一种基于CPU-GPU协同计算的并发动态图快照处理方法
本发明涉及动态图计算领域,具体来说,涉及图处理的硬件加速领域,更具体地说,涉及一种基于cpu-gpu协同计算的并发动态图快照处理方法。
背景技术:
1、随着互联网技术的迅速发展,基于静态图的传统图计算已经难以满足复杂多样的用户需求。在许多现实场景,如社交网络、电商购物、金融交易、分子生物学领域中,图的拓扑结构和节点特征随着时间的推移而变化,衍生出对动态图数据的处理需求。
2、现有动态图主要有两种表示方法,连续时间动态图(continuous time dynamicgraphs,简称ctdgs)和离散时间动态图(discrete time dynamic graphs,简称dtdgs)。gtdgs允许节点和边在时间上连续地变化,节点和边可以在不同时间点上出现或消失。dtdgs描述的则是节点和边在离散时间点上的变化。在dtdgs中,时间被划分为固定的离散时间步长,每个时间步长表示图的一个快照,节点和边可以在每个时间步长上加入或删除,或者它们之间的连接可以发生变化。dtdgs对在多个图快照上并发执行多个图计算算法提出了需求,例如,广度优先搜索(breadth first search,简称bfs)、单源最短路径(singlesource shortest path,简称sssp)、网页排名(pagerank)算法等图计算算法,随着业务场景愈发广泛、用户规模愈发庞大,图数据的规模不断增长,并发的需求不断增加,使用中央处理器(central processing unit,简称cpu)执行图计算算法已然捉襟见肘。
3、目前主流的方法是使用图形处理器(graphics processing unit,简称gpu)执行这些图计算算法。例如参考文献[1],其适用于图形处理器的压缩内存阵列(graphicsprocessing unit packed memory array,简称gpma),实现了gpu器上的dtgds处理,并利用gpu强大的并行计算能力一定程度上提升动态图计算算法的执行性能。又例如参考文献[2],其为核外图计算框架异步子图处理框架(subgraph processing with asynchrony,简称subway),是一种在gpu上异步执行图计算算法的框架,可以实现静态图在gpu上的高效率处理。又例如参考文献[3],其为基于gpu的动态图处理系统(egraph),结合了gpma和subway,并实现并发的动态图处理任务,即:egraph充分利用了图快照间数据访问的相似性,将图快照划分为可共享分区和不可共享分区,例如相同背景下的多个快照图,背景部分均为相同数据,作为可共享分区,多个快照图中不同的动作间,相应变化的动作位置即为不相同的数据,作为不可共享分区。共享分区由多个图计算算法并发处理,不可共享分区则由多个图计算算法串行处理。egraph并发执行处理多个图快照的图计算算法的步骤包括:第1个图快照到第n个图快照(记为g1~gn)将分别由对应的第1个图计算算法到第n个图计算算法(记为s1~sn)处理,egraph首先从g1~gn中提取可以在多个快照间共享的共享分区gc,对于第1个图快照g1来说,不可共享分区gu1为g1-gc,也就是g1中扣除gc后剩下的部分,第2个图快照不可共享分区到第n个图快照的不可共享分区(记为gu2~gun)可由同样的步骤获取。共享分区gc原先存储在cpu侧的内存中,为了执行计算,将gc由cpu传输至gpu,并由s1~sn在gpu上并发执行计算。对于不可共享分区部分,首先将gu1从内存传输至gpu,再由s1执行计算。剩下的快照的不可共享分区部分串行执行,执行和gu1相似的操作。
4、通过上述分析,发现现有技术中由于图快照的不可共享数据较大,并且gpu相对cpu其存储空间较小,将共享分区和不可共享分区都传输至gpu计算会导致cpu-gpu通信带宽存在浪费的问题。另外,现有技术为实现数据处理同步,gpu仅对共享分区数据进行并发处理,对接收的不可共享分区数据进行串行处理,导致gpu计算资源存在大量浪费的问题。
5、需要说明的是:本背景技术仅用于介绍本发明的相关信息,以便于帮助理解本发明的技术方案,但并不意味着相关信息必然是现有技术。在没有证据表明相关信息已在本发明的申请日以前公开的情况下,相关信息不应被视为现有技术。
6、参考文献如下:
7、[1]sha m,li y,he b,等.accelerating dynamic graph analytics on gpus[j].proceedings of the vldb endowment,2017,11(1):107–120.
8、[2]sabet a h n,zhao z,gupta r.subway:minimizing data transfer duringout-of-gpu-memory graph processing[a].proceedings of the fifteenth europeanconference on computer systems[c].new york,ny,usa:association for computingmachinery,2020:1–16.
9、[3]zhang y,liang y,zhao j,等.egraph:efficient concurrent gpu-baseddynamic graph processing[j].ieee transactions on knowledge and dataengineering,2022:1–1.
技术实现思路
1、因此,本发明的目的在于克服上述现有技术的缺陷,提供一种基于cpu-gpu协同计算的并发动态图快照处理方法。
2、本发明的目的是通过以下技术方案实现的:
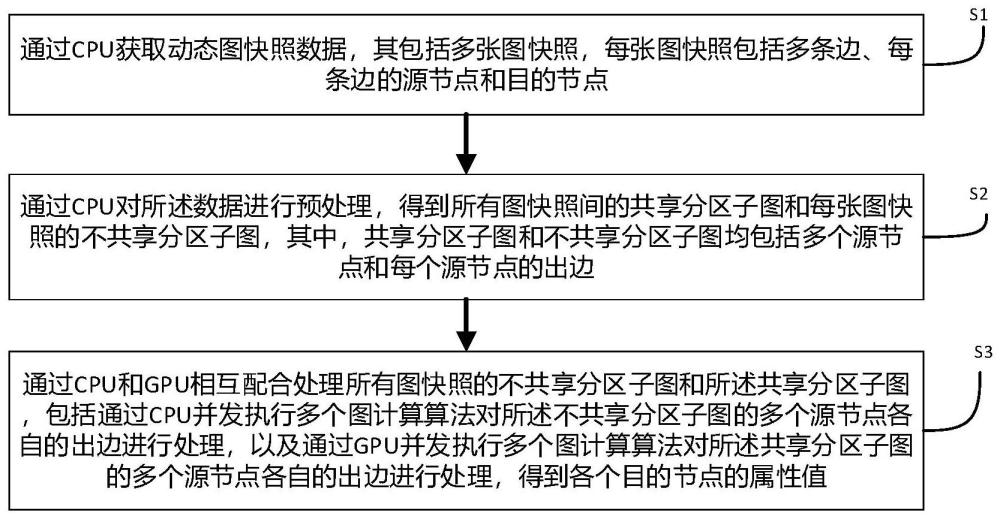
3、根据本发明的第一方面,提供一种基于cpu-gpu协同计算的并发动态图快照处理方法,包括:步骤s1、通过cpu获取动态图快照数据,其包括多张图快照,每张图快照包括多条边、每条边的源节点和目的节点;步骤s2、通过cpu对所述数据进行预处理,得到所有图快照间的共享分区子图和每张图快照的不共享分区子图,其中,共享分区子图和不共享分区子图均包括多个源节点和每个源节点的出边;步骤s3、通过cpu和gpu相互配合处理所有图快照的不共享分区子图和所述共享分区子图,包括通过cpu并发执行多个图计算算法对所述不共享分区子图的多个源节点各自的出边进行处理,以及通过gpu并发执行多个图计算算法对所述共享分区子图的多个源节点各自的出边进行处理,得到各个目的节点的属性值。
4、在本发明的一些实施例中,所述步骤s3包括:通过cpu按照预定规则确定共享分区子图中需要缓存的多个源节点各自的出边,并将所述出边传输至gpu的缓存区后,通过cpu和gpu相互配合对所有图快照的不共享分区子图和所述共享分区子图进行多轮迭代处理,直至每个子图中的所有源节点各自的所有出边处理完成,其中,每轮包括:步骤s31、获取当轮确定的多个活跃节点,其为当轮需要被处理的多个源节点,包括所有图快照的不共享分区子图的多个活跃节点、所述缓存区的多个活跃节点以及共享分区子图中未缓存的多个活跃节点;步骤s32、通过cpu并发执行多个图计算算法对所述不共享分区子图的多个活跃节点各自对应的源节点的出边进行处理,得到每条出边对应的目的节点的属性值,同时,将所述未缓存的多个活跃节点各自对应的源节点的出边传输至gpu;步骤s33、通过gpu并发执行多个图计算算法对缓存区的多个活跃节点各自对应的源节点的出边进行处理、以及对未缓存的多个活跃节点各自对应的源节点的出边进行处理,得到每条出边对应的目的节点的属性值;步骤s34、根据cpu和gpu各自在当轮得到的所有活跃节点的所有出边对应的目的节点的属性值确定下一轮的多个活跃节点。
5、在本发明的一些实施例中,所述共享分区子图和不共享分区子图均包括每个源节点的入度和出度,所述步骤s3中按预定规则确定所述出边并将所述出边传输至gpu的缓存区的方式包括:根据共享分区子图的n个源节点的入度,按照入度从大到小来排序n个源节点,得到从1到n排序的n个源节点,其中,n为共享分区子图的源节点总数量;根据排序后的n个源节点,对第1个源节点到第i个源节点的出度依次累加,得到第一个源节点到第i个源节点的出度累加和,其中,i为排序后的n个源节点的第i个源节点;在所述出度累加和首次大于预定数值时,将排序在第i个源节点前的i-1个源节点中每个源节点的出边传输到gpu的缓存区。
6、在本发明的一些实施例中,所述步骤s32包括:针对每张图快照开启一个图计算算法线程,多张图快照对应多个图计算算法线程;利用多个图计算算法线程并发处理多张图快照各自的不共享分区子图,包括通过每个图计算算法线程处理对应的一张图快照的不共享分区子图的多个活跃节点中每个活跃节点对应的源节点的出边,得到每条出边对应的目的节点的属性值;以及按照预定显存大小,对所述共享分区子图中未缓存的当轮所有活跃节点各自对应的源节点的出边进行一次或多次分块传输到gpu侧的显存中,每次分块传输包括多个活跃节点各自对应的源节点的出边。
7、在本发明的一些实施例中,所述步骤s33中对缓存区的多个活跃节点各自对应的源节点的出边进行处理的方式包括:获取缓存的多个活跃节点各自对应的源节点的出边,得到多条出边,针对多条出边的每条出边开启一个图计算算法线程,多条出边对应多个图计算算法线程;以及利用多个图计算算法线程并发处理多个活跃节点各自对应的源节点的出边,包括利用每个图计算算法线程处理对应的一条出边,处理完多条出边,得到每条出边对应的目的节点的属性值。
8、在本发明的一些实施例中,所述步骤s33中对未缓存的多个活跃节点各自对应的源节点的出边进行处理的方式包括:根据每次分块传输来的多个活跃节点各自的出度,确定所述多个活跃节点间的综合不平衡指数,所述指数用于指示各个活跃节点的出边数量的均衡程度;在所述指数大于等于预定指数阈值时,针对所述多个活跃节点的每个活跃节点开启一个图计算算法线程,多个活跃节点对应多个图计算算法线程;利用多个图计算算法线程并发处理未缓存的多个活跃节点,包括通过每个图计算算法线程处理对应的一个活跃节点对应的源节点的出边,得到每条出边对应的目的节点的属性值。
9、在本发明的一些实施例中,所述步骤s33中对未缓存的多个活跃节点各自对应的源节点的出边进行处理的方式还包括:在所述指数小于预定指数阈值时,根据所述多个活跃节点各自对应的源节点的出边确定需处理的多条出边,按照预定出边数量将所述多条出边划分为多组出边,为每组出边开启一个图计算算法线程,多组出边对应多个图计算算法线程;利用多个图计算算法线程并发处理所述多组出边,包括利用每个图计算算法线程处理对应的一组出边,处理完每组出边的每条出边,得到每条出边对应的目的节点的属性值。
10、在本发明的一些实施例中,所述综合不平衡指数的确定方式如下:
11、
12、其中,n表示每次分块传输来的多个活跃节点的数量,i表示活跃节点的序号,di表示第i个活跃节点的出度,d表示多个活跃节点的出度总和,表示多个活跃节点的平均出度。
13、在本发明的一些实施例中,所述每个源节点对应一个编号,其中,所述步骤s31中当轮的多个活跃节点的确定方式包括:获取cpu侧的源节点位图、gpu侧的原始源节点位图、gpu侧的缓存源节点位图和gpu侧的未缓存源节点位图,其中,cpu侧的源节点位图用于指示对应不共享分区子图中是否存在对应编号的源节点,所述原始源节点位图用于指示共享分区子图中是否存在对应编号的源节点,所述未缓存源节点位图用于指示未缓存的共享分区子图中是否存在对应编号的源节点,所述缓存源节点位图用于指示缓冲区是否缓存对应编号的源节点;所述不共享分区子图的多个活跃节点根据活跃节点位图和cpu侧的源节点位图确定,其中,首轮中的活跃节点位图为初始化生成,首轮之后的每轮中的活跃节点位图根据当轮得到的所有出边对应的目的节点的属性值确定;所述未缓存的多个活跃节点根据联合活跃节点位图、gpu侧的原始源节点位图和所述未缓存源节点位图确定,其中,首轮中的联合活跃节点位图根据首轮中的活跃节点位图确定,首轮之后的每轮中的联合活跃节点位图根据对应轮的活跃节点位图确定;所述缓存区的多个活跃节点根据联合活跃节点位图、gpu侧的原始源节点位图和所述缓存源节点位图确定。
14、在本发明的一些实施例中,每张图快照还包括每条边的权重,所述步骤s2中预处理的方式包括:获取所有图快照间存在权重、源节点和目的节点均相同的边,得到所有图快照间的共享分区子图;确定每张图快照与所述共享分区子图间的差集,得到每张图快照的不共享分区子图。
15、根据本发明的第二方面,提供一种基于本发明第一方面所述方法实现的图处理系统,包括cpu和gpu,其中,cpu被配置为:获取动态图快照数据,其包括多张图快照,每张图快照包括多条边、每条边的源节点和目的节点;对所述数据进行预处理,得到所有图快照间的共享分区子图和每张图快照的不共享分区子图,其中,共享分区子图和不共享分区子图均包括多个源节点和每个源节点的出边;以及并发执行多个图计算算法对所有图快照各自的不共享分区子图的多个源节点各自的出边进行处理,得到所述不共享分区子图的每条出边对应的目的节点的属性值;gpu被配置为:并发执行多个图计算算法对所述共享分区子图的多个源节点各自的出边进行处理,得到所述共享分区子图的各个目的节点的属性值;其中,根据所述不共享分区子图的每个目的节点的属性值和所述共享分区子图的每个目的节点的属性值得到对应目的节点的最终属性值。
16、根据本发明的第三方面,提供一种电子设备,包括:一个或多个处理器;以及存储器,其中存储器用于存储可执行指令;所述一个或多个处理器被配置为经由执行所述可执行指令以实现本发明的第一方面中任一项所述方法的步骤。
17、与现有技术相比,本发明的优点在于:
18、本发明方法通过将不共享分区子图的计算卸载至cpu进行计算,不用将不共享分区子图传输至gpu,减少了cpu端和gpu端之间的数据传输量,大量节省了cpu-gpu间传输带宽资源;同时,gpu上执行的计算只有并发任务处理,提升了gpu计算资源的利用率;并通过cpu-gpu异构计算的模式实现动态图快照的并发处理,即由cpu和gpu相互配合,通过cpu并发执行多个图计算算法对多张不共享分区子图进行处理,以及通过gpu并发执行多个图计算算法对共享分区子图进行处理,cpu和gpu同时并发处理对应的图数据,极大地提升了并发图处理的执行效率,以及提高了硬件利用效率。
19、本发明一方面通过在gpu中缓存共享分区子图中的高入度节点的出边,进一步减少了cpu端和gpu端之间的数据传输量;另一方面,通过计算综合不平衡指数,自适应切换并发方式,避免线程负载不均衡导致的并发效率低,进一步提升了并发执行速度,提高了cpu和gpu计算资源的利用效率。
- 还没有人留言评论。精彩留言会获得点赞!