基于分层视觉transformer模型的状态特征优化方法
本发明涉及强化学习,尤其涉及一种基于分层视觉transformer模型的状态特征优化方法。
背景技术:
1、机器学习领域的特征选择已经被研究了很长时间,具体的特征选择方法包括最小冗余、最大相关以及启发式算法进行提取。特征选择的目的是通过过滤掉一些关联性不强的特征来减少模型训练过程中产生的方差,目前研究结果最多的是基于深度学习的相关特征选择方法,其核心思想是利用无监督或有监督学习方法自动从数据中学习表示或特征。近年来涌现不少基于深度强化学习进行特征选择的方法研究,其主要原因是强化学习是做出最佳决策的技术之一,使用强化学习方法可以在任何数据集上灵活使用并针对每一个特征进行调整,但目前基于强化学习(reinforcement learning,rl)的方法需要大量的计算时间和计算能力来搜索更多的状态空间。
2、深度强化学习从被提出到至今,在视频游戏领域获得了显著成就,但将深度强化学习应用到现实世界中的决策控制任务中,例如:导航、机器人操纵以及机械臂抓取等任务,并没有取得类似于在视频游戏领域中的惊人表现。在强化学习中,智能体通过与环境交互“试错”的方式进行学习,并在未知环境中选择最优策略来实现最大化累积奖励的目标。在智能体探索学习的过程中,若外部环境的奖励较为稀疏,就会导致智能体探索环境的程度不充分。将这种奖励稀疏、正负奖励不均的情况定义为稀疏奖励(sparse reward)问题,该问题是深度强化学习在解决实际任务过程中面临的核心问题。因此,解决稀疏奖励问题在深度强化学习中智能体的探索学习过程中是十分必要的。
3、在深度强化学习的稀疏奖励设置中最需要解决的问题是提高智能体对外部环境的探索效率,实现高效的探索决策。针对稀疏奖励问题的主要研究包括:奖励的重塑与设计、探索与利用、多目标学习与辅助任务等等。目前在探索与利用中,基于内在激励的方法应用较为广泛,包括:状态访问计数、好奇心驱动的探索、提炼随机网络、集合分歧以及记忆情节的状态可达性等方法。其中,好奇心驱动的探索是深度强化学习中解决稀疏奖励问题中的里程碑。近年来出现了许多与好奇心探索相关的方法研究,基于好奇心驱动的探索方法主要通过添加额外的参数项,修改损失函数或者网络结构的方式构建内在奖励,从而进行激励探索以提高智能体的探索性能,该方法相较于传统的随机探索方法更倾向于探索环境中的未知区域,能够处理复杂或稀疏的状态空间。除了获取基于环境的外部奖励信号,基于好奇心驱动的探索方法可以将智能体产生的内在奖励信息用于鼓励自身进行状态空间的探索,不容易陷入到局部最优值。oudeyer等人首次提出智能自适应好奇心(intelligentadaptive curiosity,iac),通过引入前向动力学模型学习探索,在减少预测误差的同时计算内在奖励信号。pathak等人提出的内在好奇心模型(intrinsic curiosity module,icm)主要由前向动力学模型和逆向动力学模型组成,将状态特征的编码作为前向动力学模型输入并预测其下一个状态特征;该方法通过引入前向动力学模型和逆向动力学模型来量化智能体下一个状态和行动的预测误差,使用该误差作为内在奖励信号从而给予智能体在探索过程中更多的奖励信号,缓解稀疏奖励的困境。
4、transformer模型在自然语言处理、计算机视觉、语音处理、大规模模型等人工智能领域取得了巨大的成功,在学术界和工业界引发了广泛的关注。注意力机制在transformer模型中获得了广泛应用,例如:自注意机制、多头自注意机制、稀疏注意力机制、局部注意力机制、全局注意力机制等等。其中,自注意机制是transformer模型的核心,而多头自注意机制的提出进一步提升了transformer模型的性能,但由于多头自注意机制存在复杂度较高、训练速度较慢的缺点,所以通常采用局部注意力去降低自注意力的二次复杂度,例如:独立自我注意力(stand-alone self-attention,sasa)、滑动窗口注意力(swin window self attention,swas)等等。hassani等人首先提出了邻近注意力(neighorhood attention,na)的概念,它是一种可扩展的高效的视觉滑动窗口注意力机制,将注意力定位在相邻最近的周围像素。由于邻近注意力主要面向局部的像素范围,故邻近注意力存在减少了对全局数据信息的长期依赖以及忽略了全局感受野两个问题。因此,hassani等人为了解决上述问题继续提出了可扩张的邻近注意力(dilated neighorhoodattention,dina),它是一种自然且可以灵活高效地进行扩张的邻近注意力的扩展,还可以在不需要额外的成本的情况下对感受野进行指数级别的扩张,从而成功获得更多的全局特征信息。最后,将邻近注意力na与可扩张的邻近注意力dina进行结合,提出一种可扩张的邻近注意力transformer(dilated neighorhood attention transformer,dinat)模型,该模型不仅可以获得局部信息还能获得稀疏的全局信息。
5、现有技术中提出了一种统一的基于好奇心驱动的方法用于解决强化学习中奖励稀疏情况下存在的探索困难的问题。该方法主要通过使用注意力机制去获得可靠的特征表达,使用状态新颖性估计智能体的当前状态和下一个状态的特征表达并计算出内在奖励信息,并对状态空间中三种不同样本的探索程度估计值进行加权计算以获得内部奖励再进行平滑处理和融合。该方法在前向动力学模型与新的环境进行交互时训练数据样本增加的情况下,利用状态新颖性进行三个不同样本之间的内在奖励估计会导致对目标特征的丢失,并且对深度网络计算的损失会更高,同时也降低了奖励计算的效率。
6、除此之外,现有技术中还提出了一种基于注意力机制和强化学习的自动特征构造方法,该方法首先指定固定分类问题的数据集并使用自注意机制进行不同种类的特征组合的评分,即特征分类结果。其次,引入强化学习中的基于策略梯度的方法进行特征状态的评估,使用强化学习中的元特征为该方法的数据标签。但该方法主要使用自注意机制面向不同种类的特征分组进行分类评估,没有考虑面向同一类型数据时进行不同特征权重的自动构建情况。该方法引入强化学习中的蒙特卡洛策略梯度(reinforce:monte-carlo policygradient)算法进行特征的自动选择,将数据结合真实的标签特征作为强化学习控制器的输入,然后将输出的奖励值定义为内在奖励并作为特征被选择的概率,会出现梯度计算和训练不稳定、计算的奖励方差较大的问题。
技术实现思路
1、针对上述现有技术的不足,本发明提出了一种基于分层视觉transformer模型的状态特征优化方法,旨在缓解智能体在探索过程中陷入局部最优困境,提高有限数据样本的利用效率,优化状态特征提取准确性。
2、本发明提出的一种基于分层视觉transformer模型的状态特征优化方法,该方法包括如下步骤:
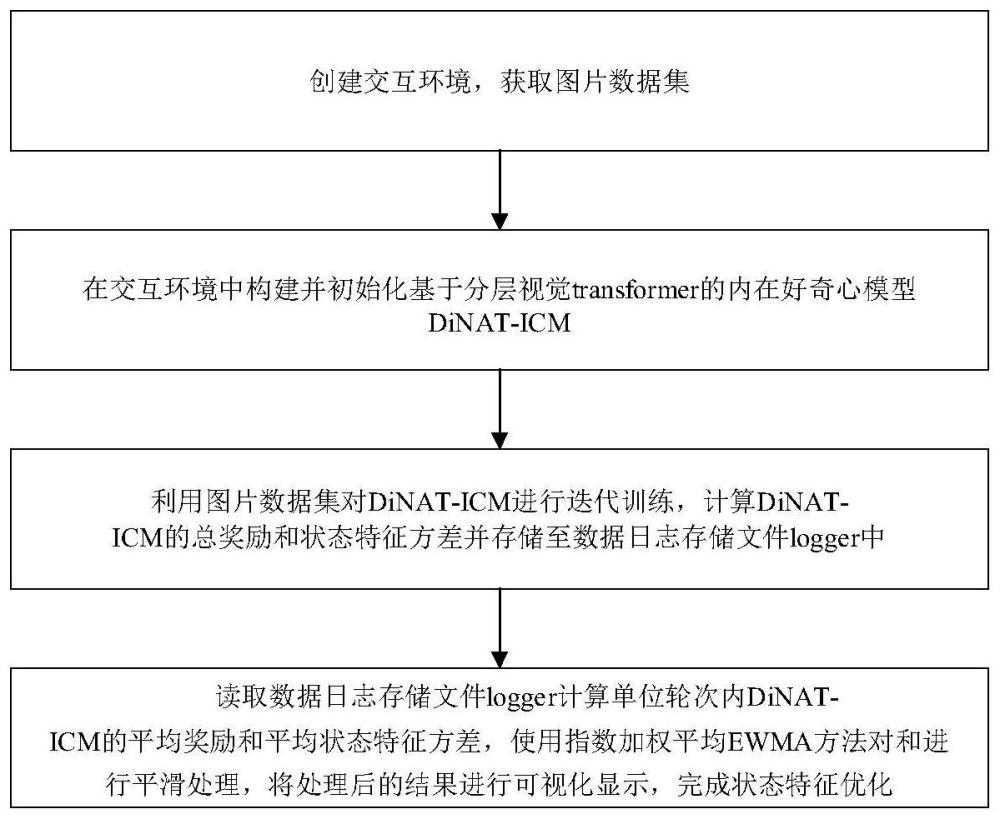
3、步骤1:创建交互环境envs,获取图片数据集;
4、步骤2:在交互环境envs中构建并初始化基于分层视觉transformer的内在好奇心模型dinat-icm;
5、步骤3:利用图片数据集对基于分层视觉transformer的内在好奇心模型dinat-icm进行迭代训练,计算dinat-icm的总奖励rewardtotal和状态特征方差featurestd并存储至数据日志存储文件logger中;
6、步骤4:读取数据日志存储文件logger中的总奖励rewardtotal和状态特征方差featurestd,并计算单位轮次内dinat-icm的平均奖励和平均状态特征方差使用指数加权平均ewma方法对和进行平滑处理,将处理后的结果进行可视化显示,完成状态特征优化;
7、所述步骤1进一步包括:
8、步骤1.1:根据设置的并行环境数量num_envs创建若干个独立运行的并行环境,利用创建的并行环境构建交互环境,并设置交互环境中的随机种子数量;
9、步骤1.2:设置数据帧数n_stack,并获取由连续n_stack帧图片构成的图片数据集;
10、步骤2中所述基于分层视觉transformer的内在好奇心模型dinat-icm,包括:内在好奇心网络icm_network、可扩张的邻近注意力transformer模型dinat_network和a2c算法网络a2c_network;
11、所述内在好奇心网络icm_network,用于预测基于分层视觉transformer的内在好奇心模型dinat-icm的内在奖励,包括依次连接的:特征编码器feature_encoder、前向动力学模型forwardnet和逆向动力学模型inversenet;
12、所述可扩张的邻近注意力transformer模型dinat_network,用于优化内在好奇心网络icm_network,包括依次连接的:第一归一化层layernorm1、可扩张的稀疏全局注意力dina、第二归一化层layernorm2、多层感知器mlp、线性层linear5以及softmax函数;
13、所述a2c算法网络a2c_network,用于预测基于分层视觉transformer的内在好奇心模型dinat-icm的折扣奖励,包括依次连接的:自注意网络self-attentionnet、评论家actor网络和批评家critic网络;
14、步骤2中所述初始化基于分层视觉transformer的内在好奇心模型dinat-icm包括:设置数据帧数n_stack、并行环境数量num_envs、动作数量num_actions、环境名称envs_name、输入数据大小input_size和状态特征大小feature_size;
15、所述步骤3进一步包括:
16、步骤3.1:重置交互环境,获取交互环境中dinat-icm的当前轮次的状态观察值obs,并对该状态观察值obs进行初始化,得到大小为[num_env,width,height,n_stack]的n维数组对象numpyobs;其中width为图片宽度,height为图片高度;
17、步骤3.2:将数组对象numpyobs转换为状态信息张量tensorstates;所述状态信息张量tensorstates大小为[num_env,n_stack,width,height];
18、步骤3.3:根据状态信息张量tensorstates,利用深度强化学习a2c算法对基于分层视觉transformer的内在好奇心模型dinat-icm进行迭代训练,计算dinat-icm的折扣奖励rext;
19、步骤3.4:清空基于分层视觉transformer的内在好奇心模型dinat-icm中累积的梯度并初始化为0;
20、步骤3.5:计算dinat-icm的状态预测误差作为dinat-icm的状态特征方差featurestd和内在奖励rinsic;
21、步骤3.6:利用dinat-icm的折扣奖励rext和内在奖励rinsic计算当前迭代轮次step中的总奖励rewardtotal;
22、步骤3.7:将总奖励rewardtotal和状态特征方差featurestd存储至数据日志存储文件logger中,重复步骤3.1-3.6直至完成预置的迭代轮次;
23、所述步骤3.3进一步包括:
24、步骤3.3.1:构建并初始化经验回收池buffer;
25、步骤3.3.2:将dinat-icm在当前迭代轮次step下的状态信息张量tensorstates作为状态信息states;
26、步骤3.3.3:利用特征编码器feature_encoder对状态信息states进行编码转化,得到状态编码feature,并将该状态编码映射到特征空间中;
27、步骤3.3.4:将映射后的状态编码输入自注意力网络并利用注意力权重筛选状态信息得分featurescore,对状态信息得分featurescore进行softmax归一化,得到最终的注意力状态特征featureattn;
28、步骤3.3.5:将最终的注意力状态特征featureattn输入actor网络,得到决策πattn并进行softmax归一化,获得当前的动作概率分布action并利用随机分布采样得到dinat-icm的下一个动作actionattn;
29、步骤3.3.6:将映射后的状态编码和决策πattn输入critic网络,计算当前状态下的价值v(feature,πattn);
30、步骤3.3.7:计算策略损失、价值函数损失和策略熵policyentropy并构建总损失利用总损失计算dinat-icm当前的折扣奖励rext,并将折扣奖励rext、状态特征featureattn、动作actionattn、动作概率分布action和价值v(feature,πattn)存储到经验回收池buffer中;
31、步骤3.3.8:重置经验回收池buffer,并重复步骤3.3.2-3.3.7,继续迭代计算下一轮次stepnext的折扣奖励rext、状态特征featureattn、动作actionattn、动作概率分布action和价值v(feature,πattn),直至完成预置的迭代轮次;
32、所述步骤3.5进一步包括:
33、步骤3.5.1:将dinat-icm在当前迭代轮次step下的状态信息张量tensorstates作为状态信息states,利用特征编码器feature_encoder对该状态信息states进行编码转化,得到状态编码feature,并将该状态编码映射到特征空间中,得到映射后的状态特征feature0和对应的状态特征信息featurecurt,再对状态特征feature0进行切片,获取dinat-icm的下一个状态特征信息featurenext;
34、步骤3.5.2:获取当前迭代轮次step中第t回合的状态特征featuret并利用可扩张的邻近注意力transformer结构dinat_network对状态特征featuret进行归一化操作,再对得到的特征张量进行升维,并利用可扩展稀疏全局注意力dina并进行残差计算,得到经残差计算后的状态特征;
35、步骤3.5.3:对经残差计算后的状态特征进行归一化和降维后,再进行一次softmax归一化,得到经过dinat网络优化后的状态特征featuredinat;
36、步骤3.5.4:根据dinat-icm的状态特征信息featurecurt、dinat-icm的下一个状态特征信息featurenext和优化后的状态特征featuredinat,利用前向动力学模型forwardnet预测dinat-icm的下一个状态特征编码再利用逆向动力学模型inversenet计算当前动作的预测值
37、步骤3.5.5:利用dinat-icm的下一个状态特征编码和当前动作的预测值计算dinat-icm的状态特征方差featurestd和内在奖励rinsic;
38、所述前向动力学模型和逆向动力学模型的为:
39、featuredinat=dinat(featurecurt)
40、
41、
42、其中dinat()表示可拓展邻近注意力transformer网络结构;forwardnet()表示dinat-icm中的前向动力学模型;actionattn表示通过自注意力机制优化actor网络后获得的动作:inversenet()表示dinat-icm中的逆向动力学模型。
43、与现有技术相比,采用上述技术方案所产生的有益效果在于:
44、(1)本发明方法利用可扩张的邻近注意力transformer模型优化强化学习中的内在好奇心模型中的前向动力学模型,计算不同状态特征的权重信息,评估出对智能体探索更加有利的状态特征并且获得更佳的内在奖励信号,提高数据样本的利用效率,缓解智能体在探索过程中普遍存在的稀疏奖励问题。
45、(2)本发明方法通过引用自注意机制来改进优势演员-评论员(advantage actor-critic,a2c)算法中的actor网络,提取优质的局部状态特征,从而获得更加有利的动作空间,减少下一个最佳动作的搜索空间,避免状态空间过于稀疏并提高模型性能。
46、(3)本发明方法使用指数加权平均方法(exponential weighted movingaverage,ewma)对数据进行平滑处理,增强深度强化学习的可解释性。
- 还没有人留言评论。精彩留言会获得点赞!