程
本发明属于石油与天然气开采,尤其是涉及一种薄互层油藏合采井产量预测方法。
背景技术:
1、薄互层油藏储量规模大,在世界各大油田中广泛存在。由于地质条件复杂、纵向平面非均质性极强,该类油藏在注水开发过程中水流方向不明确,油井产能差异大,这也使得薄互层油藏一直没有形成一套完整、快速的产量预测方法。
2、随着人工智能、大数据领域的高速发展,许多优秀的算法被引入到各行各业中,主要是通过人工智能、大数据算法在数据之间建立一种数据驱动的模型来进行预测与分类。这也为薄互层油藏的油气产量预测提供了一种新思路,将人工智能、大数据算法引入到产量预测问题中。数据驱动的产量预测模型主要是通过人工智能算法构建输入数据与输出数据之间的映射关系,并利用大量的数据样本进行训练,以使模型具备准确预测油井产量的能力。虽然现有的数据驱动产量预测模型预测结果能满足生产基本需求,但是模型考虑的产量影响因素不够全面,预测精度仍存在较大的提升空间。
3、在薄互层油藏的实际生产过程中,产量的变化受多种因素的影响,是一个影响因素众多的复杂系统。在时间尺度上,油井生产制度的调整、储层或流体性质的变化都会对油井的生产动态产生一定程度的影响,例如泵频率改变影响油井产量。在空间尺度上,注采井间存在着复杂的空间相关性:平面上,一口井的工作制度发生变化,不仅会影响到自身的生产情况,还会对周边生产井产生一定程度的影响;纵向上,一口井同时生产多个小层,各小层之间存在层间干扰。现有的数据驱动产量预测模型仅能考虑到时间尺度上各因素的影响,无法考虑空间上井间、层间的干扰。为综合考虑多方面因素对产量的影响,需要建立一种新的模型,通过提取时间、空间两个维度的影响来提高薄互层油藏合采井产量的预测准确率。
技术实现思路
1、有鉴于此,本发明旨在提出一种薄互层油藏合采井产量预测方法,以解决目前数据驱动产量预测模型无法考虑井间相互影响的问题。
2、为达到上述目的,本发明的技术方案是这样实现的:一种薄互层油藏合采井产量预测方法,包括以下步骤:
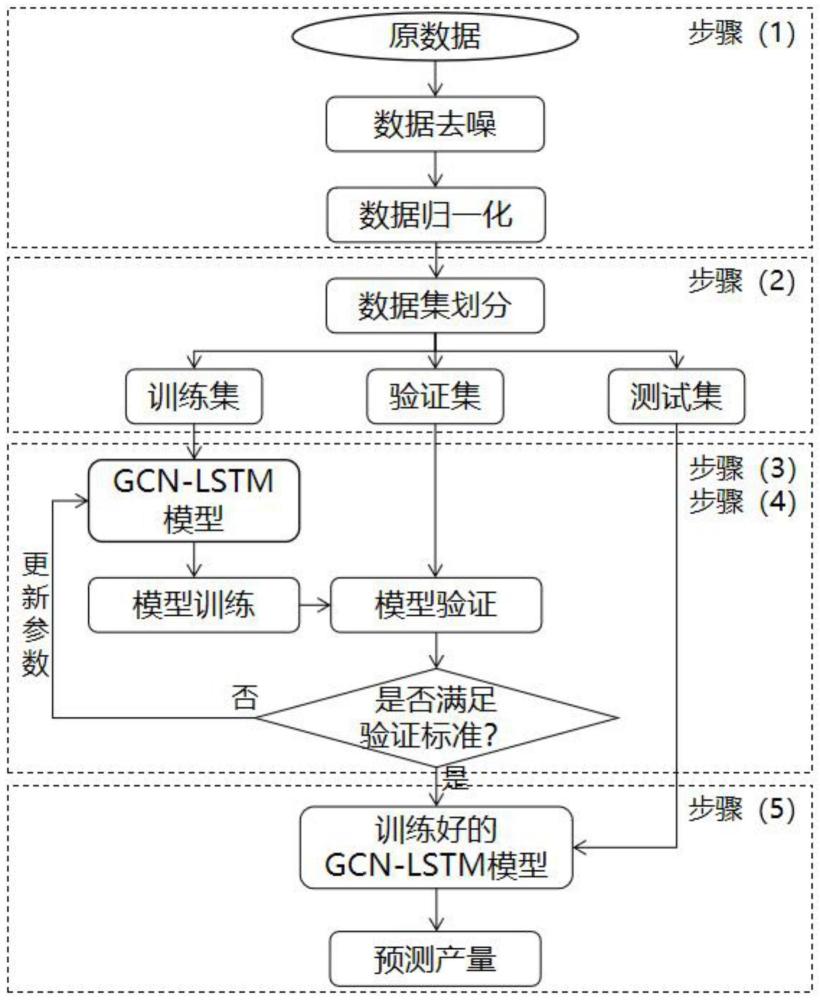
3、步骤1,对收集的薄互层油藏注采井数据进行预处理,包括数据去噪和数据归一化;
4、步骤2,对预处理后的数据进行数据集划分,划分为训练集、验证集和测试集;
5、步骤3,结合图卷积网络、长短期记忆网络和全连接网络建立薄互层油藏合采井产量预测模型,即gcn-lstm模型;
6、步骤4,利用步骤2中的训练集数据对步骤3建立的gcn-lstm模型进行训练,并通过对比gcn-lstm模型在训练集和验证集上的预测误差,防止gcn-lstm模型训练过拟合;
7、步骤5,利用步骤4训练好的gcn-lstm模型预测合采井的产量,并进行预测效果分析。
8、进一步的,所述步骤1中,数据去噪的计算流程具体如下:
9、含有噪音的生产动态数据x(i)经过自适应良好的集合经验模态分解算法分解后,会生成多个固有模态函数,即imfj,j=1,2,…,k,其中,集合经验模态分解也称为eemd,固有模态函数也称为imf,k表示eemd自适应分解级别,imf分量当中不仅包含了有用信息的分量,还包含了影响预测效果的噪声分量;
10、为了准确区分生产动态主导的imf分量和噪音主导的imf分量,引入样本熵作为判断标准,通过计算各个imf分量的样本熵,并根据所设置的样本熵阈值δ来区分生产动态主导的imf分量和噪音主导的imf分量,如果imf分量的样本熵大于样本熵阈值δ,表示该imf分量含有噪音;
11、针对含有噪声的imf分量,利用阈值去噪法去除含噪imf分量中的噪声,得到去噪后的imf分量imf'j;
12、将生产动态主导的imf分量与经过阈值去噪后的imf分量叠加以完成重构,即为去噪后的生产动态数据。
13、进一步的,所述步骤1中,数据归一化采用的是线性函数归一化方法,使不同量纲的数据转化为统一的处理格式,转换函数如下:
14、
15、上式中,x为原始数据变量,xnorm为归一化后的数据变量,xmin、xmax分别为数据变量的最小值和最大值。
16、进一步的,所述步骤2中数据集划分是将预处理后的数据按照时间顺序以一定的比例划分为训练集、验证集和测试集。
17、进一步的,所述步骤3中的薄互层油藏合采井产量预测模型包含空间特征提取单元、时间特征提取单元和时空融合预测单元,该模型在空间尺度上考虑到了各井之间的相互干扰,在时间尺度上考虑到了注入水在地层中传播存在时滞性的影响以及产量随时间变化的趋势和前后联系。
18、进一步的,空间特征提取单元具体如下:
19、利用连井剖面、射孔层位、渗流阻力法,在每个小层分别定义三种井间关系图,三种井间关系图分别为连通关系图gc、注采关系图gp、渗流阻力图gr;
20、连通关系图gc中边ei,j的权重wc(i,j)为两口井在该小层的连通情况,根据连井剖面,如果两口井在该小层是连通的,权重设为1,否则设为0,连通关系图gc的邻接矩阵ac的计算公式如下:
21、
22、注采关系图gp中边eij的权重wp(i,j)为两口井之间是否存在注采关系,根据注采井的射孔层位,如果注水井和生产井在该小层均有射孔,认为两口井之间存在注采关系,权重设为1,否则设为0,注采关系图gp的邻接矩阵ap的计算公式用式如下:
23、
24、渗流阻力图gr中边eij的权重wr(i,j)为两口井在该小层的渗流阻力,权重wr(i,j)的计算公式如下:
25、
26、式中:μ为地层原油粘度,mp·s;k为小层平均渗透率,md;h为小层平均厚度,m;l为井距,m;rw为井底半径,m;
27、渗流阻力图gr的邻接矩阵ar计算公式如下:
28、
29、在每个小层上,将连通关系图、注采关系图和渗流阻力图融合,得到表征小层级别渗流强弱的邻接矩阵al,计算公式如下:
30、
31、式中,为按元素相乘运算;
32、根据水电相似原理,计算得到表征井间级别渗流强弱的邻接矩阵aw,计算公式如下:
33、
34、式中,nl为小层数量;
35、在定量表征井间渗流强弱的基础上,利用图卷积网络提取注采井间空间相关性,图卷积网络的输入为注采量数据和一种表征井间级别渗流强弱的邻接矩阵aw,输出为一种包含空间信息的特征矩阵hspatial,图卷积网络的计算公式如下:
36、
37、式中,in为n阶单位矩阵,为对角矩阵,σ为relu激活函数,h(l+1)为第l+1层的节点特征矩阵,h(l)为h(l+1)为第l层的节点特征矩阵,w(l)为第l层的权重系数。
38、进一步的,时间特征提取单元具体如下:
39、考虑到历史生产动态数据的时序性,利用一个大小为ssw的滑动窗口对合采井的生产动态数据xp进行处理,得到k部分,即每一部分为np×ssw的矩阵,np为合采井生产动态数据的特征数量;
40、长短期记忆网络被用于捕捉时间相关性,也就是捕捉历史生产状况和注入水传播时滞性对生产井产量的影响,经滑动窗口处理后得到的k部分按时间顺序被喂到长短期记忆神经网络中,以提取时间上的前后影响,最终,长短期记忆网络最后一个隐状态的特征矩阵作为长短期记忆层的输出,记作htemporal。
41、进一步的,时空融合预测单元具体如下:
42、将编码了空间信息的特征矩阵hspatial和时间信息的特征矩阵htemporal输入到一个两层的全连接神经网络中,第一层是为了将特征矩阵hspatial和htemporal映射到隐层特征空间,第二层是为了转换到输出维度,经过输出层,得到下一时刻合采井的预测产量,全连接网络的计算公式如下:
43、
44、式中,和ht分别为全连接网络的输入和输出,w和b分别为全连接网络的权重和偏置项,σ为relu激活函数。
45、进一步的,所述步骤4包括:
46、步骤41,对预测模型的各个参数进行初始化;
47、步骤42,将训练集的输入数据传到输入层,从左向右逐层传播到输出层,得到模型的预测估计值;
48、步骤43,将模型预测估计值与实际值进行比较,并代入均方误差代价函数中计算误差,如下:
49、
50、式中,j为均方误差代价函数,n为样本总数,为第i个样本的预测日产油量,为第i个样本的实际日产油量;
51、步骤44,使用反向传播算法,根据代价函数从右向左逐层计算模型中每个参数的梯度;
52、步骤45,利用adam优化算法,更新模型参数;
53、步骤46,重复步骤42-步骤45,通过多次迭代,得到训练好的模型。
54、进一步的,所述步骤5中的预测效果分析为,评估步骤4训练好的gcn-lstm模型对测试集的预测产量与实际产量之间的误差,采取的是均方根误差、平均绝对误差和平均绝对百分比误差,如下:
55、
56、
57、
58、式中,为第i个样本的预测产量值,为第i个样本的真实产量值,n为样本数量。
59、相对于现有技术,本发明所述的薄互层油藏合采井产量预测方法具有以下优势:相较于一般的数据驱动产量预测方法,本发明所述方法利用图卷积网络挖掘空间上注采井之间的相互影响关系,利用长短期记忆网络捕捉时间上的前后影响关系,并利用全连接网络耦合时空特征。模型考虑的方面更加全面,具有较好的鲁棒性和预测稳定性,预测结果可为薄互层油藏开发方案的调整、生产制度的制定提供依据。
- 还没有人留言评论。精彩留言会获得点赞!