流式张量处理器的制作方法
本技术实施例涉及数据库领域,特别涉及一种用于加速神经网络计算的流式张量处理器。
背景技术:
1、在现代化社会和工业中,比如互联网、大数据、物联网、自动驾驶等领域,基于神经网络的人工智能的使用可以大幅提高效率、降低成本,使用度日益广泛。而神经网络内的输入、输出和变换可以用张量来表示,例如表示神经网络层之间的连接的权重以及表示通过神经网络传播的数据结构,因此神经网络的计算就是张量操作,用于加速神经网络计算的处理也可称之为张量处理器。
2、目前业界主流的神经网络加速器以通用计算图形处理器(gpgpu)为主,另外也有基于精简指令处理器(risc)内核的加速器,不管是gpgpu还是risc加速器,本质上都是众核架构,也即加速器芯片内部有非常多的计算核心,通常情况下从128个到4096个不等。此类众核处理器的架构一般采用图1中示出的系统架构实现,图1架构中的单个计算核心有独立的指令、数据缓存(cache)和处理电路,比如取指、译码、执行、写回等;单个计算核心有独立的本地加速器,比如单指令多数据(simd)运算器,或者向量运算器(vector)以及矩阵乘加(matrix multiplier and adder)运算器;多个计算核心之间通过通用或专门总线进行核心间连接,通过多层次和多级缓冲器(buffer)进行数据交换;多个计算核心之上需要一个总的计算核心来进行任务调度或分发。
3、对于上述的多核架构,每个计算核心都需要一套指令执行电路,而实际运算中不同计算核心处理的是同一个任务,所以执行的指令是完全一致的,这就导致电路被浪费;多个计算核心和多个缓存、缓冲通过带协议的总线连接导致电路设计复杂度上升;多个核心之间的通路距离长短不一致导致通讯延时不确定,导致某些计算核心会空等,影响计算效率;多个核心需要相互配合完成计算任务,但是指令和数据又需要独立分配和控制,导致编译器复杂度大幅上升;多个核心的连接关系导致设计规模缩放效率低下,进而导致不同算力芯片的设计复用度大大降低。以上的众核设计都会带来电路面积过大或编程方式复杂,从而对芯片成本和效率造成负面影响。
技术实现思路
1、本技术实施例提供面向向量数据库的混合加速架构,解决使用软件加速数据库查询向量速度慢和牺牲结果质量的问题。
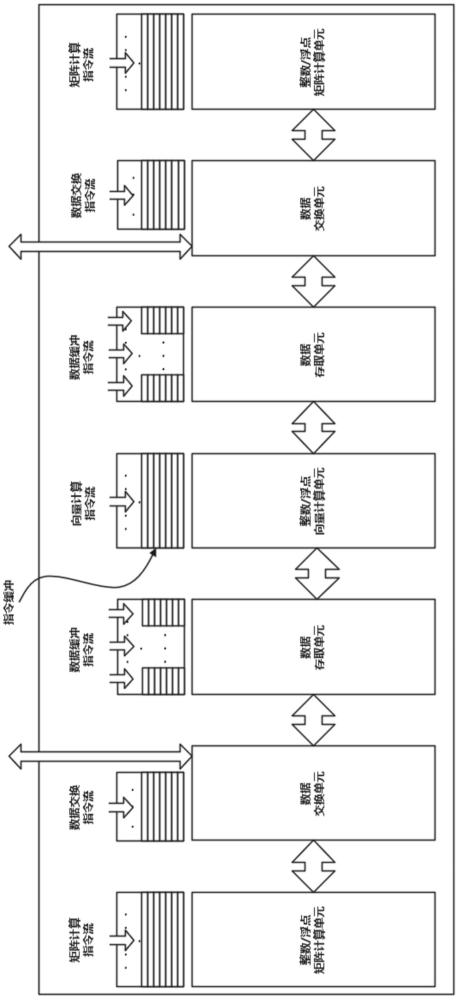
2、本技术提供了面向向量数据库的混合加速架构,包括阵列设计的一组向量计算模块,至少两组结构相同的数据存取模块、数据交换模块和矩阵计算模块;所述向量计算模块位于阵列中心,从中心向两侧依次级联数据存取模块、数据交换模块与矩阵计算模块,形成对称结构;
3、所述向量计算模块中设置有向量计算指令单元和包含n层向量计算块的向量计算单元,向量计算指令单元接收和缓存向量计算指令流,根据时序控制向量计算单元执行向量计算操作;
4、所述数据存取模块中设置有存取指令单元和包含n层存取块的数据存取单元,数据存取指令单元接收和缓存数据缓冲指令流,根据时序控制数据存取单元执行数据存/取操作;
5、所述数据交换模块中设置有数据交换指令单元和包含n层交换块的数据交换单元,数据交换指令单元接收和缓存数据交换指令流,根据时序控制数据交换单元将存取块和矩阵计算块中的数据进行交换;
6、所述矩阵计算模块中设置有矩阵计算指令单元和包含n层矩阵计算块的矩阵计算单元,矩阵计算指令单元接收和缓存矩阵计算指令流,根据时序控制矩阵计算单元执行矩阵运算;
7、两组数据交换单元分别通总线连接内存控制器;运行在外部cpu的编译器通过总线并根据时序向各个指令单元发送操作指令;内存控制器连接外部存储器,向数据交换单元输入原始数据或缓存结果数据。
8、具体的,相同的功能模块共享一套指令电路,且指令流根据时序在内部的功能单元中以流水模式传递,并以流水模式在相邻功能模块内的功能单元之间传输数据和执行功能操作;
9、其中的向量计算模块执行定点/浮点型向量乘加运算,矩阵计算模块执行定点/浮点矩阵乘加运算,数据交换模块执行矩阵交换、矩阵转置、行/列交换、行/列移位操作。
10、具体的,每个功能单元中的n层功能块的结构相同,分别形成n个层级深度的矩阵;相邻功能单元中同一层级的功能块之间相互通信连接,数据以流水线模式横向传递;每个功能单元中的指令流以n个层级深度的流水线模式纵向传递。
11、具体的,各个功能单元中的功能块分别设置有一一对应的指令寄存器;位于同一功能单元中的n层指令寄存器级联,指令流根据时序和层级深度单向传输,并控制对应的功能块执行功能操作。
12、具体的,位于同一层级的相邻功能块之间设置有数据寄存器,数据通过数据寄存器横向传递,且每个时钟周期进行双向传输。
13、具体的,位于同一层级的所有功能块、数据寄存器和指令寄存器形成超级功能块,且超级功能块的数量与各个功能单元中的功能块数量相同,所有超级功能块的结构相同;在每个时序向同一超级功能块传输的是同一笔操作指令,同一功能单元中的功能块根据顺序执行同一条指令或空操作nop指令。
14、具体的,所述数据交换单元中不同层级的数据交换块相互级联,将数据在不同层级间交换。
15、具体的,所述数据交换单元中每个层级包含有至少两个并列的数据交换块,两个并列的数据交换块分别连接相邻的数据寄存器;
16、位于不同列且不同层级的两个数据交换块执行跨模块跨层级的数据交换;
17、位于不同列且相同层级的两个数据交换块执行跨模块同层级的数据交换。
18、具体的,各个指令单元内部设置有若干级联的fifo缓冲器,根据时序将缓存的指令流逐次发送到对应指令单元中的指令寄存器。
19、具体的,不同功能块之间通过不同深度的nop指令控制指令的时序对齐。
20、具体的,每个超级功能块中的功能块和数据寄存器使用一路供电网络,所有超级功能块中的指令寄存器使用另一路供电网络。
21、具体的,当其中一组超级功能块出现损坏时,指令将正常跳转至下一超级功能块中执行,且电源控制电路会关闭损坏超级功能块中功能块和数据寄存器的供电网络。
22、本技术实施例提供的技术方案带来的有益效果至少包括:
23、该处理器架构和传统架构相比完全取消了处理核心,而是矩阵式的各种功能模块,并以外部cpu编译器发出的指令流来执行,且各个处理块之间严格根据时序对齐操作执行,克服众核架构指令数据不同步和各种不确定延迟的缺陷。
24、支持标量运算(由向量模块实现)、向量和矩阵计算,支持定点和浮点的灵活计算;
25、不同功能单元配备独立的指令单元,可以进行独立控制;
26、相同功能单元共享一套指令电路,节省指令电路;
27、不同的功能单元之间采用流水式数据传输,无需总线,通讯延时低、效率高;
28、所有功能模块整体组成一个计算加速器,不同功能模块相当于是传统cpu计算核心的不同流水电路,都是全局可见不分层,降低了编程难度;
29、指令、计算、数据存储在整个处理器上没有复杂通讯开支,且时序完全根据功能单元和功能块之间的距离预知,提高了编程效率降低了编译器难度;
30、总体算力和数据存储容量都可以通过简单的设计配置实现缩放,且编程方式不改变,节省人力提高效率;
31、相同模块和单元的电路设计完全一致,大大提高了逻辑和物理电路复用率,降低芯片设计难度。
- 还没有人留言评论。精彩留言会获得点赞!