一种测绘数据处理方法与流程
本技术涉及测绘数据处理,特别涉及一种测绘数据处理方法。
背景技术:
1、随着科技的迅猛发展,测绘数据在地理信息系统、城市规划、环境监测等领域的应用变得愈发广泛。然而,现有技术在测绘数据处理中仍然面临着复杂度高、空间分析精度不足等问题。这些问题限制了对地理信息的深入挖掘与综合分析,对于高效的数据处理和准确的空间分析提出了新的需求。
2、当前的测绘数据处理方法存在诸多挑战。传统的处理方法通常难以应对大规模、多维度的地理数据,导致复杂度升高,处理效率不高。同时,现有技术在空间分析中的精度不足,难以准确捕捉地物之间的关联关系和多尺度分布特征。
3、在相关技术中,比如中国专利文献cn117271683a中提供了一种测绘数据智能分析评价方法,涉及测绘数据信息处理技术领域,解决了传统测绘数据分析评价方法中数据分析不全面、数据质量评价不精确和异常检测方面存在的缺点;采用的方法包括:通过数据预处理方法对测绘数据进行清洗去噪、校正转换和缺省值填充操作;通过图像处理工具从测绘数据中提取特征,并通过特征选择器排除冗余和不相关的特征;通过空间分析模块对地理信息进行空间叠加;通过统计分析模块对测绘数据进行统计描述、统计推断和其中检验处理;通过智能分析模块对测绘数据进行分类、预测和优化处理;通过智能评价模块进行数据评价与异常检测;通过可视化模块将评价内容和分析后的测绘数据进行展示。但是该方案中空间分析主要采用叠加分析,无法反映复杂的空间关联和交互关系,因此该方案的分析精度有待进一步提高。
技术实现思路
1、1.要解决的技术问题
2、针对现有技术中存在的测绘数据分析精度低的问题,本技术提供了一种测绘数据处理方法,通过构建四叉树索引和getisordgi*统计分析等,提高了测绘数据的分析精度。
3、2.技术方案
4、本技术的目的通过以下技术方案实现。
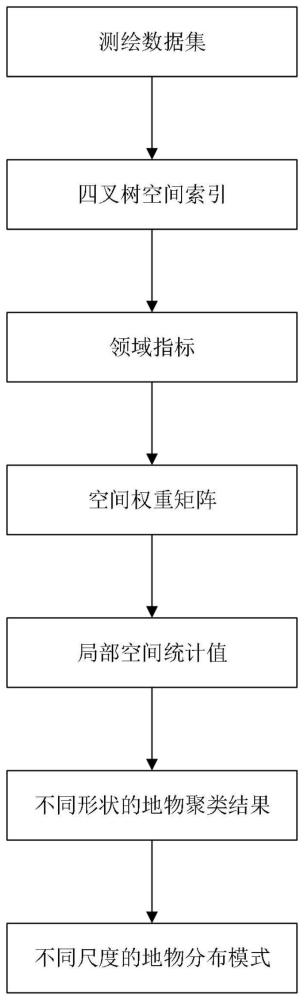
5、本说明书实施例提供一种测绘数据处理方法,包括:采集包含多个地物的测绘数据集,其中每个地物表示地图中的点、线或面实体;建立测绘数据集的四叉树空间索引;利用建立的四叉树空间索引,通过距离度量方法,计算每个地物的领域指标,领域指标表示地物周边范围的统计特征;根据计算得到的领域指标,构建各个地物的空间权重矩阵;根据构建的空间权重矩阵,采用getisordgi*统计方法计算每个地物的局部空间统计值,局部空间统计值表示地物局部聚集程度;根据得到的每个地物的局部空间统计值,采用分层聚类算法对测绘数据集进行分层聚类,得到不同形状的地物聚类结果;根据得到的不同形状的地物聚类结果,通过多尺度局部空间统计分析,得到不同形状内的不同尺度下的地物分布模式,作为测绘数据的处理结果。
6、其中,地物是指地图或者地球表面上的一个实体对象,可以是自然地物也可以是人工地物。在本技术的技术方案中,地物特指地形图或者土地利用图等测绘产品中的要素,代表地图上不同类型的点、线、面要素对象,如建筑、道路、河流等。每个地物都包含有丰富的属性信息,如名称、几何形状、空间坐标等。本技术的技术方案需要对测绘数据集中的各个地物及其属性进行分析处理,以发现地物之间的空间分布规律。在本技术中,地物主要指地形图或土地利用图中的以下类型要素:点状地物:如孤立的建筑、地名标注等;线状地物:如道路、河流、等高线等;面状地物:如不同类型的土地利用区等。通过对每个地物的空间位置和属性进行综合分析,可以揭示区域内地物的分布与聚集规律,实现测绘数据内在结构的挖掘。
7、其中,四叉树空间索引是一种树形数据结构,可以用于地理空间数据的索引。它通过递归地将空间区域划分成四个子区域,构建出层级的树形结构,实现对空间对象的索引。在本技术中,采用四叉树空间索引的目的是对测绘数据集中的各个地物点进行索引与存储,通过四叉树空间索引,可以快速判断检索每个地物相邻周边的地物,有利于后续的领域指标计算与空间分析。四叉树空间索引实现了高效的数据存储与索引,是本技术方案实现空间聚类分析的基础。
8、其中,领域指标是反映地物周边领域环境特征的一个统计量。它通过统计和分析地物周围区域内其他地物的属性,来表征该地物所处位置的整体特征。在本技术中,基于构建的四叉树空间索引,确定每个地物的相邻地物集合。计算每个相邻地物与当前地物的欧式距离。按照距离为相邻地物赋予权重。对相邻地物属性值进行加权平均,得到当前地物的领域指标。通过领域指标,可以反映出每个地物所在位置周边地物布局和分布情况的影响,是后续空间统计分析的重要参考指标。
9、其中,getisordgi*统计方法是一种用于探测点状事件的空间聚集模式的统计方法。它通过计算每个要素与周围要素值的关系,来反映要素局部的空间自相关性。在本技术中;基于构建的空间权重矩阵,计算每个地物与周边地物的权重值;利用地物的属性值和权重值,计算每个地物的gi*统计量;标准化gi*值,得到z-score值,反映地物的空间聚集程度;正的z-score值表示地物周边存在聚集,负的z-score值表示周边存在离散。通过getisordgi*统计方法,可以有效判定每个地物周边是否存在属性值的聚集,即判定地物局部的聚集规律,为后续的聚类分析提供支持。
10、其中,分层聚类算法是一种不断划分数据样本集的聚类算法。它通过层次的划分,能够得到不同粒度的聚类结果。根据地物的局部空间统计值,采用分层聚类算法对地物进行聚类。调整聚类粒度,得到不同粒度下的聚类结果。对不同形状(点、线、面)的地物分别进行分层聚类,得到不同形状的聚类结果。分析不同粒度和不同形状下的聚类规律。分层聚类算法可以获得不同粒度的聚类,进一步揭示出地物在不同尺度下的聚集规律,实现对测绘数据的多维挖掘。具体的,在本技术中,可以采用:基于密度的分层聚类算法,如dbscan算法,optics算法。基于模型的分层聚类算法,如方差分析聚类,谱聚类。基于网格的分层聚类算法,如sting聚类,clique聚类。
11、其中,多尺度局部空间统计分析是指利用不同参数设置进行局部空间统计,从而实现对地物分布模式的多尺度解析。在本技术中,对不同形状聚类后的地物,设置不同的统计窗口大小。对每个窗口,计算地物的局部空间统计量,如核密度。变化窗口大小,重复计算,得到不同尺度下的统计结果。比较不同尺度的统计量差异,解析地物的多尺度分布模式。通过多尺度局部空间统计分析,可以挖掘出不同形状地物在不同尺度水平下的聚集与分布规律,实现测绘数据内在结构的多维解析。
12、具体的,首先,从多个来源采集测绘数据集,该数据集包含地图中的点、线或面实体,这些地物可以代表各种地理特征,如建筑物、道路、水体等。数据集的多样性和综合性对于后续的分析具有重要意义,确保对地理信息的全面理解。对采集到的测绘数据集,采用四叉树空间索引结构进行建立。四叉树是一种适用于二维空间的树状数据结构,能够将地理空间划分为矩形区域,每个节点可以包含若干地物。这样的索引结构有助于提高数据的检索效率,使得对地物的访问更加迅速。通过建立的四叉树空间索引,对每个地物进行领域指标的计算。领域指标是通过距离度量方法获得的,它表示每个地物周边范围的统计特征。这可能涉及到对地物周围区域的邻近地物数量、距离等进行度量,以捕捉地物空间分布的特征。在计算领域指标时,采用距离度量方法,通过四叉树空间索引得到地物之间的相对位置信息。这可以包括欧氏距离、曼哈顿距离等,具体的选择取决于地物之间的关系和问题的要求。距离度量方法是确保领域指标准确反映地物周边范围统计特征的关键步骤。领域指标计算完成后,得到每个地物周围范围的统计特征。这些指标可以包括邻近地物的数量、平均距离、密度等,反映了地物的空间关联性和分布情况。这为后续的空间分析提供了重要的数据基础。
13、具体的,基于计算得到的领域指标,构建各个地物的空间权重矩阵。空间权重矩阵反映了地物之间的空间关系,以及它们在空间上的相互影响程度。构建空间权重矩阵的过程中,可以利用领域指标的数值作为权重,也可以采用其他距离加权方法,以便更好地反映地物的空间关联性。使用构建好的空间权重矩阵,采用getisordgi统计方法对每个地物进行局部空间统计值的计算。getisordgi统计方法是一种用于评估地理数据中聚集程度的统计工具,它考虑了每个地物的权重以及周围地物的空间分布情况。这一统计方法能够明确地揭示每个地物在其周围区域内的局部聚集状况。通过对空间权重矩阵与地物属性进行运算,得到每个地物的原始局部值。在空间统计中,期望的局部值是在空间上均匀分布时的预期值。getisordgi*方法将每个地物的局部值与期望的局部值进行比较,以评估其聚集程度。通过比较实际的局部值和期望的局部值,计算出gi*统计值,它表示了每个地物相对于其周围地物的聚集程度。getisordgi*统计值的结果可以分为正值、负值和接近零的情况,分别代表了局部聚集、局部离散和无显著聚集。这些值提供了关于每个地物在其周围区域内分布特征的直观信息,对于理解地物之间的空间关系具有重要意义。
14、具体的,采用分层聚类算法对测绘数据集进行分层聚类,以得到不同形状的地物聚类结果。分层聚类算法是一种基于相似性的聚类方法,它能够将地物按照它们之间的相似性进行分组,并构建层次结构。这样的聚类结果能够直观地反映出地物之间的关联关系,有助于理解地物的空间分布模式。根据得到的不同形状的地物聚类结果,采用多尺度局部空间统计分析方法,得到不同形状内的不同尺度下的地物分布模式。多尺度局部空间统计分析是一种综合利用不同尺度信息进行地理数据分析的方法,它能够在不同的空间尺度下揭示地物分布的多样性和特征。根据地物的聚类结果,确定不同形状内的不同尺度范围,即分析尺度。在每个尺度下,应用局部空间统计方法(如核密度估计、波动性分析等),对地物的空间分布进行统计分析。比较不同尺度下地物的分布模式和聚集程度,以获取全面的地物分布信息。通过多尺度局部空间统计分析得到的结果,能够展现不同尺度下地物的空间分布模式和聚集程度。这些结果可以为城市规划、资源管理、环境保护等领域的决策提供重要参考。同时,分析结果也可以用于探索地物之间的空间关系和规律,促进对地理数据的深入理解和挖掘。
15、进一步的,构建四叉树空间索引,包括:构建四叉树的数据结构,数据结构包含根节点和叶子节点;获取测绘数据集中每个地物的空间坐标(x,y,z);从数据结构中的根节点开始递归对每个节点的空间坐标(x,y,z),进行判断,判断地物的空间坐标(x,y,z),是否在根节点的空间范围内;如果是,继续递归判断叶子节点,直到找到一个叶子节点其范围包含对应的空间坐标(x,y,z),将空间坐标(x,y,z),对应的地物与叶子节点进行关联,作为对应叶子节点的数据;重复以上步骤直到将测绘数据集内每个地物递归插入四叉树,形成四叉树空间索引。
16、具体的,初始化一个根节点,代表整个坐标空间区域;递归分割每个节点的代表空间为四个子区域,对应生成四个子节点;每个节点使用一个矩形表示其代表的空间区域;重复以上步骤,递归生成内部节点和叶子节点;内部节点用于表示子区域,叶子节点用于存储具体的数据点;最终形成一个从根节点到叶子节点的多层树形结构。取测绘数据集,提取每个地物的几何信息。
17、计算每个地物几何形状的质心,获取对应空间坐标(x,y,z);从根节点出发,获取根节点代表的空间范围;对第一个地物,判断其空间坐标(x,y,z)是否在根节点空间范围内;如果在范围内,继续判断子节点,直到找到一个叶子节点包含该坐标;将该地物数据存储到该叶子节点;对每个地物依次重复以上步骤,递归插入四叉树;最终所有地物数据点均递归插入到对应的叶子节点中。从上向下插入,逐级判断空间范围。提前排除不满足的子树分支。将数据存储在包含空间范围的叶子节点。重复插入直到全部地物插入完毕。
18、进一步的,计算每个地物的领域指标,包括:根据四叉树空间索引,以每个地物i为中心,设置搜索半径r;将搜索半径r内的地物作为地物i的相邻地物,并构建地物i的相邻地物集合{n};计算相邻地物集合{n}中每个相邻地物与地物i的欧式距离dist;根据欧式距离dist设置系数weight,系数weight通过如下公式计算:其中,α为距离衰减系数,取值范围0到1;distk表示地物i与相邻地物k之间的欧式距离;根据系数weight计算地物i的领域指标fi;其中,k表示地物i的相邻地物;weightk表示相邻地物k的系数;attrk表示相邻地物k的属性值。
19、具体的,引入距离衰减系数α,可以调节距离的衰减速率。α值越小,表示距离衰减越慢,远距离地物也有一定影响。α值越大,表示距离衰减越快,主要体现近距离地物的影响。通过调节α值,可以实现对距离衰减作用的控制。权重公式计算简单高效,易于实现。权重值体现了距离对相邻地物作用的弱化原则。距离衰减原则符合地理空间分析的基本规律。按照距离赋予权重,计算出的领域指标更具有空间代表性。权重系数weightk起到调节作用,距离近的地物权重更大。attrk反映了每个地物自身的属性特征。权重与属性的乘积进行加总,实现属性合成。最后除以求和的权重,得到规范化的指标结果。计算过程简单高效,易于实现。考虑了周边地物的综合效应,指标值更具代表性。不同地物的领域指标可相互对比,反映空间特征。
20、进一步的,构建各个地物的空间权重矩阵,包括:采集每个地物的空间坐标数据;根据采集的空间坐标数据和领域指标,计算每个地物与测绘数据集中除所述地物以外的其他地物之间的曼哈顿距离;根据计算得到的曼哈顿距离,计算权重值;根据计算得到的权重值,构建空间权重矩阵。
21、其中,首先,需要从测绘数据集中采集每个地物的空间坐标数据。这些坐标数据可以是地物在二维平面上的经纬度坐标,也可以是地物在三维空间中的(x,y,z)坐标。针对每个地物,计算其与测绘数据集中除了自身以外的其他地物之间的曼哈顿距离。曼哈顿距离是一种衡量两点间直角距离的方法,可以通过地物的空间坐标数据计算得出。根据领域指标和计算得到的曼哈顿距离,计算每个地物与其他地物之间的权重值。将计算得到的权重值整理成矩阵形式,构建空间权重矩阵。矩阵的行和列分别代表地物的编号,矩阵中的每个元素表示对应地物之间的权重值。这样的矩阵能够清晰地反映地物之间的空间关联性。
22、进一步的,通过如下公式计算权重值wij:其中,wij表示地物i与地物j之间的权重值,fi和fj分别表示地物i和j的领域指标,g(fi,fj)为将领域指标映射到权重值的转换函数,dij表示地物i与地物j之间的曼哈顿距离。通过如下公式计算曼哈顿距离dij:dij=ki|xi-xj|+kj|yi-yj|,其中,xi、yi表示地物i的坐标,ki为地物i的权重系数,xj、yj表示地物j的坐标,kj为地物j的权重系数。
23、具体的,引入了领域指标到权重的映射函数g(fi,fj),可以根据指标值调整权重。fi和fj综合反映了地物i和j所在区域的空间特征。g函数可以实现根据空间特征自定义权重计算方式。计算地物之间的曼哈顿距离dij,反映空间距离。权重与距离的倒数相关,使得距离近的交互影响更大。转换函数和距离计算相结合,权重值更具空间代表性。权重矩阵体现了地物间的空间相关性。分别计算x、y坐标的差值绝对值。引入权重系数ki和kj,可以加强或弱化坐标差异。权重系数的设定可以根据地物特征自定义。权重系数允许根据场景需求调节距离计算。计算过程简单高效,易于实现。距离计算更全面考虑了地物的空间位置与特征。由于考虑坐标与权重,计算出的距离更符合实际空间关系。有利于构建能够反映空间关联性的权重矩阵。
24、进一步的,通过如下公式计算权重系数ki,ki=w1aip+w2piq+w3f(ti,fi),其中,ai表示地物i的面积,pi表示地物i的周长,ti表示地物i的类型,w1、w2、w3为权重值,分别表示面积、周长和类型的权重;p、q为面积和周长的指数权值,f(ti,fi)表示将类型和领域指标映射到权重值的转换函数;f(ti,fi)表达式如下:其中,λ为地物类型ti的映射系数,ti为地物i类型的数字编码;μ为地物领域指标fi的映射系数;fi为地物i的领域指标。
25、其中,w1、w2是权重值,用于调整面积和周长对权重系数的贡献。这使得在计算权重系数时,可以更加灵活地考虑地物的形状和大小,w3用于调整地物类型对权重系数的贡献。通过这一项的引入,权重系数的计算能够更全面地考虑地物的不同类型。映射函数f(ti,fi)综合考虑了地物类型和领域指标对权重系数的影响。通过指数映射,能够使不同类型和领域指标之间的关系更为显著。映射系数λ和μ可以根据实际问题的需求进行调整,以符合不同类型和领域指标对权重系数的实际影响程度。将类型和领域指标的映射函数值与面积和周长的计算结果结合,得到最终的权重系数ki。通过引入面积、周长、类型和领域指标,权重系数计算能够更全面地考虑地物的多个特征。通过调整权重值和映射系数,能够灵活地适应不同问题的需求,提高了方法的适用性。映射函数综合考虑了类型和领域指标,通过指数映射更为突出不同类型和领域指标对权重系数的影响。
26、进一步的,getisordgi*统计方法计算的局部空间统计值采用标准化值zgij表示;
27、其中,e[gij]表示gi的期望值;var[gij]表示gi的方差;zgij表示地物i的gij值的标准化值;gij表示目标地物i周边预设距离d范围内与地物j的地物属性值聚集程度的统计量;gij通过公式计算:其中,i表示目标地物,j表示目标地物i预设距离d范围内的地物;wij(d)表示地物i与地物j之间的权重值,d为预设的临界距离;attrj表示地物j的属性值。
28、其在,getisordgi*统计方法能够提供对空间数据集中地物聚集程度的有效度量,特别是通过标准化值zgij的引入,可以更好地进行空间聚集性的比较。可以揭示空间上的局部聚集模式,不仅仅提供全局的聚集性信息。虑了地物i与其邻域内地物j之间的空间关系,并根据权重值进行相应的属性值聚集程度计算。采用标准化值zgij可以减轻gi*值的尺度影响,使得不同区域之间的聚集性能够更加直观地进行比较。
29、进一步的,属性值attrk通过如下公式计算:attrk=w4ak+w5pk+w6f(tk),其中,ak表示地物k的面积,pk表示地物k的周长,tk表示地物k的类型,w4、w5、w6为权重值,分别表示面积、周长和类型的权重;f(tk)表示相邻地物类型tk的映射函数;映射函数f(tk)的表达式为:其中,λ为地物类型tk的映射系数,tk为地物k类型的数字编码。
30、其中,属性值的计算考虑了地物的面积和周长的贡献。这使得大面积或周长较大的地物在属性值计算中有更大的影响,属性值的计算能够更全面地考虑地物的不同类型。映射函数f(tk)通过指数映射对地物的类型进行转换。指数映射的形式使得不同类型之间的权重关系呈现指数级别的变化,从而能够更灵活地调整不同类型的贡献。映射系数λ可以根据实际情况进行调整,以符合不同地物类型对属性值的影响程度。将面积、周长和类型的贡献通过权重相加,再结合映射函数,计算得到地物的属性值。这样的计算方式充分考虑了地物的多个特征。考虑了地物的面积、周长和类型等多个维度的属性,使得属性值计算更为全面。通过映射函数,能够灵活地调整不同地物类型对属性值的影响,使得类型之间的关系更加灵活。映射函数采用指数映射,使得不同类型之间的差异更为显著,有助于突出某些特定类型的影响。
31、进一步的,分层聚类算法为k-means分层聚类算法。k-means分层聚类算法是一种聚类分析方法,随机选择k个初始聚类中心。对每个样本,计算到每个聚类中心的距离,将其归到最近的聚类。对每个聚类,重新计算聚类中心的坐标。重复上述步骤,直到聚类中心坐标不再改变。在本技术中,根据地物的局部空间统计值,设定不同的k值。使用k-means算法对地物数据集进行聚类。逐步增大k值,得到不同粒度下的聚类结果。分析不同k值下的聚类结果,得到分层聚类效果。解析地物在不同尺度下的聚集规律。
32、进一步的,多尺度局部空间统计分析方法包括核密度估计。核密度估计(kerneldensityestimation,kde)是一种非参数方式的概率密度函数估计方法。在本技术中,对不同形状聚类后的地物分布,设置不同带宽的核函数。计算每个地物对目标区域周边点x的核函数值。累加核函数值得到点x的密度值。变化核函数带宽,重复计算,得到不同尺度下的核密度估计结果。分析多尺度核密度差异,判断目标区域内的地物分布模式。
33、3.有益效果
34、相比于现有技术,本技术的优点在于:
35、通过四叉树空间索引,提高了测绘数据的检索和插入效率,显著降低了数据处理的复杂度。这使得大规模的地理数据能够被更加迅速、高效地处理;
36、利用领域指标计算和空间权重矩阵构建,能够捕捉地物之间的空间关联关系,从而实现对空间分布特征的更为精准的描述;
37、结合getisordgi*统计方法,能够在空间统计上进行深入分析,评估地物的局部聚集程度,为决策提供更为可靠的统计依据;
38、应用分层聚类算法,能够将地物进行分层聚类,使得相似性较高的地物被归为一类,从而更好地理解地物的分布模式;
39、引入多尺度局部空间统计分析,使得技术方案不仅能够准确刻画局部聚集情况,还能够在不同尺度下揭示地物的多样性,进一步提升了对地理数据的全面理解。
- 还没有人留言评论。精彩留言会获得点赞!