模型聚合方法、装置、设备、联邦学习系统及存储介质与流程
本发明涉及边缘计算领域,特别是涉及一种模型聚合方法、装置、设备、联邦学习系统及存储介质。
背景技术:
1、联邦学习是一种新型的分布式学习框架,它允许多个设备在不共享原始数据的情况下,合作训练一个共享的全局网络模型,然而在全局网络模型的训练过程中,联邦学习需要在设备之间同步大量的模型参数,数据传输量较大,不但提升了数据传输成本,降低了模型训练效率,而且重要程度较低的模型参数会影响到模型精度。
2、因此,如何提供一种解决上述技术问题的方案是本领域技术人员目前需要解决的问题。
技术实现思路
1、本发明的目的是提供一种异构分布式计算的模型聚合方法、装置、设备、联邦学习系统及计算机可读存储介质,由于参考了模型参数以及骨干网络层对本地网络模型性能的影响程度,因此理论上可以剔除对本地网络模型性能影响较小并保留对本地网络模型性能影响较大的模型参数,不但降低了数据传输成本,提升了数据传输效率,而且避免了重要程度较低的模型参数对模型精度的影响,使中心服务器在工业设备故障预测、网络安全问题识别与图片分类时发挥最优的效果。
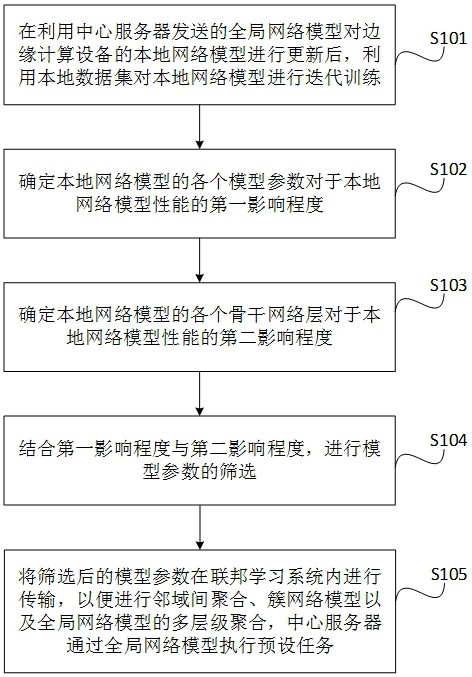
2、为解决上述技术问题,本发明提供了一种异构分布式计算的模型聚合方法,应用于联邦学习系统中的边缘计算设备,包括:
3、在利用中心服务器发送的全局网络模型对所述边缘计算设备的本地网络模型进行更新后,利用本地数据集对所述本地网络模型进行迭代训练;
4、确定所述本地网络模型的各个模型参数对于所述本地网络模型的性能的第一影响程度;
5、确定所述本地网络模型的各个骨干网络层对于所述本地网络模型的性能的第二影响程度;
6、结合所述第一影响程度与所述第二影响程度,进行模型参数的筛选;
7、将筛选后的模型参数在所述联邦学习系统内进行传输,以便进行邻域间聚合、簇网络模型以及全局网络模型的多层级聚合,所述中心服务器通过所述全局网络模型执行预设任务;
8、其中,所述预设任务包括预测工业设备的故障、识别网络安全问题以及对图片进行分类中的任一种。
9、另一方面,确定所述本地网络模型的各个骨干网络层对于所述本地网络模型的性能的第二影响程度包括:
10、对于所述本地网络模型的任一个骨干网络层,在所述骨干网络层的模型参数被施加预设扰动的情况下,确定所述本地网络模型的性能为扰动性能;
11、对于所述本地网络模型的任一个骨干网络层,将所述骨干网络层对应的扰动性能与所述本地网络模型的基准性能的差值,作为所述骨干网络层对于所述本地网络模型的性能的第二影响程度。
12、另一方面,对于所述本地网络模型的任一个骨干网络层,在所述骨干网络层的模型参数被施加预设扰动的情况下,确定所述本地网络模型的性能为扰动性能包括:
13、对于所述本地网络模型的任一个骨干网络层,在所述骨干网络层的模型参数被施加预设正向扰动的情况下,确定所述本地网络模型的性能为第一子扰动性能;
14、在所述骨干网络层的模型参数被施加预设负向扰动的情况下,确定所述本地网络模型的性能为第二子扰动性能;
15、将所述第一子扰动性能与所述第二子扰动性能的均值作为所述骨干网络层的扰动性能。
16、另一方面,所述预设正向扰动包括:
17、增加预设常数以及乘以预设放大系数中的一者;
18、所述预设负向扰动包括:
19、减去所述预设常数以及乘以预设缩小系数中的一者。
20、另一方面,确定所述本地网络模型的各个模型参数对于所述本地网络模型的性能的第一影响程度包括:
21、基于反向传播算法确定出所述本地网络模型中各个模型参数的梯度;
22、将所述梯度的绝对值作为模型参数对于所述本地网络模型的性能的第一影响程度。
23、另一方面,结合所述第一影响程度与所述第二影响程度,进行模型参数的筛选包括:
24、根据所述第一影响程度对所述本地网络模型进行模型参数的第一次筛选;
25、根据所述第二影响程度确定出对所述本地网络模型的影响程度达标的若干个目标骨干网络层;
26、保留经过第一次筛选后的模型参数中,位于所述目标骨干网络层的模型参数。
27、另一方面,根据所述第一影响程度对所述本地网络模型进行模型参数的第一次筛选包括:
28、按照所述第一影响程度从高到低的顺序,保留第一预设数量个模型参数。
29、另一方面,根据所述第二影响程度确定出对所述本地网络模型的影响程度达标的若干个目标骨干网络层包括:
30、按照所述第二影响程度从高到低的顺序,保留第二预设数量个目标骨干网络层。
31、另一方面,在利用中心服务器发送的全局网络模型对所述边缘计算设备的本地网络模型进行更新后,利用本地数据集对所述本地网络模型进行迭代训练之前,该异构分布式计算的模型聚合方法还包括:
32、获取所述联邦学习系统中各边缘计算设备的分簇信息,其中,每一簇中的各个所述边缘计算设备的本地数据属于同一类别;
33、所述将筛选后的模型参数在所述联邦学习系统内进行传输,以便进行邻域间聚合、簇网络模型以及全局网络模型的多层级聚合包括:
34、根据所述分簇信息,将筛选后的模型参数在所述联邦学习系统内进行传输,以便进行邻域间聚合、簇网络模型以及全局网络模型的多层级聚合。
35、另一方面,获取所述联邦学习系统中各边缘计算设备的分簇信息包括:
36、将本地网络模型对预设公共数据集的推理结果上传至中心服务器,以便所述中心服务器根据所述推理结果构建各个所述边缘计算设备之间的有权无向图,基于所述有权无向图中各条边的数值对各个所述边缘计算设备进行分簇,将所述边缘计算设备的分簇信息发送至各个所述边缘计算设备;
37、接收所述中心服务器发送的所述分簇信息。
38、另一方面,该异构分布式计算的模型聚合方法还包括:
39、接收所述中心服务器发送的各簇簇头的标识;其中,所述各簇簇头的标识为所述中心服务器根据各个所述边缘计算设备的通信性能和/或各个所述边缘计算设备与所述中心服务器的距离,基于通信效率优先原则,为各簇所述边缘计算设备确定出作为簇头的边缘计算设备,并确定出所述各簇簇头的标识;
40、根据所述分簇信息,将筛选后的模型参数在所述联邦学习系统内进行传输,以便进行邻域间聚合、簇网络模型以及全局网络模型的多层级聚合包括:
41、根据所述分簇信息以及所在簇的簇头的标识,将筛选后的模型参数在所述联邦学习系统内进行传输,以便进行邻域间聚合、簇网络模型以及全局网络模型的多层级聚合。
42、另一方面,根据所述分簇信息以及所在簇的簇头的标识,将筛选后的模型参数在所述联邦学习系统内进行传输,以便进行邻域间聚合、簇网络模型以及全局网络模型的多层级聚合包括:
43、在本地迭代次数达到第一预设次数时,将筛选后的模型参数进行广播;
44、接收所述有权无向图中与自身具备连接关系且同簇的边缘计算设备的广播数据;
45、将接收到的模型参数与筛选后的模型参数的均值作为自身最新的模型参数继续进行本地网络模型的迭代训练;
46、在本地迭代次数达到第二预设次数时,将所述筛选后的模型参数的当前值发送至所在簇的簇头;
47、若自身为簇头,则将接收到的簇内各边缘计算设备发送的模型参数与自身的所述筛选后的模型参数的当前值进行聚合,得到所在簇的簇网络模型;
48、将所述簇网络模型发送至所述中心服务器,以便所述中心服务器依据各个簇的簇网络模型进行全局网络模型的聚合;
49、其中,所述分簇信息包括所述有权无向图以及各簇成员的标识,所述第一预设次数小于所述第二预设次数。
50、另一方面,利用本地数据集对所述本地网络模型进行迭代训练包括:
51、结合本地数据集以及本地模型参数损失函数,根据预设迭代更新公式对所述本地网络模型进行迭代训练;
52、所述预设迭代更新公式包括:
53、;
54、其中,为本地的第 i个所述边缘计算设备在第t轮第 l次迭代更新后的模型参数, i为边缘计算设备在簇中的序号,为第t轮第 l次迭代更新前的模型参数,为第t轮第 l次迭代更新的学习率,为哈密顿算子,为所述本地数据集中参与第t轮第 l次迭代更新的数据样本,为第t轮第 l次迭代更新的样本损失函数。
55、另一方面,所述本地模型参数损失函数包括:
56、;
57、其中,为本地的第 i个所述边缘计算设备的模型参数,为的损失函数值,为所述本地数据集,为所述本地数据集中参与迭代更新的数据样本,为数据样本的总数量,为数据样本损失函数。
58、另一方面,将接收到的簇内各边缘计算设备发送的模型参数与自身的所述筛选后的模型参数的当前值进行聚合,得到所在簇的簇网络模型包括:
59、基于簇内聚合公式,将接收到的簇内各边缘计算设备发送的模型参数与自身的所述筛选后的模型参数的当前值进行聚合,得到所在簇的簇网络模型;
60、所述簇内聚合公式包括:
61、;
62、其中,为所在簇在第t轮的模型参数,为所在簇在簇内聚合完毕后的第t+1轮的模型参数,c为簇的序号,为超参数;为所在簇的邻域设备集合中的第 j个边缘计算设备在第t轮第 l次更新后的模型参数,为与簇内的第 i个边缘计算设备在所述有权无向图中具备连接关系的边缘计算设备的邻域设备集合, i为边缘计算设备在簇中的序号, j为边缘计算设备在邻域设备集合内的序号,,为所在簇的边缘计算设备的总数量。
63、另一方面,将所述簇网络模型发送至所述中心服务器,以便所述中心服务器依据各个簇的簇网络模型进行全局网络模型的聚合包括:
64、将所述簇网络模型发送至所述中心服务器,以便所述中心服务器依据各个簇的簇网络模型以及全局损失函数进行全局网络模型的聚合;
65、所述全局损失函数包括:
66、;
67、其中,为全局网络模型的模型参数,为全局网络模型的模型参数的损失值,n为所述联邦学习系统中边缘计算设备的总数量,为簇sk中的第 i个边缘计算设备的模型参数, i∈(1,2,3...nk-1,nk),nk为簇sk中边缘计算设备的总数量,k为簇的序号,k∈(1,2,3...c-1,c),c为所述联邦学习系统中簇的总数量。
68、为解决上述技术问题,本发明还提供了一种异构分布式计算的模型聚合方法,应用于联邦学习系统中的边缘计算设备,包括:
69、在利用中心服务器发送的全局网络模型对所述边缘计算设备的本地网络模型进行更新后,利用本地数据集对所述本地网络模型进行迭代训练;
70、确定所述本地网络模型的各个模型参数对于所述本地网络模型的性能的第一影响程度;
71、确定所述本地网络模型的各个骨干网络层对于所述本地网络模型的性能的第二影响程度;
72、结合所述第一影响程度与所述第二影响程度,进行模型参数的筛选;
73、将筛选后的模型参数在所述联邦学习系统内进行传输,以便进行邻域间聚合、簇网络模型以及全局网络模型的多层级聚合,中心服务器通过所述全局网络模型执行预设任务。
74、为解决上述技术问题,本发明还提供了一种异构分布式计算的模型聚合装置,应用于联邦学习系统中的边缘计算设备,包括:
75、边缘训练模块,用于在利用中心服务器发送的全局网络模型对所述边缘计算设备的本地网络模型进行更新后,利用本地数据集对所述本地网络模型进行迭代训练;
76、第一确定模块,用于确定所述本地网络模型的各个模型参数对于所述本地网络模型的性能的第一影响程度;
77、第二确定模块,用于确定所述本地网络模型的各个骨干网络层对于所述本地网络模型的性能的第二影响程度;
78、筛选模块,用于结合所述第一影响程度与所述第二影响程度,进行模型参数的筛选;
79、传输模块,用于将筛选后的模型参数在所述联邦学习系统内进行传输,以便进行邻域间聚合、簇网络模型以及全局网络模型的多层级聚合,中心服务器通过所述全局网络模型执行预设任务;
80、其中,所述预设任务包括预测工业设备的故障、识别网络安全问题以及对图片进行分类中的任一种。
81、为解决上述技术问题,本发明还提供了一种异构分布式计算的模型聚合设备,应用于联邦学习系统,包括:
82、存储器,用于存储计算机程序;
83、处理器,用于执行所述计算机程序时实现如上所述异构分布式计算的模型聚合方法的步骤。
84、为解决上述技术问题,本发明还提供了一种联邦学习系统,包括中心服务器;
85、还包括与所述中心服务器连接的多个如上所述的异构分布式计算的模型聚合设备。
86、为解决上述技术问题,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上所述异构分布式计算的模型聚合方法的步骤。
87、有益效果:本发明提供了一种异构分布式计算的模型聚合方法,考虑到联邦学习系统的边缘计算设备中的各个模型参数与各个骨干网络层对于本地网络模型性能的影响程度存在差异,因此本发明可以分别确定本地网络模型的各个模型参数对于本地网络模型性能的第一影响程度以及各个骨干网络层对于本地网络模型性能的第二影响程度,然后再结合第一影响程度与第二影响程度,对模型参数进行筛选,由于参考了模型参数以及骨干网络层对本地网络模型性能的影响程度,因此理论上可以剔除对本地网络模型性能影响较小并保留对本地网络模型性能影响较大的模型参数,不但降低了数据传输成本,提升了数据传输效率,而且避免了重要程度较低的模型参数对模型精度的影响,使中心服务器在工业设备故障预测、网络安全问题识别与图片分类时发挥最优的效果。
88、本发明还提供了一种异构分布式计算的模型聚合方法、装置、设备、联邦学习系统及计算机可读存储介质,具有如上异构分布式计算的模型聚合方法相同的有益效果。
- 还没有人留言评论。精彩留言会获得点赞!