基于CLIP类别增量学习的图像分类方法及系统
本发明涉及图像处理,特别是涉及一种基于clip类别增量学习的图像分类方法及系统。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
2、在图像分类领域,比如机器人目标检测任务中,传统的目标检测框架如神经网络模型,仅适用于静态环境下的情况,从环境图像中生成未知目标的特征向量,与已知目标的特征向量进行比较,虽然可以识别出未知目标,但所有的未知目标均归为一类,且不能增量式地学习新类,缺乏在动态变化的环境中自适应和更新的灵活性。而在现实世界场景中,经常会遇到未知的目标类别,这些类别在训练数据中没有出现过,这就要求针对图像分类的训练既能适应新知识,又能保留旧知识。
3、若模型不更新,随着时间的推移,模型陈旧会降低模型的性能。此外,由于隐私和存储限制,旧数据可能不可用或只能部分访问,这导致来自旧类别的数据稀缺,从而造成数据分布的严重不平衡。因此,模型更加偏向于当前数据,并忘记了从旧数据中获得的知识,这种现象被称为灾难性遗忘。因此,持续学习的挑战在于平衡可塑性和稳定性,即模型能够在不忘记旧知识的情况下学习新知识,并在不同任务中重用和扩展经验知识。
4、类别增量学习(class-incremental learning,cil)是一种持续学习场景,涉及从由随时间增加的新类组成的数据流中学习,包括三类方法:基于正则化的方法、基于重放的方法和基于参数隔离的方法。这些方法旨在通过向损失函数中添加正则化项、重放旧数据样本或为每个类分配专用参数来保留先前知识的记忆。然而,这些方法大多数依赖于从头开始训练的模型,这对于从增量数据中学习可能不是最佳的。
5、大规模数据集上的预训练模型在下游任务中表现出了出色的泛化能力和抗灾难性遗忘的鲁棒性。此外,视觉语言预训练模型(contrastive language-image pre-training,clip)在持续学习中表现出强大的零射击能力和对下游任务的高适应性。利用预训练模型出色的特征提取能力,每一步增量只需要更新少量的参数,降低遗忘风险。相比之下,从头开始训练的模型没有这种优势,并且可能遭受严重的性能下降。
6、目前,预训练模型的持续学习主要有两种策略:一种是对模型进行微调;另一种是在模型上不断扩展少量参数,如基于提示的方法或添加适配器。即使采用正则化约束来避免不必要的调整,微调模型也可能损害原始模型的特征提取能力,并导致灾难性遗忘。扩展参数可以减轻对原始模型的干扰,但随着时间的推移会增加时间和空间成本。同时,对于视觉语言预训练模型,语言编码器提供丰富的信息,有利于持续学习。然而,在大多数现有的方法中,文本特征仅用于分类目的,并且它们帮助减少遗忘的潜力没有得到充分的探索。那么,针对预训练模型训练效果不佳,分类精度不高的问题,在执行具体的如机器人目标检测任务时,会存在目标检测准确度低、误检、漏检等问题。
技术实现思路
1、为了解决上述问题,本发明提出了一种基于clip类别增量学习的图像分类方法及系统,根据图像的文本特征相似度选择筛选相邻类别,调整受相似新类影响的旧类的特征表示,同时结合分解参数融合策略减少由于学习新类而导致的旧类遗忘,由此提高图像分类准确度。
2、为了实现上述目的,本发明采用如下技术方案:
3、第一方面,本发明提供一种基于clip类别增量学习的图像分类方法,包括:
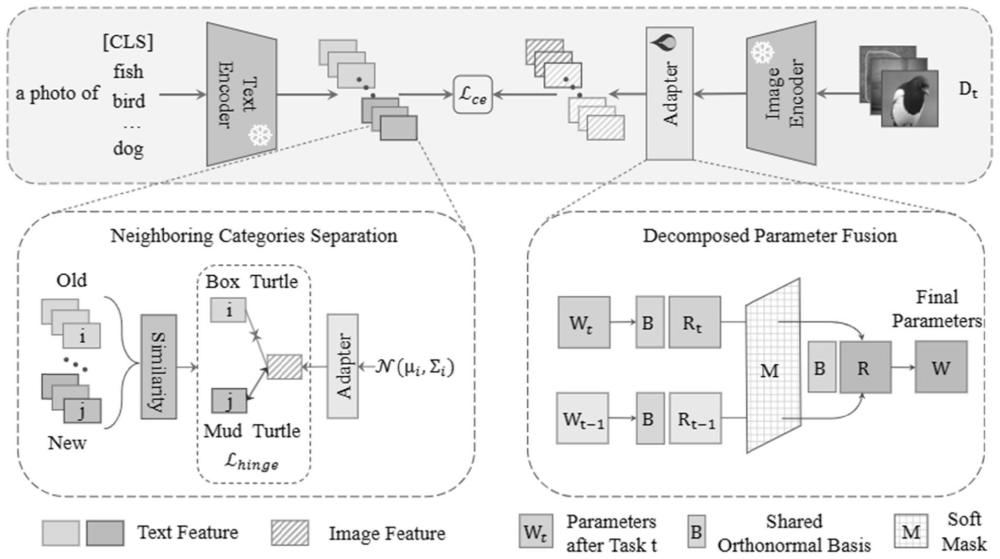
4、构建预训练的clip模型,包括图像编码器、文本编码器和分别设置于图像编码器和文本编码器之后的适配器;
5、获取训练图像及对应的文本标签,分别采用图像编码器和文本编码器提取图像特征和文本特征,以对适配器进行训练;
6、其中,在训练过程中,根据新输入的训练图像的文本特征和旧类别文本特征的相似度,筛选相邻类别的新旧类别对,对每对相邻类别中的旧类别文本特征,采用正态分布进行采样,以此构建铰链损失函数;在完成第t个训练任务后,将前一训练任务的适配器参数与当前训练任务的适配器参数进行融合,从而得到当前训练任务的最终适配器参数;
7、对待处理图像采用对适配器训练后的clip模型得到分类结果。
8、作为可选择的实施方式,以新旧类别的文本特征间的欧几里德距离作为相似度,将相似度小于设定阈值的新旧类别对作为相邻类别的新旧类别对;对每对相邻类别中的旧类别文本特征,计算质心和协方差矩阵,基于此从高斯分布中进行采样。
9、作为可选择的实施方式,以铰链损失函数与交叉熵损失函数的和作为训练过程的总损失函数;铰链损失函数为:
10、
11、其中,m为常数,c和分别表示属于相邻类别集的第k对相邻类别中的旧类别和新类别;ftext(tc)和分别为旧类别文本特征和新类别文本特征;a(·)表示适配器;表示旧类别文本特征的采样数据;dist(·)表示距离函数。
12、作为可选择的实施方式,适配器参数融合过程包括:将当前训练任务的适配器参数和前一训练任务的适配器参数分解到相同的标准正交基,根据分解后的当前训练任务的分解参数和前一训练任务的分解参数的差值计算融合权值,根据融合权值对当前训练任务的分解参数和前一训练任务的分解参数进行融合,得到融合参数,根据融合参数和标准正交基得到最终适配器参数。
13、作为可选择的实施方式,融合权值m为:
14、
15、其中,rt为当前训练任务的分解参数,rt-1为前一训练任务的分解参数,b为常数。
16、作为可选择的实施方式,融合参数r和最终适配器参数w分别为:
17、r=(j-m)⊙rt-1+m⊙rt;
18、w=br;
19、其中,j表示所有1的矩阵;⊙为逐元素乘法;b为标准正交基;rt为当前训练任务的分解参数,rt-1为前一训练任务的分解参数;m为融合权值。
20、第二方面,本发明提供一种基于clip类别增量学习的图像分类系统,包括:
21、模型构建模块,被配置为构建预训练的clip模型,包括图像编码器、文本编码器和分别设置于图像编码器和文本编码器之后的适配器;
22、训练模块,被配置为获取训练图像及对应的文本标签,分别采用图像编码器和文本编码器提取图像特征和文本特征,以对适配器进行训练;
23、其中,在训练过程中,根据新输入的训练图像的文本特征和旧类别文本特征的相似度,筛选相邻类别的新旧类别对,对每对相邻类别中的旧类别文本特征,采用正态分布进行采样,以此构建铰链损失函数;在完成第t个训练任务后,将前一训练任务的适配器参数与当前训练任务的适配器参数进行融合,从而得到当前训练任务的最终适配器参数;
24、分类模块,被配置为对待处理图像采用对适配器训练后的clip模型得到分类结果。
25、第三方面,本发明提供一种电子设备,包括存储器和处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成第一方面所述的方法。
26、第四方面,本发明提供一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成第一方面所述的方法。
27、第五方面,本发明提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现完成第一方面所述的方法。
28、与现有技术相比,本发明的有益效果为:
29、本发明提出一种基于clip类别增量学习的图像分类方法及系统,利用图像的文本特征来增强类别增量学习中相邻类别的分类能力,减少由于学习新类而导致的旧类遗忘。当新类别出现时,新的决策边界可能会将一部分旧类别样本划分到新类别中。为了解决这个问题,本发明利用文本特征,推断出新旧类别间的关系,加强相邻类别的分离。本发明通过计算新旧类别文本特征之间的距离来选择相邻类别对,由于新的类别有足够的数据来学习,不需要修改它的表示,专注于调整受新类别影响的旧类别的表示,从而减少由于学习新类而导致的旧类遗忘。
30、本发明提出一种基于clip类别增量学习的图像分类方法及系统,针对预训练模型的线性层适配器,提出分解参数融合方法,该方法不会随着训练任务的增加而增加参数数量。与直接计算参数平均值不同,本发明的融合策略更细粒度,并考虑了任务之间的共享知识。为了平衡稳定性和可塑性,根据学习当前任务引起的参数变化,对增量任务前后的参数进行合并,不需要在训练过程中增加额外的蒸馏损失来约束参数的变化,从而降低训练成本。
31、本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!