一种基于人工智能的在线考评得分评估方法与流程
本发明涉及教育评估的,尤其涉及一种基于人工智能的在线考评得分评估方法。
背景技术:
1、在线考评是一种通过网络平台进行的教学和学习评估方法,它具有灵活性、高效性和可扩展性等优势。然而,在在线考评中,如何准确评估学生的主观作答题得分成绩仍然是一个挑战。传统的评估方法通常需要人工参与,耗费时间和资源,并且容易出现主观性和不一致性的问题。因此,自动化在线考评得分评估成为亟需解决的现实问题。针对该问题,本技术一种基于人工智能的在线考评得分评估方法与系统,通过利用人工智能技术自动化评估学生主观作答题目得分,减少了人工评分的工作量和时间,同时降低了评分过程中可能存在的主观性和误差。
技术实现思路
1、有鉴于此,本发明提供一种基于人工智能的在线考评得分评估方法与系统,目的在于:1)提出一种基于人工智能的在线考评得分评估方法,通过结合预训练模型、文本理解技术和文本相似性度量方法,能够有效地抽取标准答案知识点、提取学生答题要点,并通过知识点覆盖度计算对学生答案进行自动化评估,提高评估效率,减少了人工评分的工作量和时间,同时降低了评分过程中可能存在的主观性和误差;2)通过使用预训练文本理解模型,能够对标准答案数据进行知识点抽取,并从学生答案数据中提取答题要点,能够更好地理解和提取文本中的关键信息,为自动化评估奠定基础;3)使用稀疏transformer编码器进行知识点和要点提取,在保持全局依赖性的同时能够降低模型的复杂度,能够更好处理长序列答案数据,并且减少了需要训练和存储的参数数量,使得模型更加轻量化和高效。
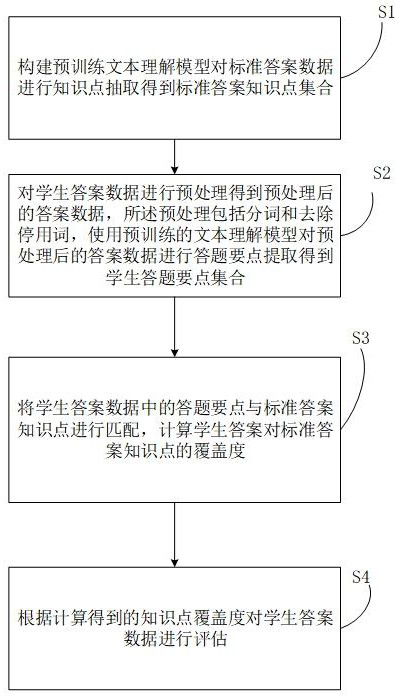
2、实现上述目的,本发明提供的一种基于人工智能的在线考评得分评估方法,包括以下步骤:
3、s1:构建预训练文本理解模型对标准答案数据进行知识点抽取,得到标准答案知识点集合;
4、s2:对学生答案数据进行预处理得到预处理后的答案数据,所述预处理为口语化表达词汇文本化处理,使用预训练的文本理解模型对预处理后的答案数据进行答题要点提取,得到学生答题要点集合;
5、s3:将学生答案数据中的答题要点与标准答案知识点进行匹配,计算学生答案对标准答案知识点的覆盖度,知识点匹配的实施方法为文本相似性度量;
6、s4:根据计算得到的知识点覆盖度对学生答案数据进行评估。
7、作为本发明的进一步改进方法:
8、可选地,所述s1步骤中构建预训练文本理解模型,包括:
9、所述预训练文本理解模型包括transformer编码器层和知识点提取层,其中,transformer编码器层由多个改进的transformer编码器块构成,用于捕捉文本中的上下文信息;知识点提取层使用全连接层将transformer编码器层的输出映射到预定义的知识点空间。
10、可选地,所述改进的transformer编码器为稀疏transformer编码器,包括输入嵌入层、位置编码层、基于注意力的稀疏化层、多头自注意力层、残差连接和层归一化和前馈神经网络层,其中输入嵌入层将输入序列中的每个词或特征转换为嵌入向量表示;位置编码层为输入序列中的每个位置添加位置编码,以保留序列中的顺序信息;基于注意力的稀疏化层通过引入稀疏性来减少注意力计算的时间和空间复杂度;多头自注意力层进行多头注意力计算,并利用稀疏化后的注意力权重进行注意力加权求和;残差连接和层归一化在每个子层之后,应用残差连接和层归一化处理;前馈神经网络层通过两个全连接层和激活函数处理每个序列位置的注意力机制输出;
11、所述改进的transformer编码器的具体编码流程为:
12、s11:初始化输入嵌入层和位置编码层,得到输入序列的嵌入表示;
13、s12:将嵌入表示输入到基于注意力的稀疏化层进行注意力计算,并得到稀疏化的注意力权重;
14、其中,注意力分数计算公式为:
15、;
16、稀疏化注意力权重计算公式为:
17、;
18、其中,q表示查询矩阵,k表示键矩阵,表示查询矩阵和键矩阵维度,topk表示保留的与查询相关性最高的k个注意力权重;normalize表示归一化操作;
19、s13:将稀疏化的注意力权重输入到多头自注意力层,并利用注意力权重对输入进行加权求和得到注意力输出;
20、其中,多头注意力分数计算公式为:
21、;
22、多头注意力权重计算公式为:
23、;
24、其中,表示第i个注意力头的查询矩阵,表示第i个注意力头的键矩阵,表示第i个注意力头的值矩阵,表示第i个注意力头的注意力权重计算结果,表示查询矩阵和键矩阵维度;
25、s14:在注意力输出上应用残差连接和层归一化;
26、s15:将残差连接和层归一化后的输出输入到前馈神经网络层进行非线性变换;
27、s16:在前馈神经网络层上再次应用残差连接和层归一化;
28、s17:重复步骤s12-s16,堆叠多个编码器层,输出最终的编码表示。
29、可选地,所述s2步骤中对学生答案数据进行预处理得到预处理后的答案数据,包括:
30、所述对学生答案数据进行预处理为去除答案数据中的口语化表达词汇,替换为书面表达词汇,其中将口语化表达词汇替换为书面表达词汇的实施方法为lstm模型,具体流程为:
31、lstm模型中的编码器部分将口语化表达词汇经过嵌入层转换为词向量表示,再通过多个lstm层进行序列编码,输入当前时间步的词向量和前一个时间步的隐藏状态,得到当前时间步的隐藏状态;最后一个lstm层的隐藏状态即为编码器的输出;
32、lstm模型中的解码器部分对目标书面文本进行预处理,并经过嵌入层转换为词向量表示;通过多个lstm层进行序列解码,输入当前时间步的词向量、前一个时间步的隐藏状态和编码器的输出,得到当前时间步的隐藏状态;将最后一个lstm层的隐藏状态传递给全连接层,通过softmax函数生成下一个时间步的词的概率分布;直到生成结束符号或达到最大序列长度停止生成。
33、可选地,所述s3步骤中将学生答案数据中的答题要点与标准答案知识点进行匹配,包括:
34、将学生答案数据中的答题要点与标准答案知识点进行向量化处理分别得到答题要点向量和知识点向量,根据计算得到的向量进行匹配,学生答案数据中的答题要点与标准答案知识点的向量化处理具体流程为:
35、s31:将每个知识点单词拆分成字符,并通过嵌入层将每个字符映射为字符级别的词向量;
36、s32:输入字符级别的词向量序列,通过前向lstm模型进行编码,得到正向上下文感知的词向量表示,计算公式为:
37、;
38、其中,表示t时刻前向lstm的隐藏状态向量,表示t时刻输入的字符级别的词向量;
39、s33:输入字符级别的词向量序列,通过反向lstm模型进行编码,得到反向上下文感知的词向量表示,计算公式为:
40、;
41、其中,表示t时刻反向lstm的隐藏状态向量,表示t时刻输入的字符级别的词向量;
42、s34:对前向lstm模型和反向lstm模型的生成的词向量进行融合操作生成最终的上下文相关的词向量表示,计算公式为:
43、;
44、其中,表示第m个单词的融合词向量表示,和 分别表示第m个知识点单词在t时刻前向和反向lstm的第k层隐藏状态向量,表示第k层的权重进行的归一化操作,表示缩放因子,l表示层数;
45、s35:按照步骤s31到s34对学生答案数据中的答题要点与标准答案知识点进行向量化处理,计算得到答题要点向量和知识点向量,根据计算得到的答题要点向量和知识点向量进行相似性匹配。
46、可选地,所述s35步骤中根据计算得到的答题要点向量和知识点向量进行相似性匹配,包括:
47、使用欧式距离计算答题要点向量和知识点向量的相似性,计算公式为:
48、;
49、其中,和分别表示知识点向量a和答题要点向量b在第i个维度上的值。
50、可选地,所述s3步骤中计算学生答案对标准答案知识点的覆盖度,包括:
51、若答题要点向量和知识点向量的相似性超过指定预置,则说明学生答案数据中包含预置知识点,则命中知识点数量加1,统计总共的命中知识点数量,根据统计得到的总共命中知识点数量计算知识点覆盖度,计算公式为:
52、;
53、其中,表示命中知识点数量,表示标准答案中总共知识点数量。
54、可选地,所述s4步骤中根据计算得到的知识点覆盖度对学生答案数据进行评估,包括:
55、;
56、其中,表示知识点覆盖度,表示总分,表示学生答案的得分。
57、为了解决上述问题,本发明提供一种电子设备,所述电子设备包括:
58、存储器,存储至少一个指令;
59、通信接口,实现电子设备通信;及
60、处理器,执行所述存储器中存储的指令以实现上述所述的基于人工智能的在线考评得分评估方法。
61、为了解决上述问题,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一个指令,所述至少一个指令被电子设备中的处理器执行以实现上述所述的基于人工智能的在线考评得分评估方法。
62、相对于现有技术,本发明提出一种基于人工智能的在线考评得分评估方法,该技术具有以下优势:
63、首先,本方案提出一种基于人工智能的在线考评得分评估方法,通过结合预训练模型、文本理解技术和文本相似性度量方法,能够有效地抽取标准答案知识点、提取学生答题要点,并通过知识点覆盖度计算对学生答案进行自动化评估,提高评估效率,减少了人工评分的工作量和时间,同时降低了评分过程中可能存在的主观性和误差。
64、同时,本方案通过使用预训练文本理解模型,能够对标准答案数据进行知识点抽取,并从学生答案数据中提取答题要点,能够更好地理解和提取文本中的关键信息,为自动化评估奠定基础,并使用稀疏transformer编码器进行知识点和要点提取,在保持全局依赖性的同时能够降低模型的复杂度,能够更好处理长序列答案数据,并且减少了需要训练和存储的参数数量,使得模型更加轻量化和高效。
- 还没有人留言评论。精彩留言会获得点赞!