本发明涉及碳排放预测,具体而言,涉及一种基于tsa-arima-cnn的企业碳排放预测方法。
背景技术:
1、矿业行业是一些工业国家重要的能源和原材料来源,在矿业生产作业的同时会排放大量的温室气体。温室气体过度排放会对环境造成严重的危害从而引起一系列的自然灾害,例如:加快冰雪融化造成海平面上升、气温升高和土地干旱等,因此有效减少温室气体的排放迫在眉睫。正因如此,对于矿山企业的碳排放的预测具有很大的研究价值,通过预测矿山企业的碳排放,可以有效评估矿山企业的潜在碳排放是否符合排放标准,从而减少温室气体的排放。
2、目前,在碳排放预测领域,大多使用单一的机器学习或深度学习模型如:支持向量机、神经网络等进行建模预测。由于矿业生产在不同时间生产量的不同和设备磨损等原因导致碳排放数据中存在线性和非线性特征,然而单一的模型很难同时捕捉数据中存在的线性和非线性特征,从而导致模型的预测精度较低。
3、因此,急需发明一种用于解决现有技术中单一模型难以捕捉碳排放数据中存在的线性和非线性特征,从而导致模型的预测精度较低的企业碳排放预测方法。
技术实现思路
1、鉴于此,本发明提出了一种基于tsa-arima-cnn的企业碳排放预测方法,旨在解决当前技术中单一模型难以捕捉碳排放数据中存在的线性和非线性特征,从而导致模型的预测精度较低的问题。
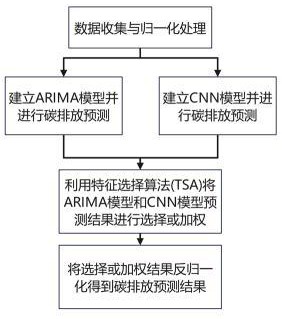
2、本发明提出了一种基于tsa-arima-cnn的企业碳排放预测方法,包括:
3、获取所述企业生产的历史碳排放时间序列数据,并对所述历史碳排放时间序列数据进行归一化处理;
4、获取arima(autoregressive integrated moving average model,差分自回归移动平均模型)模型的最优参数,并根据所述最优参数建立arima模型;
5、将rmse和r2作为评价指标,并获取cnn(convolutional neural network,卷积神经网络)模型的最优参数,建立cnn模型;
6、将归一化处理后的所述历史碳排放时间序列数据代入所述arima模型以及所述cnn模型进行预测,并获取所述arima模型的碳排放预测序列以及所述cnn模型的碳排放预测序列;
7、基于特征选择算法将所述arima模型的碳排放预测序列以及所述cnn模型的碳排放预测序列进行选择或加权,并获取选择或加权后的预测结果;
8、将所述预测结果进行反归一化处理,并将反归一化处理的所述预测结果设定为碳排放预测输出结果。
9、进一步的,基于特征选择算法将所述arima模型的碳排放预测序列以及所述cnn模型的碳排放预测序列进行选择或加权,并获取选择或加权后的预测结果时,包括:
10、获取所述arima模型的碳排放预测值与碳排放实际值之间的残差的绝对值;
11、获取所述cnn模型的碳排放预测值与碳排放实际值之间的残差的绝对值;
12、设置大小为t的窗口,并在所述窗口内计算所述arima模型的残差的绝对值的总和以及所述cnn模型的残差的绝对值的总和;
13、将所述arima模型的残差的绝对值的总和与所述cnn模型的残差的绝对值的总和之间大小关系,确定待定预测序列;
14、获取所述窗口内不同时间点的arima模型预测值的残差的绝对值的a值数量以及所述窗口内不同时间点的cnn模型预测值的残差的绝对值的a值数量,并获得arima模型和cnn模型预测序列的权重,以此确定待定预测序列;
15、设定函数rmse,并获取区间0~1之间网格化搜索arima模型和cnn模型预测序列的权重,并根据所述arima模型和cnn模型预测序列的权重作为阈值,以此确定待定预测序列;
16、获取待定预测序列、和在测试集的rmse,根据所述待定预测序列、和的rmse之间的大小关系进行比对,并根据比对结果选定所述预测结果。
17、进一步的,将所述arima模型的残差的绝对值的总和与所述cnn模型的残差的绝对值的总和之间大小关系,确定待定预测序列时,包括:
18、获取所述arima模型的残差的绝对值的总和以及cnn模型的残差的绝对值的总和,并根据所与之间的关系确定所述待定预测序列;其中,
19、当时,则确定所述arima模型的碳排放预测值为待定预测序列;
20、当时,则确定所述cnn模型的碳排放预测值为待定预测序列。
21、进一步的,获取所述窗口内不同时间点的arima模型预测值的残差的绝对值的a值数量以及所述窗口内不同时间点的cnn模型预测值的残差的绝对值的a值数量,并获得arima模型和cnn模型预测序列的权重,以此确定待定预测序列时,包括:
22、获取所述arima模型的预测序列的权重为窗口内不同时间点的arima模型预测值的残差的绝对值的a值的个数;
23、获取所述cnn模型的预测序列的权重;
24、根据所述arima模型的预测序列的权重和cnn模型的预测序列的权重,并基于公式ⅰ获取所述待定预测序列,所述公式ⅰ如下所示:
25、
26、其中,为所述arima模型的预测序列,为所述cnn模型的预测序列。
27、进一步的,设定函数rmse(root mean square error,均方根误差),并获取区间0~1之间网格化搜索arima模型和cnn模型预测序列的权重,并根据所述arima模型和cnn模型预测序列的权重作为阈值,以此确定待定预测序列时,包括:
28、设定适应度函数rmse,并获取区间0~1之间以0.01为间隔的arima模型权重的可能取值的适应度函数rmse的值和cnn模型权重的可能取值的适应度函数rmse的值;
29、获取所述arima模型权重的可能取值的适应度函数rmse的值中的最小值对应的权重作为所述arima模型的权重,且;
30、获取所述cnn模型权重的可能取值的适应度函数rmse的值中的最小值对应的权重作为所述cnn模型的权重,且;
31、根据所述arima模型的权重和cnn模型的权重基于公式ⅱ获取所述待定预测序列,所述公式ⅱ如下所示:
32、。
33、进一步的,根据所述待定预测序列、和的rmse之间的大小关系进行比对,并根据比对结果选定所述预测结果时,包括:
34、获取所述待定预测序列的rmse△a1、待定预测序列的rmse△a2和待定预测序列的rmse△a3,并根据所述△a1与△a2以及△a3之间进行比对,并根据比对结果确定为所述预测结果;
35、当△a1<△a2,且△a1<△a3时,则确定所述待定预测序列为所述预测结果;
36、当△a1>△a2,且△a2<△a3时,则确定所述待定预测序列为所述预测结果;
37、当△a1>△a3,且△a2>△a3时,则确定所述待定预测序列为所述预测结果。
38、进一步的,获取所述企业生产的历史碳排放时间序列数据,并对所述历史碳排放时间序列数据进行归一化处理时,包括:
39、获取所述历史碳排放时间序列数据中若干时间节点的碳排放数据,并建立数据集;
40、将所述数据集进行归一化处理,并按照时间顺序将归一化处理的所述数据集划分为训练集和测试集,所述归一化公式为:
41、
42、其中,为归一化后的所述数据集,为所述数据集,为所述数据集中的最小值,为所述数据集中的最大值。
43、进一步的,获取arima模型的最优参数,并根据所述最优参数建立arima模型时,包括:
44、获取所述历史碳排放时间序列数据中的时间序列,并基于单位根检验对所述时间序列的平稳性进行检测,其中:
45、获取所述时间序列中的p值,并根据所述p值与预设的p0值之间的关系判断所述时间序列是否平稳;
46、当p>p0时,则判断所述时间序列为不平稳时间序列,并基于差分算法将所述不平稳时间序列转换为所述平稳时间序列;
47、当p≤p0时,则判断所述时间序列为平稳时间序列,并获取所述时间序列中p值,并根据所述p值与预设p1值之间的关系,判断所述平稳时间序列是否为白噪声;
48、当p≥p1时,则判断所述平稳时间序列为白噪音,并对所述时间序列进行调整;
49、当p<p1时,则判断所述平稳时间序列为非白噪音,并基于贝叶斯信息准则获取所述arima模型中最优的三个参数。
50、进一步的,将rmse和作为评价指标,并获取cnn模型的最优参数,建立cnn模型时,包括:
51、获取卷积核个数、卷积核大小、最大迭代次数和模型的批量大小以及所述cnn模型的超参数;
52、根据所述卷积核个数、卷积核大小、最大迭代次数和模型的批量大小对所述cnn模型的超参数进行调整,其中;
53、获取若干调整后的所述cnn模型的超参数中的rmse以及r2指标;
54、根据rmse指标的大小关系对若干调整后的所述cnn模型的超参数进行第一排序;
55、根据r2指标的大小关系对若干调整后的所述cnn模型的超参数进行第二排序;
56、获取所述若干调整后的所述cnn模型的超参数中rmse指标小于其他rmse指标且r2指标大于其他r2指标的cnn模型的超参数,并定义为所述cnn模型的最优参数。
57、与现有技术相比,本发明的有益效果在于:
58、1、通过获取历史碳排放时间序列数据并进行归一化处理,确保数据的可比性和稳定性。然后,利用arima模型对时间序列数据进行建模,通过获取最优参数来提高模型的预测精度。同时,使用cnn模型作为另一种预测工具,通过训练获取最优参数,并建立针对碳排放预测的深度学习模型。在预测过程中,将归一化后的历史碳排放时间序列数据分别代入arima模型和cnn模型进行预测,得到两种模型的碳排放预测序列。通过基于特征选择算法对这两个预测序列进行选择或加权,以综合考虑两种模型的预测效果,从而提高整体预测准确度和稳定性。最后,将加权后的预测结果进行反归一化处理,得到最终的碳排放预测输出结果,这个结果可用于企业制定碳排放管理策略和规划未来发展方向。进一步通过综合利用传统统计模型和深度学习模型的优势,从而能够更全面、准确地预测企业的碳排放情况。
59、2、通过利用arima模型捕捉线性特征和cnn模型捕捉非线性特征的能力去捕捉碳排放数据中同时存在的线性和非线性特征,接着利用特征选择算法(tsa),选择或加权arima模型和cnn模型捕捉到的相应特征,充分地提取并利用了碳排放数据中的线性和非线性特征,解决了单一模型预测碳排放只能捕捉线性或非线性特征弊端,提高的碳排放预测的精度。
60、3、通过利用特征选择算法tsa选择或加权arima模型和cnn模型捕捉到的相应特征,在特征选择或加权时考虑了单一线性或非线性特征的情况与线性和非线性特征同时存在的情况;本发明采用的特征选择算法tsa中通过设置大小为t的窗口,可以选择或加权局部的线性和非线性特征,从而避免了在全局选择或加权线性和非线性特征的局限性,使得预测结果更加准确,具有很强的适用性。