本发明涉及一种超分辨率方法,尤其是一种场景文本图像超分辨率方法。
背景技术:
1、自然场景文本图像中包含着丰富的语义信息,广泛应用于文档识别、自动驾驶和多等领域。然而,场景文本图像中往往存在结构模糊、分辨率较低等问题,导致难以检测。场景文本图像超分辨率(scene text image super resolution,stisr)是解决上述问题的关键技术,它能够有效提升文本图像质量,将低分辨率(low resolution,lr)图像复原为高分辨率(high resolution,hr)图像。
2、当前stisr技术主要分为传统方法和深度学习方法。传统方法依赖于低级特征(如纹理和颜色信息)和人工设计的特征处理器,成本高昂且难以捕捉到高级语义信息,往往无法还原图像中的细节信息,逐渐被研究者摒弃。而基于深度学习的stisr方法能够自动学习图像中的高级特征和语义信息,同时不需要手工设计复杂的特征提取器,这使得模型能够更好地通过深层抽象特征来学习数据的复杂表示,增强表征能力,有助于解决光照、失真等复杂环境下的文本图像超分任务,被业内广泛使用。其中,基于深度学习的stisr技术又分为合成数据集的stisr方法和真实数据集的stisr方法。
3、基于合成数据集的stisr方法流行于深度学习时代早期,其将单图像超分辨率(single image super resolution,sisr)方法应用到场景文本图像,并使用人工合成的数据集进行训练,取得了一定的效果。dong等人首次利用cnn设计出一种单图像超分辨率算法(参考文献:dong c,loy c c,he k,et al.leaming a deep convolutional network forimage super-resolution[c]//computer vision-eccv 2014:13th europeanconference,zurich,switzerland,september 6-12,2014,proceedings,part iv13.springer international publishing,2014:184-199.),较传统算法有巨大提升,但网络结构简单、深度较低,无法有效提取图像高层次信息;为此,tran等人采用拉普拉斯金字塔网络逐步重建sr文本图像(参考文献:tran h t m,ho-phuoc t.deep laplacianpyramid network for text images super-resolution[c]//2019ieee-rivfinternational conference on computing and communication technologies(rivf).ieee,2019:1-6.),深层的金字塔网络能够有效地缓解不同尺度文本图像的超分辨率难题,但面对结构模糊的文本图像时展现出局限性;pandey等人通过学习lr和hr(highresolution)二值文档图像之间的空间对应关系来恢复文本细节(参考文献:pandey r k,vignesh k,ramakrishnan a g.binary document image super resolution forimproved readability and ocr performance[j].arxiv preprint arxiv:1812.02475,2018.),二值化掩码为重建文本图像提供了一定的结构信息,但并未对其进一步利用。尽管上述方法能够恢复部分文本图像细节,但也存在一些明显局限:首先,它们将文本图像视为通用图像,未利用文本图像中关键的结构信息,当分辨率较低时,不仅无法恢复正确的语义信息,甚至破坏原有图像结构;其次,上述方法训练的lr图像是hr图像经高斯模糊、双三次下采样等人工手段获取,与真实lr文本图像存在较大差异。
4、为此,有学者提出了基于真实数据集的stisr方法,解决了合成数据集无法反映真实文本图像细节纹理的问题。较合成stisr数据集而言,真实stisr数据集更能体现现实文本图像多样性、复杂性和泛化性,通过其训练的stisr网络,具有更强的性能和鲁棒性。为了更好的学习图像局部结构,chen等人仅提供笔划级别的注意力图作为位置线索(参考文献:chen j,yu h,ma j,et a1.text gestalt:stroke-aware scene text image super-resolution[c]//proceedings of the aaai conference on artificialintelligence.2022,36(1):285-293.),确保生成sr图像能够关注重要细节,但笔划级别的注意力图未将局部特征与全局特征联合交互,影响文本细节重建。ma等人将cnn和transformer结合使得语义先验与弯曲文本图像对齐(参考文献:ma j,liang z,zhang l.atext attention network for spatial deformation robust scene text image super-resolution[c]//proceedings of the ieee/cvf conference on computer vision andpattern recognition.2022:5911-5920.),提出的结构文本一致性损失增强了模型的鲁棒性,然而,不同尺度的结构特征未有效交互同样使得文本细节无法完好恢复。为了有效利用文本的结构属性,zhu等人在语义先验的基础上拓展,提出了一种双先验调制网络dpmn(参考文献:zhu s,zhao z,fangp,et al.improving scene text image super-resolutionvia dual prior modulation network[j].arxiv preprint arxiv:2302.10414,2023.),初步利用结构先验辅助stisr,通过两种细化模块引导双先验信息,有效提升了文本的结构清晰度和语义准确性,但vit的处理机制仍无法关注重要局部结构特征。
5、综上所述,现有stisr方法取得较好的性能,但仍存在一些不足:首先,stisr需要充分考虑文本图像的整体和细节,而多数stisr方法没有适当考虑文本图像中不同尺度的局部结构特征,导致文本图像在重建过程中缺少局部细节纹理;其次,目前的stisr方法普遍基于深度神经网络,更关注高层次语义信息,忽略了底层特征的误差递增,导致特征丢失,从而出现识别精度低的问题。
技术实现思路
1、本发明所要解决的技术问题是提供一种场景文本图像超分辨率方法,不但提升了场景文本图像超分辨重建能力,而且提高了识别精度。
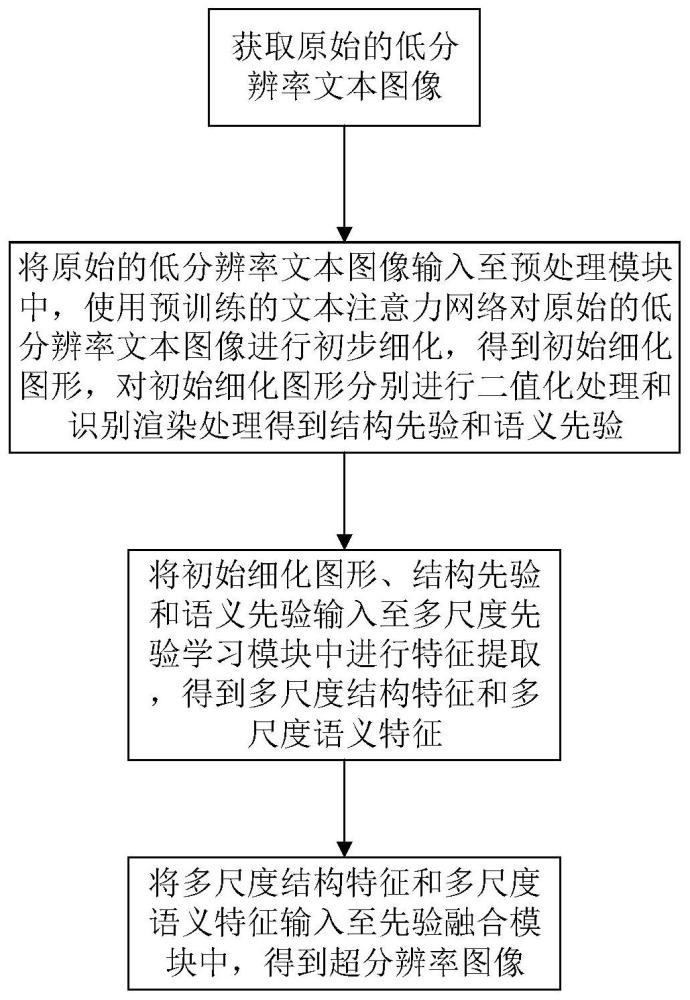
2、本发明解决上述技术问题所采用的技术方案为:一种场景文本图像超分辨率方法,包括以下步骤:步骤①获取原始的低分辨率文本图像;步骤②将原始的低分辨率文本图像输入至预训练的场景文本图像超分辨率网络mspie中,输出超分辨率图像;
3、所述的预训练的场景文本图像超分辨率网络mspie由预处理模块pm、多尺度先验学习模块msplm和先验融合模块pffm组成;
4、所述的步骤②的具体操作过程如下:
5、步骤②-1将原始的低分辨率文本图像输入至预处理模块pm中,使用预训练的文本注意力网络对原始的低分辨率文本图像进行初步细化,得到初始细化图形,对初始细化图形分别进行二值化处理和识别渲染处理得到结构先验和语义先验;
6、步骤②-2将初始细化图形、结构先验和语义先验输入至多尺度先验学习模块msplm中进行特征提取,得到多尺度结构特征和多尺度语义特征;
7、步骤②-3将多尺度结构特征和多尺度语义特征输入至先验融合模块pffm中进行融合,得到超分辨率图像。
8、与现有技术相比,本发明的优点在于通过结构和语义先验特征与初始细化图像的多尺度交互增强,使得先验特征充分学习原始图像特征信息,通过预处理模块pm为后续结构和语义特征交互增强提供指导,通过多尺度先验学习模块msplm使得结构和语义先验不断学习初始细化图像以获取深层原始文本图像特征,以结构先验引导细节恢复,多尺度先验学习模块msplm能够提取结构先验、语义先验和初始细化图像的多尺度结构和语义特征,并通过残差连接的多尺度注意力模块msia促进双先验融合并与初始细化文本图像交互,增强表征能力;通过先验融合模块pffm融合结构和语义特征得到完善先验特征,并与初始细化图像按比例融合输出,提升了场景文本图像超分辨重建能力。在标准数据集textzoom上的实验结果表明,本发明在aster、crnn和moran三种评估器中的平均识别精度分别为64.41%、53.53%和60.83%,比tg方法分别提高了3.12%、4.61%和1.4%,由此可得本发明具有更好的识别精度。
9、进一步的,所述的得到结构先验和语义先验的具体操作过程如下:
10、对初始细化图形进行二值化处理得到结构线索,通过vision transformer使结构线索与初始细化图形进行特征交互得到初步结构先验,对初步结构先验进行pixelshuffle上采样操作得到结构先验,该操作表示为:
11、x=bi(mlr),ms=ps{vit[x,conv1(mlr),conv2(mlr)]},
12、其中,x表示结构线索,bii(·)表示二值化处理,mlr表示原始的低分辨率文本图像,ms表示结构先验,ps(·)表示pixel shuffle上采样操作,vit(·)表示visiontransformer方法,conv1(·)和conv2(·)分别表示vision transformer中1×1卷积操作;
13、通过预训练的文本识别器对初始细化图形进行识别得到识别结果,通过渲染模块将识别结果转换为包含字符的图像格式数据作为语义线索,通过vision transformer使语义线索与初始细化图形进行特征交互得到初步语义先验,对初步语义先验进行pixelshuffle上采样操作得到语义先验,该操作表示为:
14、y=ren{rec(mlr)},mt=ps{vit[y,conv1(mlr),conv2(mlr)]},
15、其中,y表示语义线索,ren(·)表示渲染操作,rec(·)表示识别操作,mlr表示原始的低分辨率文本图像,mt表示语义先验,ps(·)表示pixel shuffle上采样操作,vit(·)表示vision transformer方法,conv1(·)和conv2(·)分别表示vision transformer中1×1卷积操作。
16、进一步的,所述的特征交互为两次1×1卷积操作。
17、进一步的,所述的多尺度先验学习模块msplm由结构细化分支stb和语义细化分支seb组成,所述的结构细化分支stb由采用级联方式连接的三个第一先验融合交互模块组成,所述的语义细化分支seb由采用级联方式连接的三个第二先验融合交互模块组成;
18、得到多尺度结构特征和多尺度语义特征的具体过程如下;
19、第一个所述的第一先验融合交互模块对输入的初始细化图形和结构先验进行处理,输出第一结构特征和第一结构深度特征;
20、第二个所述的第一先验融合交互模块对输入的第一结构特征和第一结构深度特征进行处理,输出第二结构特征和第二结构深度特征;
21、第三个所述的第一先验融合交互模块对输入的第二结构特征和第二结构深度特征进行处理,输出第三结构特征和第二结构深度特征;
22、将所述的第三结构特征作为多尺度结构特征进行输出;
23、第一个所述的第二先验融合交互模块对输入的初始细化图形和语义先验进行处理,输出第一语义特征和第一语义深度特征;
24、第二个所述的第二先验融合交互模块对输入的第一语义特征和第一语义深度特征进行处理,输出第二语义特征和第二语义深度特征;
25、第三个所述的第二先验融合交互模块对输入的第二语义特征和第二语义深度特征进行处理,输出第三语义特征和第三语义深度特征;
26、将所述的第三语义特征作为多尺度语义特征进行输出。采用级联的方式逐步输出更深层次附有初始细化图像信息的结构和语义特征图,最终生成的先验特征图带有丰富的初始细化图像特征,从而更全面的表征先验信息。
27、进一步的,所述的第一先验融合交互模块由共享编码器sen、多尺度注意力模块msia和共享解码器sde三部分通过残差连接构成,所述的共享编码器sen包括5层卷积块,每层卷积块由一个3x3卷积层和一个最大池化层组成,所述的共享解码器sde包括6层共享转置卷积,
28、第一先验融合交互模块中共享编码器sen的具体实现方式为:
29、
30、
31、其中,表示第n个第一先验融合交互模块中第i层卷积块输出的结构细化特征,ms表示结构先验,表示第一个第一先验融合交互模块中第六层共享转置卷积输出的反卷积结构细化特征,表示第二个第一先验融合交互模块中第六层共享转置卷积输出的反卷积结构细化特征,表示第n个第一先验融合交互模块中第i-1层卷积块输出的结构细化特征,表示第n个第一先验融合交互模块中第i层卷积块输出的结构细化图像深度特征,me表示初始细化图形,表示第一个第一先验融合交互模块中第六层共享转置卷积输出的反卷积结构细化图像深度特征,表示第二个第一先验融合交互模块中第六层共享转置卷积输出的反卷积结构细化图像深度特征,表示第n个第一先验融合交互模块中第i-1层卷积块输出的结构细化图像深度特征,conv(·)表示1×1卷积操作,+表示残差连接;
32、使用1×1卷积对经过拼接后的和降维,得到结构精炼特征,该操作表示为:
33、
34、其中,表示第n个第一先验融合交互模块中得到的结构精炼特征,conv(·)表示1×1卷积操作,concat(·)表示拼接操作,表示第n个第一先验融合交互模块中第五层卷积块输出的结构细化图像深度特征,表示第n个第一先验融合交互模块中第五层卷积块输出的结构细化特征;
35、第一先验融合交互模块中多尺度注意力模块msia的具体实现方式为:
36、
37、
38、其中,表示第n个第一先验融合交互模块中多尺度注意力模块msia输出的结构先验特征,表示第n个第一先验融合交互模块中第五层卷积块输出的结构细化特征,βn,a表示第一注意力权重,表示第n个第一先验融合交互模块中得到的结构精炼特征,表示第n个第一先验融合交互模块中多尺度注意力模块msia输出的结构深度先验特征,表示第n个第一先验融合交互模块中第五层卷积块输出的结构细化图像深度特征,βn,b表示第二注意力权重;
39、βn,a=conv{mlp[averagepool(as)]}+conv(as),
40、βn,b=conv{mlp[averagepool(be)]}+conv(be),
41、其中,conv(·)表示1×1卷积操作,mlp(·)表示多层感知机操作,averagepool(·)表示全局平均池化操作,as表示结构学习样本,be表示细化图像特征样本;
42、
43、
44、其中,concat(·)表示拼接操作,表示第n个第一先验融合交互模块中第五层卷积块输出的结构细化特征,表示第n个第一先验融合交互模块中得到的结构精炼特征,表示第n个第一先验融合交互模块中第五层卷积块输出的结构细化图像深度特征;
45、第一先验融合交互模块中共享解码器sde的具体实现方式为:
46、
47、
48、其中,表示第n个第一先验融合交互模块中第j层共享转置卷积输出的反卷积结构细化特征,deconv(·)表示转置卷积操作,表示第n个第一先验融合交互模块中多尺度注意力模块msia输出的结构先验特征,concat(·)表示拼接操作,表示第n个第一先验融合交互模块中第j-1层共享转置卷积输出的反卷积结构细化特征,表示第n个第一先验融合交互模块中第i层卷积块输出的结构细化特征,ms表示结构先验,表示第n个第一先验融合交互模块中第j层共享转置卷积输出的反卷积结构细化图像深度特征,表示第n个第一先验融合交互模块中多尺度注意力模块msia输出的结构深度先验特征,表示第n个第一先验融合交互模块中第j-1层共享转置卷积输出的反卷积结构细化图像深度特征,表示第n个第一先验融合交互模块中第i层卷积块输出的结构细化图像深度特征,me表示初始细化图形。对ms和me提取深度特征,使得不同尺度深度特征交互融合,充分挖掘场景文本图像的全局与局部信息;3x3卷积核能够有效提取足够的局部特征,在保留最优特征的同时降低参数量,此外,不同尺度特征通过残差连接既可以缓解特征信息丢失的问题,也能够增强文本图像的局部结构特征;通过msia生成的注意力权重感知不同尺度结构特征图中的位置细节,使得网络高效关注图像重要结构细节,有效引导结构先验的特征提取;通过不同转置卷积层的输出与对应维度的编码端输出特征融合,实现不同尺度多层次的局部结构信息交互,在解码过程中更好地重现文本的纹理结构。
49、进一步的,所述的第二先验融合交互模块由共享编码器sen、多尺度注意力模块msia和共享解码器sde三部分通过残差连接构成,所述的共享编码器sen包括5层卷积块,每层卷积块由一个3x3卷积层和一个最大池化层组成,所述的共享解码器sde包括6层共享转置卷积,
50、第二先验融合交互模块中共享编码器sen的具体实现方式为:
51、
52、
53、其中,表示第m个第二先验融合交互模块中第k层卷积块输出的语义细化特征,mt表示语义先验,表示第一个第二先验融合交互模块中第六层共享转置卷积输出的反卷积语义细化特征,表示第二个第二先验融合交互模块中第六层共享转置卷积输出的反卷积语义细化特征,表示第m个第二先验融合交互模块中第k-1层卷积块输出的语义细化特征,表示第m个第二先验融合交互模块中第k层卷积块输出的语义细化图像深度特征,me表示初始细化图形,表示第一个第二先验融合交互模块中第六层共享转置卷积输出的反卷积语义细化图像深度特征,表示第二个第二先验融合交互模块中第六层共享转置卷积输出的反卷积语义细化图像深度特征,表示第m个第二先验融合交互模块中第k-1层卷积块输出的语义细化图像深度特征,conv(·)表示1×1卷积操作,+表示残差连接;
54、使用1×1卷积对经过拼接后的和降维,得到语义精炼特征,该操作表示为:
55、其中,表示第m个第二先验融合交互模块中得到的语义精炼特征,conv(·)表示1×1卷积操作,concat(·)表示拼接操作,表示第m个第二先验融合交互模块中第五层卷积块输出的语义细化图像深度特征,表示第m个第二先验融合交互模块中第五层卷积块输出的语义细化特征;
56、第二先验融合交互模块中多尺度注意力模块msia的具体实现方式为:
57、
58、
59、其中,表示第m个第二先验融合交互模块中多尺度注意力模块msia输出的语义先验特征,表示第m个第二先验融合交互模块中第五层卷积块输出的语义细化特征,βn,c表示第三注意力权重,表示第m个第二先验融合交互模块中得到的语义精炼特征,表示第m个第二先验融合交互模块中多尺度注意力模块msia输出的语义深度先验特征,表示第m个第二先验融合交互模块中第五层卷积块输出的语义细化图像深度特征,βn,d表示第四注意力权重;
60、βn,c=conv{mlp[averagepool(ct)]}+conv(ct),
61、βn,d=conv{mlp[averagepool(de)]}+conv(de),
62、其中,conv(·)表示1×1卷积操作,mlp(·)表示多层感知机操作,averagepool(·)表示全局平均池化操作,ct表示结构学习样本,be表示细化图像特征样本;
63、
64、
65、其中,concat(·)表示拼接操作,表示第m个第二先验融合交互模块中第五层卷积块输出的语义细化特征,表示第m个第二先验融合交互模块中得到的语义精炼特征,表示第m个第二先验融合交互模块中第五层卷积块输出的语义细化图像深度特征;
66、第二先验融合交互模块中共享解码器sde的具体实现方式为:
67、
68、
69、其中,表示第m个第二先验融合交互模块中第l层共享转置卷积输出的反卷积语义细化特征,deconv(·)表示转置卷积操作,表示第m个第二先验融合交互模块中多尺度注意力模块msia输出的语义先验特征,concat(·)表示拼接操作,表示第m个第二先验融合交互模块中第l-1层共享转置卷积输出的反卷积语义细化特征,表示第m个第二先验融合交互模块中第k层卷积块输出的语义细化特征,mt表示语义先验,表示第m个第二先验融合交互模块中第l层共享转置卷积输出的反卷积语义细化图像深度特征,表示第m个第二先验融合交互模块中多尺度注意力模块msia输出的语义深度先验特征,表示第m个第二先验融合交互模块中第l-1层共享转置卷积输出的反卷积语义细化图像深度特征,表示第m个第二先验融合交互模块中第k层卷积块输出的语义细化图像深度特征,me表示初始细化图形。通过msia生成的注意力权重感知不同尺度语义特征图中的位置细节,使得网络高效关注图像重要语义细节,有效引导语义先验的特征提取。
70、进一步的,所述的步骤②-3的具体操作过程如下:
71、步骤②-3-1将多尺度结构特征依次输入至共享编码器sen和多尺度注意力模块msia中,得到增强后的结构特征,将多尺度语义特征依次输入至共享编码器sen和多尺度注意力模块msia中,得到增强后的语义特征,该操作表示为:
72、
73、其中,pe表示增强后的结构特征,msia(·)表示多尺度注意力模块操作,sen(·)表示共享编码器操作,表示多尺度结构特征,qe表示增强后的语义特征,表示多尺度语义特征;
74、步骤②-3-2将依次经过多层感知机mlp、双向长短期记忆神经网络blstm和共享解码器sde的增强后的结构特征与依次经过多层感知机、blstm层和共享解码器sde的增强后的语义特征通过逐元素相加方式进行融合,得到初步超分辨率图像,该操作表示为:
75、m0=sde{blstm[mlp(pe)]}+sde{blstm[mlp(qe)]},
76、其中,m0表示初步超分辨率图像,sde(·)表示共享解码器操作,blstm(·)表示双向长短期记忆神经网络操作,mlp(·)表示多层感知机操作,pe表示增强后的结构特征,+表示逐元素相加方式,qe表示增强后的语义特征;
77、步骤②-3-3将初始细化图形与初步超分辨率图像按预设的比例融合得到超分辨率图像,该操作表示为:
78、msr=me×(1-α)+m0×α,
79、其中,msr表示超分辨率图像,me表示初始细化图形,mo表示初步超分辨率图像,α表示预设的融合比例系数,α=0.6。双向长短期记忆神经网络blstm用于捕捉先验特征之间的长期依赖关系以及丰富上下文信息,增强局部结构之间的关联性,也缓解了深度神经网络中的梯度消失问题,多层感知机mlp用于增加网络的非线性处理能力。
80、进一步的,所述的预训练的场景文本图像超分辨率网络mspie的训练过程如下:
81、从公开的textzoom数据集中随机选取至少17367对lr-hr场景文本图像;
82、将至少17367对lr-hr场景文本图像中的lr场景文本图像的大小均裁剪为16×64以及hr场景文本图像的大小均裁剪为32×128,将裁剪后的lr场景文本图像和hr场景文本图像作为训练集;
83、设置训练参数包括:初始学习率设置为0.005,batch-size大小设置为48;
84、将训练集输入至待训练的场景文本图像超分辨率网络mspie中进行训练;
85、定义待训练的场景文本图像超分辨率网络mspie的损失函数为ltotal=lplm+lpff,其中,ltotal表示待训练的场景文本图像超分辨率网络mspie的损失函数,lplm表示多尺度先验学习模块msplm的损失函数,表示像素损失函数,表示梯度轮廓损失损失函数,lpff表示先验融合模块pffm的损失函数,mhr表示hr场景文本图像,表示梯度值,msr表示超分辨率图像;
86、设置最大迭代次数为30,根据损失函数,使用adam优化器对待训练的有向目标检测网络进行迭代优化,直到达到设置的最大迭代次数时,停止迭代过程,得到预训练的场景文本图像超分辨率网络mspie。采用像素损失(pixel-wise loss)和梯度轮廓损失(gradient profile loss)两个级损失函数来促进网络的训练,像素损失通过最小化像素级差异,保持生成图像与目标图像之间的内容一致性,使得生成图像准确重建目标图像的细节纹理信息;梯度轮廓损失通过考虑边缘信息的一致性,最小化生成图像与目标图像之间的边缘细节差异,有助于提高生成图像的细节清晰度和轮廓准确性。
- 该技术已申请专利。仅供学习研究,如用于商业用途,请联系技术所有人。
- 技术研发人员:朱仲杰,张磊,白永强,李沛,卢豫哲
- 技术所有人:浙江万里学院
- 我是此专利的发明人
- 该领域下的技术专家
- 如您需求助技术专家,请点此查看客服电话进行咨询。
- 1、李老师:1.计算力学 2.无损检测
- 2、毕老师:机构动力学与控制
- 3、袁老师:1.计算机视觉 2.无线网络及物联网
- 4、王老师:1.计算机网络安全 2.计算机仿真技术
- 5、王老师:1.网络安全;物联网安全 、大数据安全 2.安全态势感知、舆情分析和控制 3.区块链及应用
- 如您是高校老师,可以点此联系我们加入专家库。
- 还没有人留言评论。精彩留言会获得点赞!