隐私化随机森林模型的构建方法、装置、设备及存储介质
本发明属于机器学习和信息保护,尤其涉及一种隐私化随机森林模型的构建方法、装置、设备及存储介质。
背景技术:
1、随机森林的基学习器模型是决策树,决策树的分支节点以及叶子节点均包含存储着训练数据的统计信息,如果在建立决策树模型时获得这些统计信息时不经过任何脱敏操作,那么当这些信息不经意间被攻击者获得后就很可能导致个人隐私的泄露。而使用差分隐私构建决策树可以防止恶意的攻击者通过观察、对比以及分析等一系列合法或者非法的手段窃取训练数据集中的个人隐私信息。使用差分隐私避免决策树导致的隐私泄露问题的关键在于:使决策树在访问训练数据时满足差分隐私。根据决策树不同的位置访问训练数据的方式不同,差分隐私决策树算法(decision tree with differential privacy,简称dpdt算法)实现差分隐私的方式也不一样,具体地,当位于决策树的分支节点时,dpdt算法使用指数机制避免特征划分带来的隐私泄露风险,当位于决策树的叶子节点时,dpdt算法采用拉普拉斯机制避免计数统计引发的隐私泄露风险。然而,dpdt算法在分支节点的创建过程中使用指数机制输出分裂特征,使得特征选择过程中的相关统计结果受到扰动,从而影响了划分效果;而对于叶子节点,dpdt算法使用拉普拉斯噪声隐藏叶子节点中与训练数据相关的信息以实现差分隐私,虽然这种方法很好地利用了对互斥的数据进行并行查询的优势,同时也通过掩盖真实的计数情况在极大程度上防止个人隐私泄露,但是由于每个类别标签计数都需要进行噪声添加,这种做法不仅容易增加模型的不稳定性,同时也忽略了拉普拉斯噪声的双向性质带来的负面影响。因此,使用dpdt算法创建决策树,可以使训练数据蕴含的个人隐私信息得到强有力的保障,然而,dpdt算法也容易在决策树模型中引入过多的噪声,导致节点的学习性能显著下降,从而降低了整个模型的可靠性。
技术实现思路
1、本发明的目的在于提供一种隐私化随机森林模型的构建方法、装置、设备及存储介质,旨在解决由于现有技术导致随机森林模型精度不高、可靠性低、且容易造成个人隐私泄露的问题。
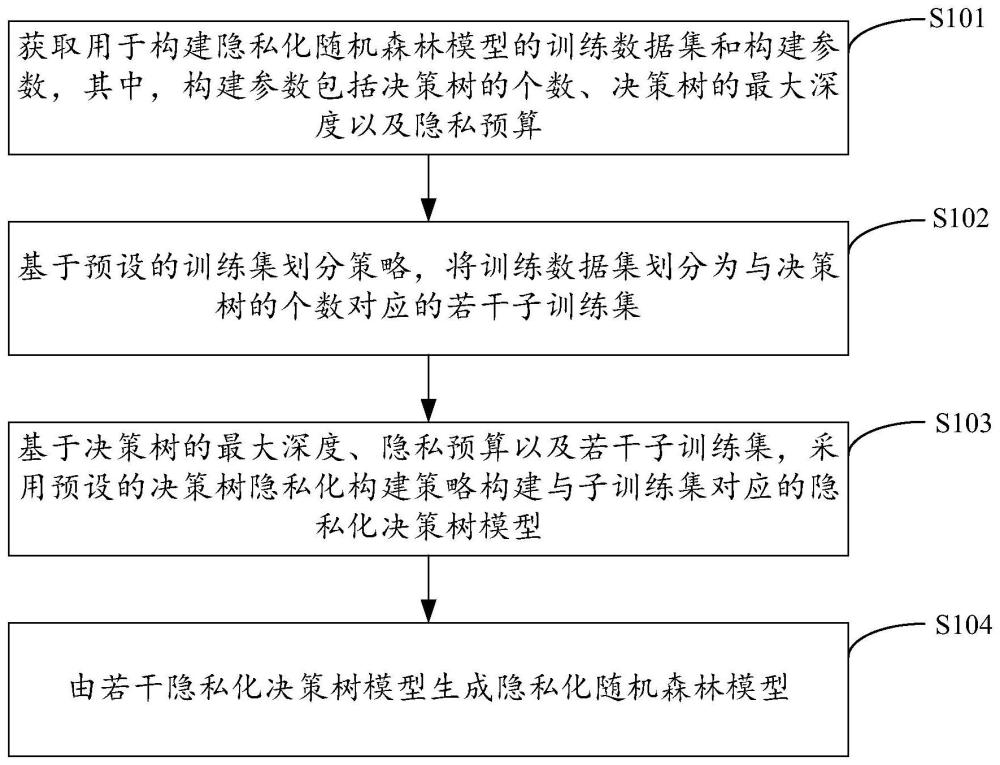
2、一方面,本发明提供了一种隐私化随机森林模型的构建方法,所述方法包括下述步骤:
3、获取用于构建隐私化随机森林模型的训练用隐私数据集和构建参数,其中,所述构建参数包括决策树的个数、决策树的最大深度以及隐私预算;
4、基于预设的训练集划分策略,将所述训练用隐私数据集划分为与所述决策树的个数对应的若干子训练集;
5、基于所述决策树的最大深度、所述隐私预算以及若干所述子训练集,采用预设的决策树隐私化构建策略构建与所述子训练集对应的隐私化决策树模型;
6、由若干所述隐私化决策树模型生成所述隐私化随机森林模型。
7、优选地,所述采用预设的决策树隐私化构建策略构建与所述子训练集对应的隐私化决策树模型的步骤,包括:
8、对于每个所述子训练集,将所述子训练集设置为所述隐私化决策树模型的根节点对应的节点训练集,并将所述根节点设置为当前节点,同时获取所述节点训练集的特征集合;
9、判断所述节点训练集的特征集合是否为空集或者所述当前节点所在的当前深度是否达到所述最大深度或者所述节点训练集的标签集合中标签的个数是否为1;
10、是则,将所述当前节点确定为叶子节点,并基于预设的叶子节点标签查询策略确定所述叶子节点的标签;
11、否则,将所述当前节点确定为分支节点,并基于预设的分裂特征查询策略得到所述分支节点的分裂特征;
12、基于所述分裂特征和所述节点训练集,确定所述分支节点对应的子节点和每个子节点对应的子节点训练集;
13、对所述当前深度和所述特征集合进行更新,并对于每个子节点,将所述子节点作为所述当前节点,将所述子节点对应的所述子节点训练集作为所述节点训练集,将更新后的特征集合作为所述节点训练集的特征集合,跳转至判断所述节点训练集的特征集合是否为空集或者所述当前节点所在的当前深度是否达到所述最大深度或者所述节点训练集的标签集合中标签的个数是否为1的步骤,直至所有节点均被确定为叶子节点,完成所述隐私化决策树模型的构建。
14、优选地,所述基于预设的叶子节点标签查询策略确定所述叶子节点的标签的步骤,包括:
15、采用预设的标签效用函数计算所述节点训练集的标签集合l中每个标签对应的标签效用分数,并根据计算得到的所有标签的所述标签效用分数确定出最大标签效用分数;
16、对所述标签集合l执行随机排列操作,生成一个新的标签集合u;
17、对所述标签集合u中的每个标签进行遍历,对于当前遍历到的标签,基于所述标签对应的所述标签效用分数和所述最大标签效用分数,计算所述标签被选为叶子节点标签的标签概率;
18、根据计算得到的所述标签概率,生成一个服从伯努利分布的标签随机数;
19、判断所述标签随机数是否为1,是则,将所述标签确定为所述叶子节点的标签,否则,继续遍历所述标签集合u中的下一个标签,直到找到满足条件的标签或者遍历完所述标签集合u。
20、优选地,所述基于所述标签对应的所述标签效用分数和所述最大标签效用分数,计算所述标签被选为叶子节点标签的标签概率的步骤,包括:
21、计算所述标签效用分数和所述最大标签效用分数之间的效用分数差;
22、根据预先分配的叶子隐私预算和所述效用分数差,采用预设的标签概率计算公式对所述标签被选为叶子节点标签的所述标签概率进行计算。
23、优选地,所述基于预设的分裂特征查询策略得到所述分支节点的分裂特征的步骤,包括:
24、采用预设的特征效用函数计算所述特征集合f中每个特征对应的特征效用分数,并根据计算得到的所有特征的所述特征效用分数确定出最大特征效用分数;
25、对所述特征集合f执行随机排列操作,生成一个新的特征集合b;
26、对所述特征集合b中的每个特征进行遍历,对于当前遍历到的特征,基于所述特征对应的所述特征效用分数和所述最大特征效用分数,计算所述特征被选为分裂特征的特征概率;
27、根据计算得到的所述特征概率,生成一个服从伯努利分布的特征随机数;
28、判断所述特征随机数是否为1,是则,将所述特征确定为所述分支节点的分裂特征,否则,继续遍历所述特征集合b中的下一个特征,直到找到满足条件的特征或者遍历完所述特征集合b。
29、优选地,所述采用预设的特征效用函数计算所述特征集合f中每个特征对应的特征效用分数的步骤,包括:
30、对于所述特征集合f中的第a个特征fa,统计所述特征fa对应的训练样本的样本值为vj的样本数量同时统计所述特征fa对应的训练样本的样本值为vj且标签为lk的样本数量
31、基于所述样本数量和所述样本数量采用所述特征效用函数计算所述特征fa对应的特征效用分数。
32、另一方面,本发明提供了一种隐私化随机森林模型的构建装置,所述装置包括:
33、构建信息获取单元,用于获取用于构建隐私化随机森林模型的训练用隐私数据集和构建参数,其中,所述构建参数包括决策树的个数、决策树的最大深度以及隐私预算;
34、训练集划分单元,用于基于预设的训练集划分策略,将所述训练用隐私数据集划分为与所述决策树的个数对应的若干子训练集;
35、决策树构建单元,用于基于所述决策树的最大深度、所述隐私预算以及若干所述子训练集,采用预设的决策树隐私化构建策略构建与所述子训练集对应的隐私化决策树模型;
36、随机森林生成单元,用于由若干所述隐私化决策树模型生成所述隐私化随机森林模型。
37、优选地,所述决策树构建单元包括:
38、根节点设置单元,用于对于每个所述子训练集,将所述子训练集设置为所述隐私化决策树模型的根节点对应的节点训练集,并将所述根节点设置为当前节点,同时获取所述节点训练集的特征集合;
39、节点条件判断单元,用于判断所述节点训练集的特征集合是否为空集或者所述当前节点所在的当前深度是否达到所述最大深度或者所述节点训练集的标签集合中标签的个数是否为1;
40、叶子标签确定单元,用于是则,将所述当前节点确定为叶子节点,并基于预设的叶子节点标签查询策略确定所述叶子节点的标签;
41、分裂特征获得单元,用于否则,将所述当前节点确定为分支节点,并基于预设的分裂特征查询策略得到所述分支节点的分裂特征;
42、子节点确定单元,用于基于所述分裂特征和所述节点训练集,确定所述分支节点对应的子节点和每个子节点对应的子节点训练集;
43、决策树递归构建单元,用于对所述当前深度和所述特征集合进行更新,并对于每个子节点,将所述子节点作为所述当前节点,将所述子节点对应的所述子节点训练集作为所述节点训练集,将更新后的特征集合作为所述节点训练集的特征集合,触发所述节点条件判断单元执行对应的功能,直至所有节点均被确定为叶子节点,完成所述隐私化决策树模型的构建。
44、另一方面,本发明还提供了一种计算设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述隐私化随机森林模型的构建方法所述的步骤。
45、另一方面,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如上述隐私化随机森林模型的构建方法所述的步骤。
46、本发明获取用于构建隐私化随机森林模型的训练用隐私数据集和构建参数,其中,构建参数包括决策树的个数、决策树的最大深度以及隐私预算,基于预设的训练集划分策略,将训练用隐私数据集划分为与决策树的个数对应的若干子训练集,基于决策树的最大深度、隐私预算以及若干子训练集,采用预设的决策树隐私化构建策略构建与子训练集对应的隐私化决策树模型,由若干隐私化决策树模型生成隐私化随机森林模型,从而使得用于创建决策树模型节点的信息都是经过脱敏的,在提高了隐私保护性的同时降低了噪声,提升了模型节点的学习能力以及随机森林模型的性能和精度。
- 还没有人留言评论。精彩留言会获得点赞!