一种用电数据异常值检测方法及系统与流程
本发明属于电负荷异常数据辨识,具体涉及一种用电数据异常值检测方法、系统及终端设备。
背景技术:
1、在智能电网环境中,高级计量基础设施和智能传感器已被广泛部署。因此,大规模和细粒度的智能电网数据更易收集,其中异常值普遍存在,由系统故障、环境影响和人为干预引起。异常值删除始终在数据预处理中实现,以提高数据质量。异常值数据是与整体数据分布无关的异常值。噪声等异常数据会降低数据质量,并对基于电力数据的“电-能-碳”关系模型的性能产生不利影响。然而,由于反应罕见和不寻常模式的真实记录也被认为是异常值,因此有必要进行异常值的检测,将被误认为是异常值的数据剔除。
2、现有的电力数据异常值检测方法可分为三类:基于人工智能、基于状态和基于博弈论。然而,基于人工智能的检测方法需要大量带有标记的历史用电数据来训练模型,因此在像异常用户比例小这种数据集不平衡的情况下检测精度较低;基于状态的检测方法需要精确的网络拓扑和参数信息,不然难以检测出重叠的异常值,而这些信息在最终用户级别是不可用的;基于博弈论的检测方法主要侧重于具有强假设的理论分析,在实际情况中上较少应用,不具备工程实用性。因此,有必要研究一种能异常值比例小的数据集中准确识别出异常值,并避免重叠异常值情况的方法。
技术实现思路
1、本发明提出了一种用电数据异常值检测方法、系统及终端设备,即使在异常值比例小的数据集中也能准确检测出重叠的异常值,并无需其他附加数据的辅助,提升了异常值识别的准确性和计算效率。
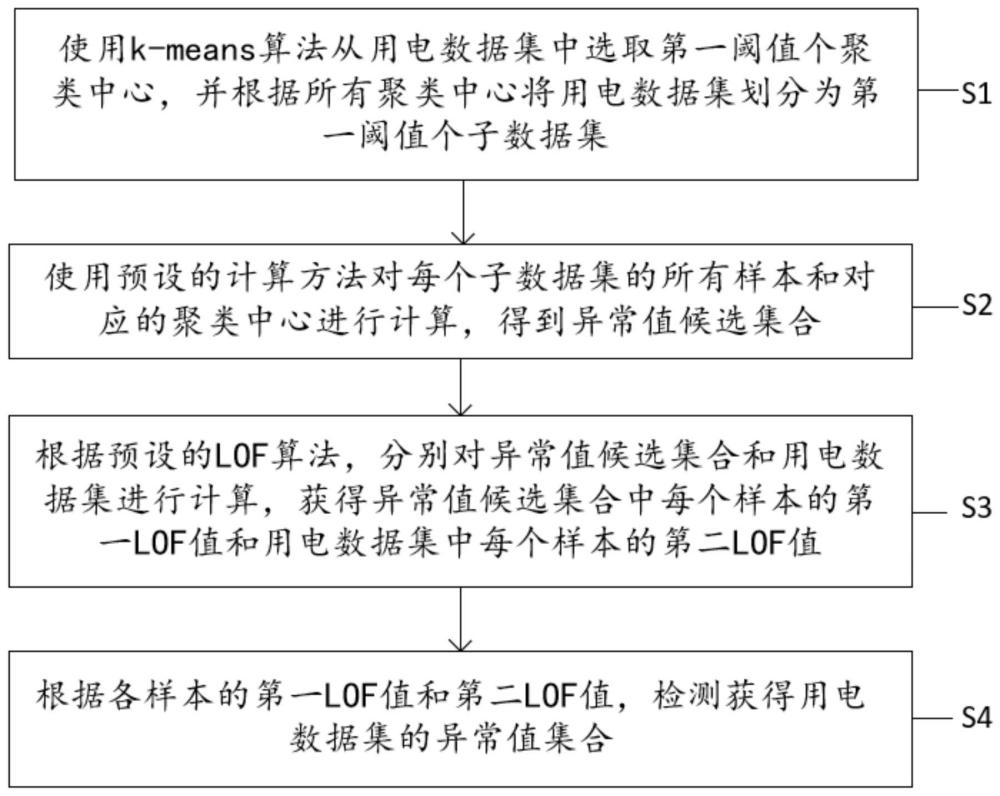
2、本发明的第一方面提供了一种用电数据异常值检测方法,所述方法包括:
3、使用k-means算法从用电数据集中选取第一阈值个聚类中心,并根据所有聚类中心将用电数据集划分为第一阈值个子数据集;其中,所述用电数据集采集自目标用户的历史用电数据,第一阈值的大小由所述用电数据集的数据量决定;每个子数据集都有一个聚类中心;
4、使用预设的计算方法对每个子数据集的所有样本和对应的聚类中心进行计算,得到异常值候选集合;
5、根据预设的lof算法,分别对异常值候选集合和用电数据集进行计算,获得异常值候选集合中每个样本的第一lof值和用电数据集中每个样本的第二lof值;
6、根据各样本的第一lof值和第二lof值,检测获得用电数据集的异常值集合。
7、上述方案先使用k-means算法将用电数据集进行聚类,划分为多个子数据集,再对子数据集和对应的的聚类中心进行计算得到一个异常值候选集合;使用预设的lof算法分别对异常值候选集合和用电数据集进行计算,并对计算结果进行排序,得到最终的用电数据的异常值集合。其中计算数据的lof值有助于在异常值比例较小的数据集中准确识别出异常值;而通过k-means算法聚类数据能有效地检测出重叠的离群值,实现了即使在异常值比例小的数据集中也能准确检测出重叠的异常值,而且在检测过程中没有任何其他数据的辅助,提升了异常值识别的准确性和计算效率。
8、在第一方面的一种可能的实现方式中,使用预设的计算方法对每个子数据集的所有样本和对应的聚类中心进行计算,得到异常值候选集合,具体为:
9、根据预设的计算方法对所有子数据集进行计算,得到所有子数据集中每个样本的第一距离;其中,所述第一距离为子数据集中的样本和对应的聚类中心的欧式距离;
10、根据所有子数据集中每个样本的第一距离,通过预设的异常值筛选方法得到每个子数据集的异常值数据集;
11、根据每个子数据集的异常值数据集,得到异常值候选集合。
12、上述方案通过计算子数据集中每个样本和对应的聚类中心的欧式距离,然后通过预设的异常值筛选方法符合计算精度要求的异常值候选集合,为后续计算lof值提供数据支撑。
13、在第一方面的一种可能的实现方式中,第一距离,每个子数据集的异常值数据集和异常值候选集合,具体为:
14、所述第一距离dist,具体公式为:
15、
16、其中,为第j个子数据集的第i个样本,xj为第j个子数据集的聚类中心,‖·‖2为二范数计算;
17、所述异常值数据集,具体公式为:
18、
19、其中,为第j个子数据集的异常值数据集,为第j个子数据集的三倍标准偏差,dj为第j个子数据集,d为用电数据集,ε为实际异常值的比率;
20、异常值候选集合具体表达式为:
21、
22、其中,为第k个子数据集的异常值数据集。
23、在第一方面的一种可能的实现方式中,根据预设的lof算法,分别对异常值候选集合和用电数据集进行计算,获得异常值候选集合中每个样本的第一lof值和用电数据集中每个样本的第二lof值,具体为:
24、分别对异常值候选集合和用电数据集中的样本进行计算,得到异常值候选集合中所有样本的局部可达密度和用电数据集中所有样本的局部可达密度;
25、根据异常值候选集合中所有样本的局部可达密度和用电数据集中所有样本的局部可达密度,通过预设的lof算法分别得到异常值候选集合中每个样本的第一lof值和用电数据集中每个样本的第二lof值。
26、在第一方面的一种可能的实现方式中,分别对异常值候选集合和用电数据集中的样本进行计算,得到异常值候选集合中所有样本的局部可达密度和用电数据集中所有样本的局部可达密度,具体为:
27、计算异常值候选集合中每个样本和其他样本的之间的可达距离,并从每个样本的可达距离中筛选得到第二阈值个最短的可达距离;
28、根据第二阈值个最短的可达距离对应的其他样本,得到异常值候选集合中每个样本的近邻集合;其中所述近邻集合由第二阈值个最短的可达距离对应的其他样本组成;
29、计算用电数据集中每个样本和其他样本的之间的可达距离,并从每个样本的可达距离中筛选得到第三阈值个最短的可达距离;
30、根据第三阈值个最短的可达距离对应的其他样本,得到用电数据集中每个样本的近邻集合;
31、根据异常值候选集合和用电数据集中每个样本的近邻集合,得到异常值候选集合中所有样本的局部可达密度和用电数据集中所有样本的局部可达密度。
32、上述方案先通过可达距离查找每个样本距离最近的其他样本,再根据每个样本的近邻数据集合计算样本的局部可达密度,然后通过所述局部可达密度得到样本的lof值,实现通过样本的近邻点来量化样本的离群程度,以样本的离群程度来判断是否为异常值,完成在异常值比例较小的数据集中准确找到离群值(异常值)。
33、在第一方面的一种可能的实现方式中,局部可达密度和lof值,具体为:
34、所述第一样本x和第二样本y之间的可达距离rd(x,y),具体公式为:
35、rd(x,y)=max{dist(x,y),distn(y)}
36、其中,dist(x,y)为x和y的欧氏距离,distn(y)为用电数据集中样本到y的第n个最近的距离;
37、所述第一样本x的局部可达密度ρn(x),具体公式为:
38、
39、其中,n为x的近邻数据集合中样本总数,nn(x)为x的近邻数据集合;
40、所述第一样本x的lof值lofn(x),具体公式为:
41、
42、其中,ρn(y)为y的局部可达密度。
43、在第一方面的一种可能的实现方式中,根据各样本的第一lof值和第二lof值,检测获得用电数据集的异常值集合,具体为:
44、在用电数据集中,根据所述样本的第一lof值,通过预设的排序方式对属于异常值候选集合的每个样本进行排序,确定异常值候选集合在用电数据集中排序最低的样本,并记该样本为最低异常值样本;
45、在用电数据集中,根据用电数据集中每个样本的第二lof值,在用电数据集中通过预设的排序方式对不属于异常值候选集合的每个样本进行排序;
46、如果存在不属于异常值候选集合的某个样本的排序大于最低异常值样本的排序,则将该不属于异常值候选集合的样本添加到异常值候选集合中;
47、如果不存在不属于异常值候选集合的某个样本的排序大于最低异常值样本的排序,则将当前的异常值候选集合作为最终的用电数据集的异常值集合。
48、上述方案按照预设的排序方式在用电数据集中对异常值候选集合和非异常值候选集合得样本进行排序,将之前未能筛选出来的放入到异常值候选集合的重叠的异常值查找出来,提升检测异常值的准确性。
49、本发明第二方面提供了一种用电数据异常值检测系统,所述系统包括:数据集划分模块,异常值筛选模块,lof值计算模块和异常值筛选模块;
50、所述数据集划分模块,用于使用k-means算法从用电数据集中选取第一阈值个聚类中心,并根据所有聚类中心将用电数据集划分为第一阈值个子数据集;其中,所述用电数据集采集自目标用户的历史用电数据,第一阈值的大小由所述用电数据集的数据量决定;每个子数据集都有一个聚类中心;
51、所述异常值筛选模块,用于使用预设的计算方法对每个子数据集的所有样本和对应的聚类中心进行计算,得到异常值候选集合;
52、所述lof值计算模块,用于根据预设的lof算法,分别对异常值候选集合和用电数据集进行计算,获得异常值候选集合中每个样本的第一lof值和用电数据集中每个样本的第二lof值;
53、所述异常值筛选模块,用于根据各样本的第一lof值和第二lof值,检测获得用电数据集的异常值集合。
54、在第二方面的一种可能的实现方式中,异常值筛选模块包括:候选异常值筛选单元;
55、所述候选异常值筛选单元,用于根据预设的计算方法对所有子数据集进行计算,得到所有子数据集中每个样本的第一距离;其中,所述第一距离为子数据集中的样本和对应的聚类中心的欧式距离;根据所有子数据集中每个样本的第一距离,通过预设的异常值筛选方法得到每个子数据集的异常值数据集;根据每个子数据集的异常值数据集,得到异常值候选集合。
56、在第二方面的一种可能的实现方式中,lof值计算模块包括:lof值计算单元;
57、所述lof值计算单元,用于分别对异常值候选集合和用电数据集中的样本进行计算,得到异常值候选集合中所有样本的局部可达密度和用电数据集中所有样本的局部可达密度;根据异常值候选集合中所有样本的局部可达密度和用电数据集中所有样本的局部可达密度,通过预设的lof算法分别得到异常值候选集合中每个样本的第一lof值和用电数据集中每个样本的第二lof值。
58、在第二方面的一种可能的实现方式中,lof值计算单元包括:局部可达密度计算单元;
59、所述局部可达密度计算单元,用于计算异常值候选集合中每个样本和其他样本的之间的可达距离,并从每个样本的可达距离中筛选得到第二阈值个最短的可达距离;
60、根据第二阈值个最短的可达距离对应的其他样本,得到异常值候选集合中每个样本的近邻集合;其中所述近邻集合由第二阈值个最短的可达距离对应的其他样本组成;
61、计算用电数据集中每个样本和其他样本的之间的可达距离,并从每个样本的可达距离中筛选得到第三阈值个最短的可达距离;
62、根据第三阈值个最短的可达距离对应的其他样本,得到用电数据集中每个样本的近邻集合;
63、根据异常值候选集合和用电数据集中每个样本的近邻集合,得到异常值候选集合中所有样本的局部可达密度和用电数据集中所有样本的局部可达密度。
64、在第二方面的一种可能的实现方式中,异常值筛选模块包括:重叠异常值筛选单元;
65、所述重叠异常值筛选单元,用于在用电数据集中,根据所述样本的第一lof值,通过预设的排序方式对属于异常值候选集合的每个样本进行排序,确定异常值候选集合在用电数据集中排序最低的样本,并记该样本为最低异常值样本;
66、在用电数据集中,根据用电数据集中每个样本的第二lof值,在用电数据集中通过预设的排序方式对不属于异常值候选集合的每个样本进行排序;
67、如果存在不属于异常值候选集合的某个样本的排序大于最低异常值样本的排序,则将该不属于异常值候选集合的样本添加到异常值候选集合中;
68、如果不存在不属于异常值候选集合的某个样本的排序大于最低异常值样本的排序,则将当前的异常值候选集合作为最终的用电数据集的异常值集合。
- 还没有人留言评论。精彩留言会获得点赞!