基于三层数据模型网络优化的企业资源配置决策方法及系统
本发明属于智能化优化企业资源管理和提升决策质量,具体涉及一种智能三层数据模型网络优化的企业资源配置决策方法及系统。
背景技术:
1、在快速变化的商业环境中,企业需要依靠精确而有效的决策过程来优化资源配置和提高运营效率。随着大数据和高级分析工具的发展,企业有更多机会从复杂数据中提取有价值的信息。然而,这种数据的多样性和复杂性要求有一种结构化的方法来分析和应用这些信息。现有数据分析方法在处理与企业运营和策略规划相关的多维数据时,缺乏一个整合不同数据层次的综合性框架,导致决策过程不够高效或缺乏灵活性。基于此现状,本发明提出了构建一种智能三层数据结构模型,旨在为企业提供一个全面的数据分析框架,以支持更精准和高效的决策,它不仅考虑了数据的多维性,还整合了量级关系和广泛的环境因素。
技术实现思路
1、针对现有数据分析方法在优化企业资源管理和提升决策质量的局限性,本发明提供了一种基于三层数据模型网络优化的企业资源配置决策方法及系统。本发明的创新之处在于,三层数据结构模型amf(attribute:属性–magnitude:量级–factor:因素),旨在为复杂决策环境中的数据分析和算法应用提供一个框架。本发明模型的核心目的是通过数据计算服务来优化决策过程,实现组织数字化变革。
2、为了达到上述发明目的,本发明采取以下技术方案:
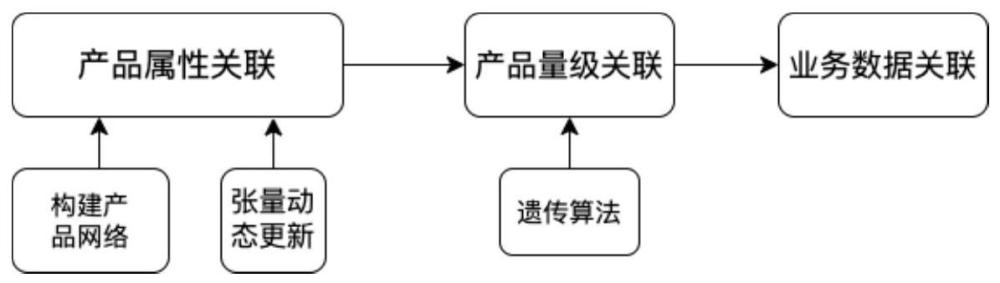
3、基于三层数据模型网络优化的企业资源配置决策方法,包括三个层级即三个步骤:
4、第一步:识别和分析产品之间的基本属性关联;
5、第二步:对第一步识别的产品属性关联进行量化分析;
6、第三步:将产品数据与市场、业务因素相结合,形成全面的策略。
7、本发明中,第一层级即第一步:将目标产品可能的材料组合作为社区,为模型建立基础数据结构。这一层的重点是根据模块度(modularity:是一种常用的衡量节点分组质量的标准,模块度越高说明所检测到的社团越符合社团内部连接紧密,而社团外部的连接则相对稀疏,“内紧外松”的特征,分组质量越好)识别与特定产品直接相关的材料形成聚合,即louvain网络定义中的社群,为后续分析奠定基础。
8、第二层级即第二步:通过遗传算法探讨材料组合与目标产品之间的量级关系。通过量化不同组合的可能输出,此层分析这些输出与目标产品之间的数量级关系,构成稳固量级关系,为决策提供量化依据。
9、第三层级即第三步:结合广泛因素,如量价关系、时空因素、物流、环境、政策和客户喜好等等业务因素,利用前两层的数据寻找最优路径,同时考虑过程中可能出现的变更。这一层的关键在于运用数据驱动的方法来优化资源配置和运营效率。
10、每个层级专注于企业运营和决策的不同方面。下面进行更详细的描述。
11、第一层级:产品属性关联,它用于识别和分析产品之间的基本属性关联。这一层的核心目的是映射出产品间的基础关系,明确产品的基本构成、关键组件、设计参数。例如,哪些组件是特定成品的必要部分,或者哪些原材料可以共同用于生产多个不同的产品,产品关联的参数。通过分析这一层,可以确定产品设计和开发的基本框架,为后续的分析提供基础,为rsop单元的r(resource资源)决策提供输入数据。帮助设计人员确定产品设计的基础和优化产品组合。
12、第二层级:产品量级关联,第二层是对第一层已识别产品属性关联的量化分析。将第一层中识别的产品属性关联通过遗传算法转化为具体的数值和量级,涉及产品的数量、质量、计量等方面,如每种组件的数量、尺寸、重量等。这一层的目的是将目标产品与材料产品之间建立基于产品属性的可量化数据关联,从而为优化决策与生产过程提供数值基础。
13、第三层级:业务数据关联,在第二层级基础上将产品数据与市场和业务因素结合,形成全面的策略,并延伸到更广泛的业务和市场分析。这一层不仅包括量价关系,还涵盖了时空、进度、环境、政策、价格,市场动态、交易支付、客户偏好、供应链管理等关键业务因素。这一层的分析对于制定市场策略、优化产品定价和预测需求至关重要。例如,根据材料成本、客户需求、市场趋势来定价产品、调整生产计划、管理库存等以应对市场变化。
14、作为优选方案,所述第一层级的产品网络构建中,进一步分为两个阶段:
15、第一阶段,优化模块度:
16、基于一种模块度优化的社群检测louvain网络算法,每个节点属于自己的社群。对于每个节点,算法考虑将其移动到其邻居的社区,并计算这种移动对模块度q的影响。如果任何移动可以提高q,则选择增加模块度q最多的移动。这一过程不断重复,直到无法进一步提高q为止。第二阶段,合并社群:
17、在第一阶段达到稳定状态后,算法将每个检测到的社群缩减成新的节点,并构建一个新的网络。其中,这些新节点是网络的顶点,边的权重是原始网络中社区间的边的总和。然后,算法在这个新网络上重复第一阶段的过程,直到社群不再发生变化。
18、作为优选方案,所述第一层级的产品关系n维向量产生中,当产品关系趋近稳定时,定义用于产品材料组合的表示一个向量t。即向量x在第一阶段通过louvain算法寻找所需要元素产品组合,形成t向量。
19、作为优选方案,所述第一层级的张量的动态更新中,随着产品关系的变化或新数据的加入,t作相应更新,以反映最新的产品组合信息,以分析哪些原材料和过程产品组合最有可能产生特定的最终产品。
20、作为优选方案,所述第二层级中,通过遗传算法,对多个组合变量通过选择、交叉、变异的遗传操作,并通过合适的适应度函数,进行优化。
21、本发明一种智能三层数据模型网络优化的企业决策方法及系统的原理与过程为:将目标产品可能的材料组合作为社区,为模型建立基础数据结构。重点是根据模块度(modularity:是一种常用的衡量节点分组质量的标准,模块度越高说明所检测到的社团越符合社团内部连接紧密,而社团外部的连接则相对稀疏,“内紧外松”的特征,分组质量越好)识别与特定产品直接相关的材料形成聚合,即louvain网络定义中的社群,为后续分析奠定基础。对已识别产品属性关联的量化分析,将产品属性关联通过遗传算法转化为具体的数值和量级,这涉及产品的数量、质量、计量等方面。结合广泛因素,如量价关系、时空因素、物流、环境、政策和客户喜好等等业务因素,利用前两层的数据寻找最优路径,同时考虑过程中可能出现的变更。这一层的关键在于运用数据驱动的方法来优化资源配置和运营效率。
22、本发明一种智能三层数据模型网络优化的企业资源配置决策方法更为具体的介绍如下:
23、第一层级:产品属性关联
24、首先构建产品网络:
25、应用louvain算法。对产品关系网络进行分析,以识别紧密相关的产品群体。这可以帮助设计人员理解哪些产品倾向于一起使用,形成强关联的组合。得到的社群结构为高阶张量的构建提供了基础,帮助设计人员确定哪些产品组合是关键的,应该在张量中表示。louvain算法是一种基于模块度优化的社群检测算法,它在网络中识别高度相互连接的节点群体。算法分为两个主要阶段:优化模块度和社群合并。
26、阶段1:优化模块度
27、模块度q的定义:
28、
29、其中,aij是节点i和j之间的边的权重(无边时为0);ki和kj是节点i和j的度(所有边的权重之和);m是网络中所有边的权重之和;ci和cj是节点i和j所属的社群标签;δ是一个指示函数,当ci=cj时为1,否则为0。初始时,每个节点属于自己的社群。然后,对于每个节点,算法考虑将其移动到其邻居的社区,并计算这种移动对模块度q的影响。如果任何移动可以提高q,则选择增加模块度q最多的移动。这一过程不断重复,直到无法进一步提高q为止。
30、阶段2:合并社群
31、第一阶段达到稳定状态后,算法将每个检测到的社群缩减成新的节点,并构建一个新的网络。其中,这些新节点是网络的顶点,边的权重是原始网络中社区间的边的总和。然后,算法在这个新网络上重复阶段1的过程,直到社群不再发生变化。
32、构造产品关系n维向量:
33、当产品关系趋近稳定时,定义一个向量t,用于产品材料组合的表示。向量x在第一阶段通过louvain算法寻找所需要元素产品组合,形成t向量。
34、这里每个产品材料组合由向量t=[t11,…,t1o,t21,…,t2p,…,tt1,…,ttq,id]表示,其中,1,…,t为原材料大类数目、id为目标产品所在维度,tij(i的范围为1到t,当i=1时,j=1到o,当i=2时,j=1到p,...,当i=t时,j=1到q)表示第i种原材料大类中的第j种材料小类的原材料用量,在这一阶段还没有确定,令用到某原材料时其用量标示为1,未用到其用量标示为0,总共有t种原材料大类。每个维度代表一个产品或产品类型,包括原材料、过程产品和最终产品,其中,最后一维代表目标产品所在维度id,由此表示一个可行的产品组合。
35、第二层级:产品量级关联
36、第二层是对第一层已识别产品属性关联的量化分析。将第一层中识别的产品属性关联通过遗传算法转化为具体的数值和量级,这涉及产品的数量、质量、计量等方面。如每种组件的数量、尺寸、重量等。具体步骤为:
37、步骤1:定义适应度函数
38、首先需要定义一个适应度函数,它可以根据原材料的组合和用量来评估产品的性能、成本效益或其他相关指标。根据所在行业,可以指定不同的评估产品性能的函数。以冶金行业为例,则希望最大化其强度同时最小化成本。适应度函数可以表示为强度与成本的某种组合:
39、fitness(x)=α×strength(x)-β×cost(x)
40、这里定义广义的适应度函数为:
41、fitness(x)=α×h(x)+β×f(x)+…+γ×g(x)
42、其中,x代表一个特定的原材料组合及其用量,h(x)、f(x)和g(x)是不同的评估产品性能评估的函数,而α、β和γ是各个评估函数的系数。
43、步骤2:初始化种群
44、接下来初始化种群,根据现有生产材料组合生成一批初始解,每个解代表一种原材料组合及其用量。生成一系列的原材料组合及其用量,每种组合构成一个潜在的解决方案,即一个“个体”。本发明从以下两个途径来初始化种群:从历史数据或实验结果中挑选出性能良好的原材料组合;对已有的优质组合进行微小的随机变化以生成新的组合,从而维持种群的多样性。
45、最后还可以将随机生成的个体与已有的优质组合相结合,创建一个多样化且具有潜在高适应度个体的初始种群。
46、每个原材料组合(个体)由向量
47、xt=[x11t,…,x1ot,x21t,…,x2pt,…,xt1t,…,xtqt]表示,其中,指的是第t种原材料组合(个体)中,第i种原材料大类中的第j种材料小类的用量,总共有t种原材料大类。随机初始化过程可以数学化表示为:
48、
49、这里,rand(lij,uij)是在原材料用量下限lij和上限uij之间生成随机数的函数。
50、步骤3:采用适应度函数fitness(x)对每个原材料组合(“个体”)进行适应度评估,评估每个原材料组合及其用量的适应度。
51、步骤4:进行遗传操作(选择、交叉和变异),进行选择时,根据个体的适应度从当前种群中选择适应度较高的个体,用于生成下一代的个体。交叉过程通过组合两个个体的基因来创造新个体,而变异则是通过随机改变个体中的某些基因来引入新的遗传多样性。
52、遗传操作中的选择、交叉和变异具体如下:
53、选择:根据个体的适应度从当前种群中选择适应度较高的个体,用于生成下一代的个体。采用一个常用的“轮盘赌”(roulette wheel)选择法;
54、计算种群中所有个体适应度的总和:
55、
56、其中,n是种群中个体的数量,xj是第j个个体,fitness(xj)是该个体的适应度;计算选择概率,对于每个个体,其被选中的概率p(xj)是其适应度与总适应度之比;
57、
58、接着计算累积概率,为了进行轮盘赌选择,计算个体的累积概率c(xj);
59、
60、最后可以选择个体,生成一个位于0和1之间的随机数r,选择满足r<c(xj)的第一个个体xj作为父代;例如,有一个由四个原材料组合(个体)组成的种群,其适应度分别为10,30,50,10。则每个个体的选择概率分别是:第一个个体0.1,第二个个体0.3,第三个个体0.5,第四个个体0.1,则累积概率分别是第一个个体0.1,第二个个体0.4,第三个个体0.9,第四个个体1.0。如果随机数是0.35,那么第二个个体会被选择作为父代,因为它是第一个使得累积概率大于0.35的个体。
61、交叉:对于父代个体和子代的下标为ij的基因表示为:
62、
63、变异:对于子代个体中的每个基因变异表示为:
64、
65、其中,表示对i基因的变异操作,它可以是基于某种概率分布的随机变化。
66、步骤5:进行迭代,重复3-4步骤,直到达到一定的迭代次数,或者找到了满意的解决方案。
67、最后,从最终种群中选择适应度最高的原材料组合及其用量个体x*。这样,通过交叉和变异产生的新组合形成新一代种群。
68、第三层级:业务数据关联
69、第二层基础上将产品数据与市场和业务因素结合,形成全面的策略,并延伸到更广泛的业务和市场分析。这一层不仅包括量价关系,还涵盖了时空、进度、环境、政策、价格、市场动态、交易支付、客户偏好、供应链管理等关键业务因素。
70、此层级为rsop单元(资源resource-现场site-作业operation-产品product)中的s(现场,site)与o(作业,operation)提供输入数据,负责实施具体的生产决策和记录结果,同时反馈信息以优化前两层的分析。
71、构建一个目标函数f(i),
72、
73、其中,f代表目标产品在第i种材料产品组合情况下的价值分,n是不同原材料组合的数量。xi:代表第i种原材料组合,也就是第一层关系中的张量t。q(xi):指明为了达到目标产品所需的特定量级或资源投入。w1,w2,…,wk指不同关键业务因素权重,反映了每个因素在总评分中的相对重要性。c,t,…,k等函数对应于不同评价因素的函数,如成本c、时间t和其他因素k,每个因素都是原材料组合xi和量级q(xi)的函数。
74、基于跨组织视角,三层模型需要建立主数据体系。传统主数据管理是复杂系统工程,传统主数据建立过程局限于企业内部,如果建立跨企业面向项目的主数据,需要新的设计思路和维度。数据是天然存在的,系统只是发现、采集、存储、计算数据。数据关系并不依赖企业,数据关系的落地是通过业务体现的。
75、按照业务设定配置型主数据与核心主数据。配置型主数据依据相关标准或规范,主数据在相当时期内处于稳定状态,不会轻易变化。核心主数据用来描述业务实体,不同业务域有不同主数据,共性主数据可以设为跨域主数据。用统一数据管理系统实现数据总线esb解决数据交互与分发。
76、本发明与现有技术相比,有益效果是:
77、本发明一种基于三层数据模型网络优化的企业资源配置决策方法及系统,将目标产品可能的材料组合作为社区,为模型建立基础数据结构,根据模块度(modularity:是一种常用的衡量节点分组质量的标准,模块度越高说明所检测到的社团越符合社团内部连接紧密,而社团外部的连接则相对稀疏,“内紧外松”的特征,分组质量越好)识别与特定产品直接相关的材料形成聚合,即louvain网络定义中的社群,为后续分析奠定基础;对已识别产品属性关联的量化分析,将产品属性关联通过遗传算法转化为具体的数值和量级,这涉及产品的数量、质量、计量等方面;结合广泛因素,如量价关系、时空因素、物流、环境、政策和客户喜好等等业务因素,利用前两层的数据寻找最优路径,同时考虑过程中可能出现的变更,此层的关键在于运用数据驱动的方法来优化资源配置和运营效率。
- 还没有人留言评论。精彩留言会获得点赞!