一种情感信息融合方法、装置、电子设备及存储介质
本发明涉及情感分析,尤其涉及一种情感信息融合方法、装置、电子设备及存储介质。
背景技术:
1、多模态情感分析是一种研究人们从多个感觉模态(如文本、音频、图像和视频)中识别和理解情感的技术。它结合了自然语言处理、音频信号处理和计算机视觉等领域的技术,以实现更全面的情感分析。例如,假设有一条社交媒体帖子,其中包含一段文本、一段音频和一张图片。帖子是某个用户在他的生日派对上发布的,他分享了他和朋友们的开心时刻。首先从帖子文本中提取情感信息。在音频部分,可以分析帖子中包含的声音记录,帖子中还包括一张照片,照片上是生日派对上的人们。最后,将来自文本、音频和视频的情感信息进行融合,分析出发帖子的这个作者是快乐的。这个过程展示了多模态情感分析如何能够从不同感官模态的信息中综合情感,以更全面地理解和解释社交媒体帖子的情感内容。这种方法有助于深入洞察用户在社交媒体上的情感体验,并可以应用于情感驱动的个性化建议、情感智能系统和市场研究等各种领域。
2、情感分析这项任务原本是自然语言处理的一个分支,随着人们深入研究,情感分析在文本模态上日渐成熟,原先单一文本无法完整分析出表达者说话的心情,也随着语音、图像处理技术识别能力的加强而得到改变,情感分析任务添加新模态的数据能够让计算机在情感分析任务中的分析准确度得到上升。
3、然而,在多模态情感分析方向上,一般的方法是先将文本、语音、视频都转化成能够表达单一模态下语义信息的张量,紧接着用卷积神经网络将三种模态下的语义信息串联拼接到一起,通过一个分类器将融合后的结果分到某一个情感强度类上。这种方法具有一定的局限性。比如,模态信息没有进行交互,语义信息缺少融合,分类的准确度不高。
技术实现思路
1、本发明提供了一种情感信息融合方法、装置、电子设备及存储介质,用于解决现有的情感信息融合方法分类准确度不高的技术问题。
2、本发明提供了一种情感信息融合方法,包括:
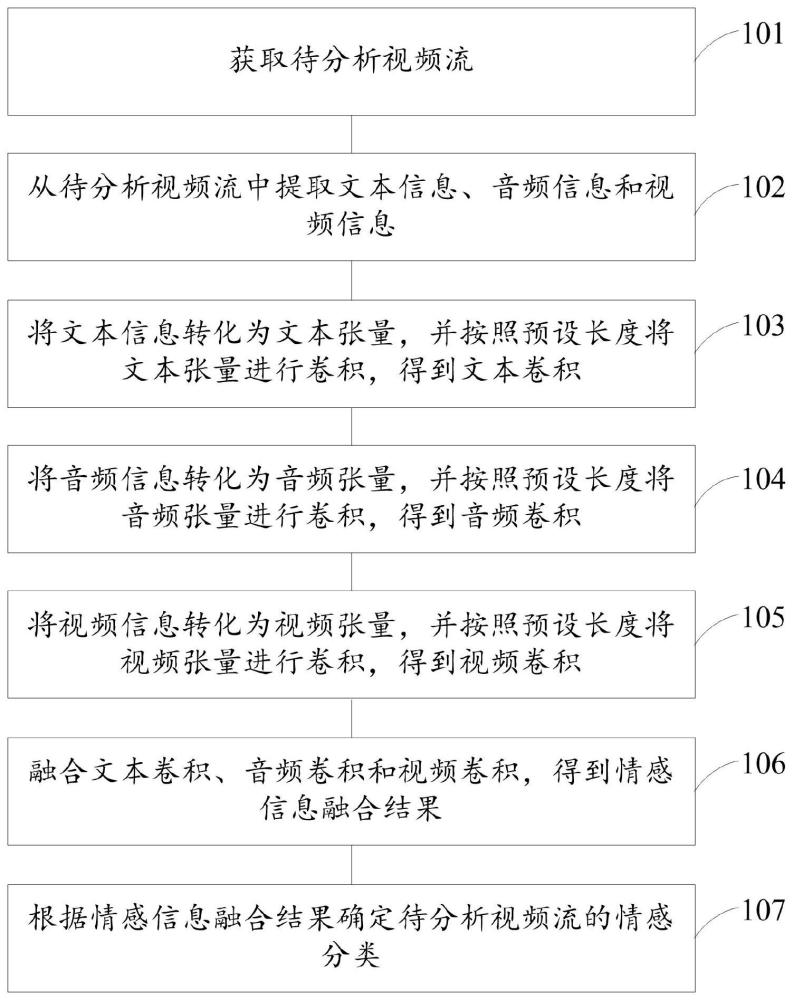
3、获取待分析视频流;
4、从所述待分析视频流中提取文本信息、音频信息和视频信息;
5、将所述文本信息转化为文本张量,并按照预设长度将文本张量进行卷积,得到文本卷积;
6、将所述音频信息转化为音频张量,并按照预设长度将音频张量进行卷积,得到音频卷积;
7、将所述视频信息转化为视频张量,并按照预设长度将视频张量进行卷积,得到视频卷积;
8、融合所述文本卷积、音频卷积和所述视频卷积,得到情感信息融合结果;
9、根据所述情感信息融合结果确定所述待分析视频流的情感分类。
10、可选地,所述将所述文本信息转化为文本张量,并按照预设长度将文本张量进行卷积,得到文本卷积的步骤,包括:
11、采用回译技术将所述文本信息转化为回译文本;
12、对所述回译文本进行编码,形成文本张量;
13、按照预设长度将所述文本张量进行卷积,得到文本卷积。
14、可选地,所述对所述回译文本进行编码,形成文本张量的步骤,包括:
15、对回译文本进行编码,得到编码文本;
16、在所述编码文本前端插入起始标记、在所述编码文本后端插入结束标记,生成标记文本;
17、将所述标记文本转化为数组形式的数组文本;
18、将所述数组文本转化为隐藏状态,得到文本张量。
19、可选地,所述融合所述文本卷积、音频卷积和所述视频卷积,得到情感信息融合结果的步骤,包括:
20、通过预设激活函数将所述文本卷积转化为激活文本,并对所述激活文本进行转置,得到转置文本;
21、通过预设激活函数将所述音频卷积转换为激活音频,并对所述激活音频进行转置,得到转置音频;
22、通过预设激活函数将所述视频卷积转换为激活视频,并对所述激活视频进行转置,得到转置视频;
23、对所述激活文本和所述转置文本进行点积操作,得到文本模态的文本注意力信息;
24、对所述激活音频和所述转置音频进行点积操作,得到音频模态的音频注意力信息;
25、对所述激活视频和所述转置视频进行点积操作,得到视频模态的视频注意力信息;
26、对所述文本注意力信息、所述音频注意力信息和所述视频注意力信息进行两两融合,得到融合信息;
27、将多个所述融合信息进行加权融合,得到情感信息融合结果。
28、本发明还提供了一种情感信息融合装置,包括:
29、待分析视频流获取模块,用于获取待分析视频流;
30、信息提取模块,用于从所述待分析视频流中提取文本信息、音频信息和视频信息;
31、文本卷积模块,用于将所述文本信息转化为文本张量,并按照预设长度将文本张量进行卷积,得到文本卷积;
32、音频卷积模块,用于将所述音频信息转化为音频张量,并按照预设长度将音频张量进行卷积,得到音频卷积;
33、视频卷积模块,用于将所述视频信息转化为视频张量,并按照预设长度将视频张量进行卷积,得到视频卷积;
34、融合模块,用于融合所述文本卷积、音频卷积和所述视频卷积,得到情感信息融合结果;
35、分类模块,用于根据所述情感信息融合结果确定所述待分析视频流的情感分类。
36、可选地,所述文本卷积模块,包括:
37、回译子模块,用于采用回译技术将所述文本信息转化为回译文本;
38、文本张量生成子模块,用于对所述回译文本进行编码,形成文本张量;
39、文本卷积子模块,用于按照预设长度将所述文本张量进行卷积,得到文本卷积。
40、可选地,所述文本张量生成子模块,包括:
41、文本编码单元,用于对回译文本进行编码,得到编码文本;
42、标记文本生成单元,用于在所述编码文本前端插入起始标记、在所述编码文本后端插入结束标记,生成标记文本;
43、数组文本转化单元,用于将所述标记文本转化为数组形式的数组文本;
44、文本张量生成单元,用于将所述数组文本转化为隐藏状态,得到文本张量。
45、可选地,所述融合模块,包括:
46、转置文本生成子模块,用于通过预设激活函数将所述文本卷积转化为激活文本,并对所述激活文本进行转置,得到转置文本;
47、转置音频生成子模块,用于通过预设激活函数将所述音频卷积转换为激活音频,并对所述激活音频进行转置,得到转置音频;
48、转置视频生成子模块,用于通过预设激活函数将所述视频卷积转换为激活视频,并对所述激活视频进行转置,得到转置视频;
49、文本注意力信息生成子模块,用于对所述激活文本和所述转置文本进行点积操作,得到文本模态的文本注意力信息;
50、音频注意力信息生成子模块,用于对所述激活音频和所述转置音频进行点积操作,得到音频模态的音频注意力信息;
51、视频注意力信息生成子模块,用于对所述激活视频和所述转置视频进行点积操作,得到视频模态的视频注意力信息;
52、融合子模块,用于对所述文本注意力信息、所述音频注意力信息和所述视频注意力信息进行两两融合,得到融合信息;
53、情感信息融合结果生成子模块,用于将多个所述融合信息进行加权融合,得到情感信息融合结果。
54、本发明还提供了一种电子设备,所述设备包括处理器以及存储器:
55、所述存储器用于存储程序代码,并将所述程序代码传输给所述处理器;
56、所述处理器用于根据所述程序代码中的指令执行如上任一项所述的情感信息融合方法。
57、本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质用于存储程序代码,所述程序代码用于执行如上任一项所述的情感信息融合方法。
58、从以上技术方案可以看出,本发明具有以下优点:本发明公开了一种情感信息融合方法,具体包括:获取待分析视频流;从待分析视频流中提取文本信息、音频信息和视频信息;将文本信息转化为文本张量,并按照预设长度将文本张量进行卷积,得到文本卷积;将音频信息转化为音频张量,并按照预设长度将音频张量进行卷积,得到音频卷积;将视频信息转化为视频张量,并按照预设长度将视频张量进行卷积,得到视频卷积;融合文本卷积、音频卷积和视频卷积,得到情感信息融合结果;根据情感信息融合结果确定待分析视频流的情感分类。从而提高情感分类的准确度。
- 还没有人留言评论。精彩留言会获得点赞!