一种行为克隆强化学习的零碳园区调度方法及系统与流程
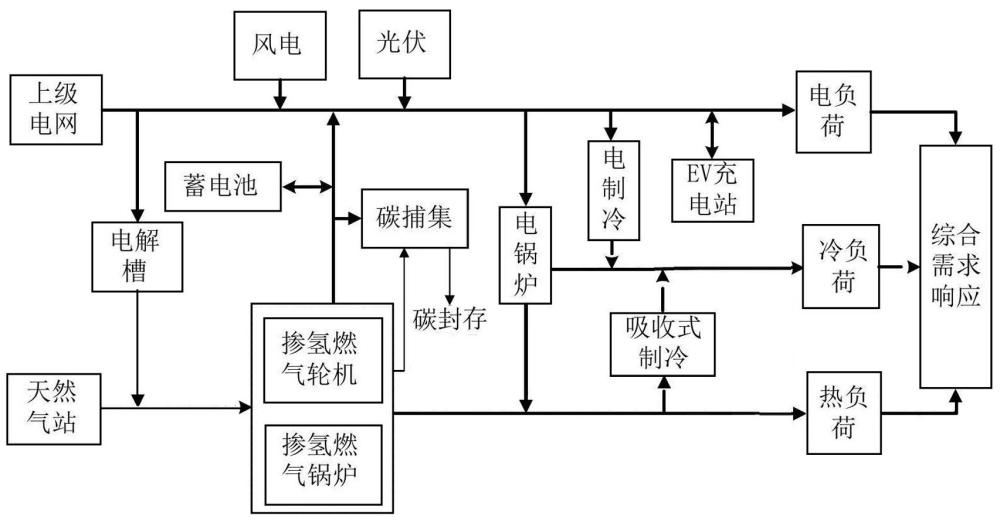
本发明属于综合能源系统控制,具体涉及一种行为克隆强化学习的零碳园区调度方法及系统。
背景技术:
1、综合能源系统是一种能实现高能源利用率、高清洁能源消纳率的能源系统。因此,建立零碳园区综合能源系统(integrated energy system,ies)是助力碳达峰、碳减排目标的重要措施。
2、目前已有一些国内外学者对零碳园区综合能源系统优化调度展开研究。研究大多考虑电转气(p2g) -燃气机组-碳捕集协同运行,以降低园区综合能源系统的碳排放,并消纳园区内的弃风弃光。但p2g-燃气机组-碳捕集协同运行忽略了p2g中电转氢过程,其相较于甲烷化其具有更高的能源转化率。此外现有关于园区综合能源系统降碳研究仅考虑储能侧或供能侧的柔性资源,以提高系统的风光消纳率以及低碳性,但未考虑用能侧、供能侧、储能侧多种柔性资源在园区ies的降碳潜能。
3、近年来,强化学习作为能高效快速处理序列决策问题的方法,被大量应用在具有复杂模型的综合能源系统中。对于具有复杂模型的综合能源系统,可通过历史数据进行离线训练,并对于训练好的模型进行在线优化调度。目前已有一些强化学习应用于该领域中。有研究采用深度q学习算法实现了电热综合能源系统的优化调度和孤岛微电网的负荷频率控制问题,但只能处理离散动作空间,对于复杂的综合能源系统易出现维度爆炸的问题,导致训练结果的精度下降;因此,越来越多的学者采用具有连续性决策能力的强化学习算法应用综合能源系统调度中来。有研究通过深度确定性策略梯度(ddpg)算法实现了综合能源系统的动态经济调度,但随着综合能源系统的越发复杂,具有状态-动作函数值(q函数值)过估计、策略更新不稳定、探索不充分问题的ddpg算法已然无法满足。因此,有学者采用具有双q函数和目标策略平滑的孪生延迟ddpg(简称td3)算法应用于综合能源系统低碳经济调度。然而,对于td3算法现仍存在着一些问题,其未能有效的解决训练过程中的分布偏移问题,从而导致训练的精确度、稳定性下降。
技术实现思路
1、为克服上述缺点,本发明提出了一种行为克隆强化学习的零碳园区调度方法及系统。首先,在供能侧考虑电解槽和含碳捕集的掺氢燃气轮机(hgt)和掺氢燃气锅炉(hgb)协同运行,并综合考虑多种柔性资源,含电储能、电动汽车、电/热/冷柔性负荷,充分调动园区综合能源系统的降碳潜能,提高零碳园区综合能源系统的能源转化率和低碳性;然后,为解决td3算法存在的分布偏移问题,采用行为克隆td3算法,该算法在策略更新中考虑加权行为克隆损失项,避免分布问题,且通过对状态量进行归一化处理,提高训练的稳定性;最后通过考虑行为克隆td3算法实现零碳园区综合能源系统的在线实时决策。
2、本发明通过下述技术方案来实现:一种行为克隆强化学习的零碳园区调度方法,在园区综合能源系统采用含电解槽和碳捕集的掺氢燃气机组协同运行单元,并考虑蓄电池、电动汽车有序充放电策略、冷热电综合需求响应措施,同时考虑高比例新能源发电,从而构建考虑多类型柔性资源的零碳园区综合能源系统调度模型; 采用行为克隆td3强化学习算法对零碳园区综合能源系统调度模型进行离线训练和在线优化,所述行为克隆td3强化学习算法是在td3算法的策略更新基础上,加入一个加权行为克隆损失项:
3、<mstyle displaystyle="true" mathcolor="#000000"><mstyle displaystyle="true" mathcolor="#000000"><mi>π</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>=</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><munder><mrow><mi>arg</mi><mi>max</mi></mrow><mi>π</mi></munder></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi></mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><munder><mi></mi><mrow><mi>(</mi><msup><mi>s</mi><mi>t</mi></msup><mi>,</mi><msup><mi>a</mi><mi>t</mi></msup><mi>)</mi><mi>∼</mi><mi>d</mi></mrow></munder></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi></mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>[</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>λ</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>q</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mo>(</mo><mrow><msup><mi>s</mi><mi>t</mi></msup><mi>,</mi><mi>π</mi><mrow><mo>(</mo><msup><mi>s</mi><mi>t</mi></msup><mo>)</mo></mrow></mrow><mo>)</mo></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>−</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mo>(</mo><mrow><mi>π</mi><mrow><mo>(</mo><msup><mi>s</mi><mi>t</mi></msup><mo>)</mo></mrow><mi>−</mi><msup><mi>a</mi><mi>t</mi></msup></mrow><mo>)</mo></mstyle><mstyle displaystyle="true" mathcolor="#000000"><msup><mrow /><mn>2</mn></msup></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>]</mi></mstyle></mstyle>;
4、其中,为策略,表示期望,为经验池,为在状态量下的智能体的策略,为超参数,、分别为时段状态量和动作量,为q函数神经网络在状态动作对下的q值。
5、进一步优选,行为克隆td3强化学习算法更新流程如下:
6、步骤1.初始化两个q函数神经网络参数、;两个目标q函数神经网络参数、;策略神经网络参数;目标策略神经网络参数;
7、步骤2.从状态空间初始化状态量,令时段t=0,训练次数k=0;
8、步骤3.由策略噪声采样动作量;
9、步骤4.通过给出的动作量传入环境中更新状态量和奖励值,并将得到的存储到经验池中;分别为时段状态量,为t时段奖励值;
10、步骤5.若经验样本量小于设定最大容量,则转至步骤3,否则从经验池中随机采样;
11、步骤6.将状态量输入策略神经网络得到时段动作量;
12、步骤7.对状态量进行归一化处理得到,分别为归一化后的时段状态量和时段状态量;
13、步骤8.输入至智能体进行网络参数更新,更新两个q函数神经网络参数、,再更新两个目标q函数神经网络参数、和策略神经网络参数、目标策略神经网络;
14、步骤9.若还未到达末时间断面,则进入下个时间断面,令t=t+1,转至步骤3;
15、步骤10.若已训练至最大训练次数k,则训练终止,否则回到步骤2,进入下一轮训练。
16、进一步优选,对状态量进行归一化处理的方式如下:
17、;
18、式中:为归一化后的状态量;为原始状态量;、状态数据集中的均值和标准差;为归一化常数。
19、进一步优选,两个q函数神经网络参数、通过最小化贝尔曼残差方式更新:
20、<mstyle displaystyle="true" mathcolor="#000000"><msub><mi>j</mi><mi>q</mi></msub><mi>(</mi><msub><mi>ω</mi><mi>i</mi></msub><msub><mi>)</mi><mrow><mi>i</mi><mi>∈</mi><mrow><mo>{</mo><mrow><mn>1</mn><mi>,</mi><mn>2</mn></mrow><mo>}</mo></mrow></mrow></msub><mi>=</mi><msub><mi></mi><mrow><mi>(</mi><msubsup><mi>s</mi><mi>*</mi><mi>t</mi></msubsup><mi>,</mi><msup><mi>a</mi><mi>t</mi></msup><mi>,</mi><msubsup><mi>s</mi><mi>*</mi><mrow><mi>t</mi><mo>+</mo><mn>1</mn></mrow></msubsup><mi>)~</mi><mi>d</mi><mi>,</mi><msup><mi>a</mi><mrow><mi>t</mi><mo>+</mo><mn>1</mn></mrow></msup><mi>~</mi><msub><mi>π</mi><mi>θ</mi></msub></mrow></msub><mrow><mo>[</mo><mrow><mfrac><mn>1</mn><mn>2</mn></mfrac><mi>(</mi><msubsup><mi>q</mi><mi>lb</mi><mi>i</mi></msubsup><mi>(</mi><msubsup><mi>s</mi><mi>*</mi><mi>t</mi></msubsup><mi>,</mi><msup><mi>a</mi><mi>t</mi></msup><mi>)</mi><mi>−</mi><mi>r</mi><mi>(</mi><msubsup><mi>s</mi><mi>*</mi><mi>t</mi></msubsup><mi>,</mi><msup><mi>a</mi><mi>t</mi></msup><mi>))</mi><mi>−</mi><mi>γ</mi><mrow><mo>(</mo><mrow><mstyle displaystyle="true" mathcolor="#000000"><mi>m</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>i</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>n</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mo>(</mo><mstyle displaystyle="true" mathcolor="#000000"><mstyle displaystyle="true" mathcolor="#000000"><mover accent="true"><mi>q</mi><mo>⌣</mo></mover></mstyle><mstyle displaystyle="true" mathcolor="#000000"><munderover><mi /><mrow><mstyle displaystyle="true" mathcolor="#000000"><mi>l</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>b</mi></mstyle></mrow><mstyle displaystyle="true" mathcolor="#000000"><mn>1</mn></mstyle></munderover></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mo>(</mo><mstyle displaystyle="true" mathcolor="#000000"><mstyle displaystyle="true" mathcolor="#000000"><mi>s</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><munderover><mi /><mi>*</mi><mrow><mi>t</mi><mi>+1</mi></mrow></munderover></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>,</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>a</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><msup><mrow /><mrow><mstyle displaystyle="true" mathcolor="#000000"><mi>t</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>+</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>1</mi></mstyle></mrow></msup></mstyle></mstyle><mo>)</mo></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>,</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mover accent="true"><mi>q</mi><mo>⌣</mo></mover></mstyle><mstyle displaystyle="true" mathcolor="#000000"><munderover><mi /><mrow><mstyle displaystyle="true" mathcolor="#000000"><mi>l</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>b</mi></mstyle></mrow><mstyle displaystyle="true" mathcolor="#000000"><mn>2</mn></mstyle></munderover></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mo>(</mo><mstyle displaystyle="true" mathcolor="#000000"><mstyle displaystyle="true" mathcolor="#000000"><mi>s</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><munderover><mi /><mi>*</mi><mrow><mi>t</mi><mi>+1</mi></mrow></munderover></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>,</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>a</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><msup><mrow /><mrow><mstyle displaystyle="true" mathcolor="#000000"><mi>t</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>+</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>1</mi></mstyle></mrow></msup></mstyle></mstyle><mo>)</mo></mstyle></mstyle><mo>)</mo></mstyle><mstyle displaystyle="true" mathcolor="#000000"><msup><mrow /><mn>2</mn></msup></mstyle></mrow><mo>)</mo></mrow></mrow><mo>]</mo></mrow></mstyle>;
21、式中:为第i个q函数神经网络参数,表示期望,和分别为第1目标q函数神经网络和第2目标q函数神经网络估计的q值,为第i个q函数神经网络估计的q值:为策略神经网络参数下得到的策略,为状态动作对下的奖励值。
22、进一步优选,第i个目标q函数神经网络参数通过下式更新:
23、;
24、其中为软更新系数。
25、进一步优选,通过梯度下降法最小化函数实现策略神经网络参数的更新:
26、<mstyle displaystyle="true" mathcolor="#000000"><mstyle displaystyle="true" mathcolor="#000000"><mi>j</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><msub><mrow /><mi>π</mi></msub></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>(</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>θ</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>)</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>=</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><munder><mi></mi><mrow><mi>(</mi><msubsup><mi>s</mi><mi>*</mi><mi>t</mi></msubsup><mi>,</mi><msubsup><mi>a</mi><mi>*</mi><mi>t</mi></msubsup><mi>)</mi><mi>∼</mi><mi>d</mi></mrow></munder></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi></mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>[</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>λ</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>q</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mo>(</mo><mrow><msubsup><mi>s</mi><mi>*</mi><mi>t</mi></msubsup><mi>,</mi><msub><mi>π</mi><mi>θ</mi></msub><mrow><mo>(</mo><msubsup><mi>s</mi><mi>*</mi><mi>t</mi></msubsup><mo>)</mo></mrow></mrow><mo>)</mo></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>−</mi></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mo>(</mo><mrow><msub><mi>π</mi><mi>θ</mi></msub><mrow><mo>(</mo><msubsup><mi>s</mi><mi>*</mi><mi>t</mi></msubsup><mo>)</mo></mrow><mi>−</mi><msup><mi>a</mi><mi>t</mi></msup></mrow><mo>)</mo></mstyle><mstyle displaystyle="true" mathcolor="#000000"><msup><mrow /><mn>2</mn></msup></mstyle><mstyle displaystyle="true" mathcolor="#000000"><mi>]</mi></mstyle></mstyle>;
27、其中,表示智能体寻找一个策略神经网络参数下的最优策略,为q函数神经网络在状态动作对下的q值;
28、目标策略神经网络参数更新方式如下:
29、。
30、进一步优选,采用行为克隆td3强化学习算法对零碳园区综合能源系统调度模型进行离线训练和在线优化的流程为:
31、将历史数据集输入强化学习环境中,初始化强化学习各网络参数;
32、进行离线调度训练,从零碳园区综合能源系统调度模型获取此时段的状态量,并进行归一化处理;
33、将归一化后的状态量输入智能体中;
34、智能体根据所输入的状态给出动作量;
35、零碳园区综合能源系统调度模型根据动作量,更新下一时段的状态;
36、当达到设定的训练次数,保存训练好的零碳园区综合能源系统调度模型;
37、将实时数据输入训练好的零碳园区综合能源系统调度模型中,在线调度中通过预测系统预测t时段最新预测信息和此时各机组出力构成状态量,把状态量输入训练好的零碳园区综合能源系统调度模型当中,此时零碳园区综合能源系统调度模型会根据输入的状态量,最大化奖励得出最优调度方案。
38、进一步优选,所述含电解槽和碳捕集的掺氢燃气机组协同运行单元的能耗和出力数学模型如下:
39、;
40、式中:、分别为掺氢燃气轮机、掺氢燃气锅炉时段总能耗;、分别为掺氢燃气轮机、掺氢燃气锅炉时段消耗的天然气;、分别为掺氢燃气轮机、掺氢燃气锅炉时段消耗的氢气;为碳捕集时段总能耗;、分别为碳捕集时段的运行能耗和固定能耗;、分别为掺氢燃气轮机时段的电出力和热出力; 为掺氢燃气锅炉时段的热出力;为电解槽时段的电能耗;为电解槽时段提供的氢能;为风电和光伏时段提供给电解槽的电功率;为电解槽的制氢效率;、 分别为掺氢燃气轮机的电效率与热效率;为掺氢燃气锅炉的热效率。
41、进一步优选,含电解槽和碳捕集的掺氢燃气机组协同运行单元的出力策略数学模型如下:
42、;
43、式中:为风电和光伏时段提供的碳捕集能耗;为掺氢燃气轮机时段提供的碳捕集能耗;为碳捕集时段处理的co2总量;为碳捕集处理co2单位能耗;为时段风电上网功率;为时段风光总出力; 为时段风电出力;为时段光伏出力;为时段掺氢燃气轮机上网功率。
44、进一步优选,碳捕集捕获co2的量的数学模型如下:
45、;
46、式中:、分别为掺氢燃气轮机、掺氢燃气锅炉时段的碳排放;为碳捕集的碳效率;为碳捕集时段的烟气分流比;、为分别掺氢燃气轮机、掺氢燃气锅炉的碳排放系数。
47、进一步优选,含电解槽和碳捕集的掺氢燃气机组协同运行单元掺氢环节的数学模型如下:
48、;
49、式中:、分别为时段掺氢前后天然气消耗量;为时段掺氢消耗的氢功率;为时段掺氢比例。
50、本发明还提供一种行为克隆强化学习的零碳园区调度系统,包括至少一个处理器;以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的计算机程序,所述计算机程序被所述至少一个处理器执行,以使所述至少一个处理器能够执行上述的行为克隆强化学习的零碳园区调度方法。
51、本发明具有以下优点:
52、含电解槽和含碳捕集的掺氢燃气轮机(hgt)和掺氢燃气锅炉(hgb)协同运行单元大幅度提高园区综合能源系统对于高比例新能源的消纳能力,并极大的减少了园区综合能源系统消耗化石能源设备的碳排放,并且使园区综合能源系统具有更优越的经济性。
53、考虑蓄电池、电动汽车和综合需求响应等多类型柔性资源的园区综合能源系统能极大的提升柔性调节能力,充分挖掘出园区综合能源系统用能侧、供能侧、储能侧的柔性资源减排潜力,为园区低碳转型提供实施路径。
54、本发明提出的行为克隆td3强化学习算法可有效提升零碳园区综合能源系统的低碳经济性。相相较于其他群智能算法和td3算法,行为克隆td3强化学习算法能有效应对源荷不确定给调度带来的额外成本和碳排放,且对于给出的调度方案更快速、精确。
- 还没有人留言评论。精彩留言会获得点赞!