一种视频信息分析方法及装置、电子设备、存储介质与流程
本技术涉及视频处理,特别涉及一种视频信息分析方法及装置、电子设备、存储介质。
背景技术:
1、当前,对于电影、电视剧等视频内容在上线前,都需要进行严格的审核,即都需要进行审片,所以审片业务是电影、电视剧等媒体制作行业的重要环节。
2、当前的审片业务主要是通过系统将待审的视频内容分发给相应的工作人员,由工作人员播放待审的视频内容,对授权播放方面的审核项目进行审核,或者借助一些简单的工具,通过人工不断操作,对待审的视频内容进行审核,确定视频内容可以授权播放。若审核未通过,还需要将视频内容返给负责剪辑的工作进行剪辑调整。
3、但是这种方式各项审核的信息,都需要人工去确定,所以效率相对较低,并且这种方式主要关注的授权方面的需求,并且与剪辑业务割裂,即只提供审核结果,无法为剪辑提供调整的准确依据信息,导致无法快速、准确地对视频内容进行调整,需要剪辑人员根据问题,确定相应的信息,再依据这些信息进行调整,因此需要重复进行多次,从而进一步影响的审片的效率,拖延的视频内容的上线时间。
技术实现思路
1、基于上述现有技术的不足,本技术提供了一种视频信息分析方法及装置、电子设备、存储介质,以解决现有技术审片效率较低的问题。
2、为了实现上述目的,本技术提供了以下技术方案:
3、本技术第一方面提供了一种视频信息分析方法,包括:
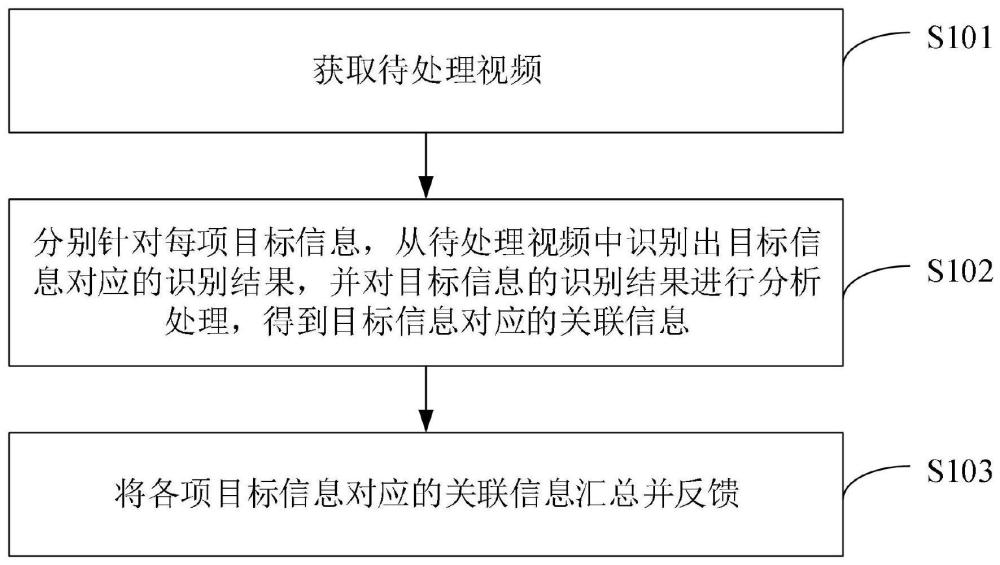
4、获取待处理视频;
5、分别针对每项目标信息,从所述待处理视频中识别出所述目标信息对应的识别结果,并对所述目标信息的识别结果进行分析处理,得到所述目标信息对应的关联信息;其中,所述目标信息包括文字信息、角色信息以及场景信息;所述文字信息对应的识别结果包括从所述待处理视频的多帧视频帧中识别出的各个部分文字的文字识别结果及其位置信息;所述文字识别结果的位置信息用于过滤掉所述文字识别结果中的边缘文字;所述角色信息对应的识别结果包括从所述待处理视频的多帧视频帧中识别出的角色脸部信息;所述场景信息对应的识别结果包括从所述待处理视频的各个分镜中识别出的分镜内容信息;
6、将各项所述目标信息对应的关联信息汇总并反馈。
7、可选地,在上述的视频信息分析方法中,所述目标信息为所述文字信息,所述从所述待处理视频中识别出所述目标信息对应的识别结果,并对所述目标信息的识别结果进行分析处理,得到所述目标信息对应的关联信息,包括:
8、按照预设时间间隔对所述待处理视频进行视频帧提取,得到多帧字幕视频帧;
9、分别对每帧所述字幕视频帧进行文本信息识别,得到每帧所述字幕视频帧的各部分文字的所述文字识别结果及每个所述文字识别结果的位置信息;
10、分别基于各个所述文字识别结果的位置信息,确定出边缘文字并将所述边缘文字移除;
11、分别将同一帧所述字幕视频帧的各个所述文字识别结果进行合并;
12、基于每两帧所述字幕视频帧的所述文字识别结果之间相似度,对各个所述文字识别结果进行去重;
13、使用文本纠错模型对去重后的各个所述文字识别结果进行处理,得到文本纠错结果,以及通过匹配的方式,确定出所述文字识别结果中的敏感词以及特殊字符信息;其中,所述特殊字符信息包括所述文字识别结果中的特殊字符及其索引位置。
14、可选地,在上述的视频信息分析方法中,所述分别基于各个所述文字识别结果的位置信息,确定出边缘文字并将所述边缘文字移除,包括:
15、分别利用每个所述文字识别结果的位置信息中的左边缘坐标和右边缘坐标,计算得到每个所述文字识别结果的纵向中心坐标,以及利用每个所述文字识别结果的位置信息中的顶部坐标和底部坐标,计算得到每个所述文字识别结果的横向中心坐标;
16、将所述横向中心坐标大于所述待处理视频的高度与预设横向阈值的乘积,且所述纵向中心坐标大于所述待处理视频的宽度与预设纵向阈值的乘积的各个所述文字识别结果作为所述边缘文字并移除;
17、将当前剩余的各个所述文字识别结果,基于各个所述文字识别结果的纵向中心坐标进行聚类,得到纵向聚类中心以及纵向中心均值;
18、将所述纵向中心坐标与所述纵向聚类中心的差值的绝对值大于所述纵向中心均值与纵向聚类阈值的乘积的各个所述文字识别结果作为所述边缘文字并移除;
19、将当前剩余的各个所述文字识别结果,基于各个所述文字识别结果的横向中心坐标进行聚类,得到横向聚类中心以及横向中心均值;
20、将所述横向中心坐标与所述横向聚类中心的差值的绝对值大于所述横向中心均值与横向聚类阈值的乘积的各个所述文字识别结果作为所述边缘文字并移除。
21、可选地,在上述的视频信息分析方法中,所述目标信息为所述角色信息,所述从所述待处理视频中识别出所述目标信息对应的识别结果,并对所述目标信息的识别结果进行分析处理,得到所述目标信息对应的关联信息,包括:
22、按照预设时间间隔对所述待处理视频进行视频帧提取,得到多帧脸部视频帧;
23、通过脸部识别模型分别对各帧所述脸部视频帧进行脸部识别,得到各帧所述脸部视频帧中的各个角色的脸部特征;
24、将各帧所述脸部视频帧中的各个所述角色的脸部特征与目标角色脸部库中的脸部特征进行匹配,得到各个所述脸部视频帧中的各个所述目标角色的脸部特征;
25、基于各个所述目标角色的脸部特征,统计每个所述目标角色的出现时长;
26、按照出现时长从大到小的顺序,对各个所述目标角色进行排序;
27、计算排序在前n位的各个所述目标角色中的每两个所述目标角色在所述待处理视频中的交并比;
28、确定出在所述待处理视频中的交并比最高的两个所述目标角色。
29、可选地,在上述的视频信息分析方法中,所述计算排序在前n位的各个所述目标角色中的每两个所述目标角色在所述待处理视频中的交并比,包括:
30、对所述待处理视频进行分镜分割,得到个视频分镜;
31、分别针对排序在前n位的各个所述目标角色,基于所述目标角色在每个所述视频分镜中是否出现,生成所述目标角色的出场列表;其中,所述出场列表的维度等于所述视频分镜的数量,且所述出场列表的各个数值中的第一数值表示对应的所述视频分镜中出现所述目标角色,第二数值表示对应的所述视频分镜中未出现所述目标角色;
32、将每两个所述目标角色的出场列表的交集除以,两个所述目标角色的出场列表的并集,得到每两个所述目标角色的交并比。
33、可选地,在上述的视频信息分析方法中,所述目标信息为所述场景信息,所述从所述待处理视频中识别出所述目标信息对应的识别结果,并对所述目标信息的识别结果进行分析处理,得到所述目标信息对应的关联信息,包括:
34、对所述待处理视频进行分镜分割,得到多个视频分镜;
35、分别从每个所述视频分镜的多帧视频帧中提取出多维特征向量,组成每个所述视频分镜的特征向量;
36、基于各个所述视频分镜的特征向量,计算每两个相邻的所述视频分镜的相似度;
37、将相似度大于第一预设阈值的所述视频分镜进行合并;
38、分别利用违规内容检测模型对当前的每个所述视频分镜进行逐秒检测,得到每个所述视频分镜的检测结果;
39、对检测结果超过检测阈值的所述视频分镜进行标记;
40、确定出当前的各个所述视频分镜中的目标分镜组以及相似分镜组,并将所述目标分镜组以及相似分镜组中的各个所述视频分镜进行组合;其中,所述目标分镜组由相邻的三个所述视频分镜组成,且中间的所述视频分镜的时长小于第一预设时长,其余两个所述视频分镜的相似度大于相似度阈值;所述相似分镜组由相似度大于相似度阈值的两个相邻的所述分镜视频组成;
41、将时长超过第二预设时长的所述视频分镜标记为单一重复场景;
42、根据当前的各个所述视频分镜的时长和相似度,确定出冗余分镜并标记。
43、可选地,在上述的视频信息分析方法中,所述确定出当前的各个所述视频分镜中的目标分镜组以及相似分镜组,并将所述目标分镜组以及相似分镜组中的各个所述视频分镜进行组合,包括:
44、按照在所述待处理视频中的时间顺序,将当前的各个所述视频分镜进行排序;
45、按照排列顺序依次遍历每个所述视频分镜,并将当前遍历到的所述视频分镜确定为当前分镜;
46、若所述当前分镜未属于任意一个所述目标分镜组和所述相似分级组,则判断所述当前分镜的下一个所述视频分镜的时长是否小于所述第一预设时长;
47、若判断出所述当前分镜的下一个所述视频分镜的时长小于所述第一预设时长,则判断所述当前分镜与排序在其后的第二位的所述视频分镜的相似度是否大于相似度阈值;
48、若判断出所述当前分镜与排序在其后的第二位的所述视频分镜的相似度大于相似度阈值,则将所述当前分镜以及排序在其后的第一位和第二位的所述视频分镜作为一组所述目标分镜组并进行合并;
49、若判断出所述当前分镜的下一个所述视频分镜的时长不小于所述第一预设时长,则判断所述当前分镜与下一个所述视频分镜的相似度是否大于相似度阈值;
50、若判断出所述当前分镜与下一个所述视频分镜的相似度大于相似度阈值,则将所述当前分镜和下一个所述视频分镜作为一组所述相似分镜组并进行合并。
51、本技术第二方面提供了一种视频信息分析装置,包括:
52、获取单元,用于获取待处理视频;
53、分析单元,用于分别针对每项目标信息,从所述待处理视频中识别出所述目标信息对应的识别结果,并对所述目标信息的识别结果进行分析处理,得到所述目标信息对应的关联信息;其中,所述目标信息包括文字信息、角色信息以及场景信息;所述文字信息对应的识别结果包括从所述待处理视频的多帧视频帧中识别出的各个部分文字的文字识别结果及其位置信息;所述文字识别结果的位置信息用于过滤掉所述文字识别结果中的边缘文字;所述角色信息对应的识别结果包括从所述待处理视频的多帧视频帧中识别出的角色脸部信息;所述场景信息对应的识别结果包括从所述待处理视频的各个分镜中识别出的分镜内容信息;
54、反馈单元,用于将各项所述目标信息对应的关联信息汇总并反馈。
55、可选地,在上述的视频信息分析装置中,所述目标信息为所述文字信息时,所述分析单元执行所述从所述待处理视频中识别出所述目标信息对应的识别结果,并对所述目标信息的识别结果进行分析处理,得到所述目标信息对应的关联信息,用于:
56、按照预设时间间隔对所述待处理视频进行视频帧提取,得到多帧字幕视频帧;
57、分别对每帧所述字幕视频帧进行文本信息识别,得到每帧所述字幕视频帧的各部分文字的所述文字识别结果及每个所述文字识别结果的位置信息;
58、分别基于各个所述文字识别结果的位置信息,确定出边缘文字并将所述边缘文字移除;
59、分别将同一帧所述字幕视频帧的各个所述文字识别结果进行合并;
60、基于每两帧所述字幕视频帧的所述文字识别结果之间相似度,对各个所述文字识别结果进行去重;
61、使用文本纠错模型对去重后的各个所述文字识别结果进行处理,得到文本纠错结果,以及通过匹配的方式,确定出所述文字识别结果中的敏感词以及特殊字符信息;其中,所述特殊字符信息包括所述文字识别结果中的特殊字符及其索引位置。
62、可选地,在上述的视频信息分析装置中,所述分析单元执行所述分别基于各个所述文字识别结果的位置信息,确定出边缘文字并将所述边缘文字移除时,用于:
63、分别利用每个所述文字识别结果的位置信息中的左边缘坐标和右边缘坐标,计算得到每个所述文字识别结果的纵向中心坐标,以及利用每个所述文字识别结果的位置信息中的顶部坐标和底部坐标,计算得到每个所述文字识别结果的横向中心坐标;
64、将所述横向中心坐标大于所述待处理视频的高度与预设横向阈值的乘积,且所述纵向中心坐标大于所述待处理视频的宽度与预设纵向阈值的乘积的各个所述文字识别结果作为所述边缘文字并移除;
65、将当前剩余的各个所述文字识别结果,基于各个所述文字识别结果的纵向中心坐标进行聚类,得到纵向聚类中心以及纵向中心均值;
66、将所述纵向中心坐标与所述纵向聚类中心的差值的绝对值大于所述纵向中心均值与纵向聚类阈值的乘积的各个所述文字识别结果作为所述边缘文字并移除;
67、将当前剩余的各个所述文字识别结果,基于各个所述文字识别结果的横向中心坐标进行聚类,得到横向聚类中心以及横向中心均值;
68、将所述横向中心坐标与所述横向聚类中心的差值的绝对值大于所述横向中心均值与横向聚类阈值的乘积的各个所述文字识别结果作为所述边缘文字并移除。
69、可选地,在上述的视频信息分析装置中,所述目标信息为所述角色信息时,所述分析单元执行所述从所述待处理视频中识别出所述目标信息对应的识别结果,并对所述目标信息的识别结果进行分析处理,得到所述目标信息对应的关联信息,用于:
70、按照预设时间间隔对所述待处理视频进行视频帧提取,得到多帧脸部视频帧;
71、通过脸部识别模型分别对各帧所述脸部视频帧进行脸部识别,得到各帧所述脸部视频帧中的各个角色的脸部特征;
72、将各帧所述脸部视频帧中的各个所述角色的脸部特征与目标角色脸部库中的脸部特征进行匹配,得到各个所述脸部视频帧中的各个所述目标角色的脸部特征;
73、基于各个所述目标角色的脸部特征,统计每个所述目标角色的出现时长;
74、按照出现时长从大到小的顺序,对各个所述目标角色进行排序;
75、计算排序在前n位的各个所述目标角色中的每两个所述目标角色在所述待处理视频中的交并比;
76、确定出在所述待处理视频中的交并比最高的两个所述目标角色。
77、可选地,在上述的视频信息分析装置中,所述分析单元执行所述计算排序在前n位的各个所述目标角色中的每两个所述目标角色在所述待处理视频中的交并比时,用于:
78、对所述待处理视频进行分镜分割,得到个视频分镜;
79、分别针对排序在前n位的各个所述目标角色,基于所述目标角色在每个所述视频分镜中是否出现,生成所述目标角色的出场列表;其中,所述出场列表的维度等于所述视频分镜的数量,且所述出场列表的各个数值中的第一数值表示对应的所述视频分镜中出现所述目标角色,第二数值表示对应的所述视频分镜中未出现所述目标角色;
80、将每两个所述目标角色的出场列表的交集除以,两个所述目标角色的出场列表的并集,得到每两个所述目标角色的交并比。
81、可选地,在上述的视频信息分析装置中,所述目标信息为所述场景信息时,所述分析单元执行所述从所述待处理视频中识别出所述目标信息对应的识别结果,并对所述目标信息的识别结果进行分析处理,得到所述目标信息对应的关联信息,用于:
82、对所述待处理视频进行分镜分割,得到多个视频分镜;
83、分别从每个所述视频分镜的多帧视频帧中提取出多维特征向量,组成每个所述视频分镜的特征向量;
84、基于各个所述视频分镜的特征向量,计算每两个相邻的所述视频分镜的相似度;
85、将相似度大于第一预设阈值的所述视频分镜进行合并;
86、分别利用违规内容检测模型对当前的每个所述视频分镜进行逐秒检测,得到每个所述视频分镜的检测结果;
87、对检测结果超过检测阈值的所述视频分镜进行标记;
88、确定出当前的各个所述视频分镜中的目标分镜组以及相似分镜组,并将所述目标分镜组以及相似分镜组中的各个所述视频分镜进行组合;其中,所述目标分镜组由相邻的三个所述视频分镜组成,且中间的所述视频分镜的时长小于第一预设时长,其余两个所述视频分镜的相似度大于相似度阈值;所述相似分镜组由相似度大于相似度阈值的两个相邻的所述分镜视频组成;
89、将时长超过第二预设时长的所述视频分镜标记为单一重复场景;
90、根据当前的各个所述视频分镜的时长和相似度,确定出冗余分镜并标记。
91、可选地,在上述的视频信息分析装置中,所述分析单元执行所述确定出当前的各个所述视频分镜中的目标分镜组以及相似分镜组,并将所述目标分镜组以及相似分镜组中的各个所述视频分镜进行组合时,用于:
92、按照在所述待处理视频中的时间顺序,将当前的各个所述视频分镜进行排序;
93、按照排列顺序依次遍历每个所述视频分镜,并将当前遍历到的所述视频分镜确定为当前分镜;
94、若所述当前分镜未属于任意一个所述目标分镜组和所述相似分级组,则判断所述当前分镜的下一个所述视频分镜的时长是否小于所述第一预设时长;
95、若判断出所述当前分镜的下一个所述视频分镜的时长小于所述第一预设时长,则判断所述当前分镜与排序在其后的第二位的所述视频分镜的相似度是否大于相似度阈值;
96、若判断出所述当前分镜与排序在其后的第二位的所述视频分镜的相似度大于相似度阈值,则将所述当前分镜以及排序在其后的第一位和第二位的所述视频分镜作为一组所述目标分镜组并进行合并;
97、若判断出所述当前分镜的下一个所述视频分镜的时长不小于所述第一预设时长,则判断所述当前分镜与下一个所述视频分镜的相似度是否大于相似度阈值;
98、若判断出所述当前分镜与下一个所述视频分镜的相似度大于相似度阈值,则将所述当前分镜和下一个所述视频分镜作为一组所述相似分镜组并进行合并。
99、本技术第三方面提供了一种电子设备,包括:
100、存储器和处理器;
101、其中,所述存储器用于存储程序;
102、所述处理器用于执行所述程序,所述程序被执行时,具体用于实现如上述任意一项所述的视频信息分析方法。
103、本技术第四方面提供了一种计算机存储介质,用于存储计算机程序,所述计算机程序被执行时,用于实现如上述任意一项所述的视频信息分析方法。
104、本技术提供了一种视频信息分析方法,获取待处理视频,然后分别从待处理视频中识别出文字信息、角色信息以及场景信息这三项信息对应的识别结果,从而可以有效涵盖需要审核的各项信息。然后分别对这三项目标信息的识别结果进行分析处理,得到目标信息对应的关联信息,最后将各项目标信息对应的关联信息汇总并反馈。其中,文字信息对应的识别结果包括从待处理视频的多帧视频帧中识别出的各个部分文字的文字识别结果及其位置信息。文字识别结果的位置信息用于过滤掉文字识别结果中的边缘文字。角色信息对应的识别结果包括从待处理视频的多帧视频帧中识别出的角色脸部信息。场景信息对应的识别结果包括从待处理视频的各个分镜中识别出的分镜内容信息。因此这些信息不仅可以便于进行审核,还可以基于这些信息从字幕、角色以及场景进行准确的剪辑,从而可以有效提高审片的效率,保证视频内容的快速上线。
- 还没有人留言评论。精彩留言会获得点赞!