一种基于对比学习的可解释个性化推荐方法
本发明涉及人工智能领域,具体涉及一种基于对比学习的可解释个性化推荐方法。
背景技术:
1、针对传统的购物场景,已经有一些成熟的推荐算法在被广泛应用,目前绝大多数的学者都在关注基于深度学习的个性化推荐方法,如基于深度协同过滤模型、基于时序网络的推荐模型和基于图神经网络的推荐模型等,但由于深度学习具有黑盒模型端到端的特性,推荐的结果很难让用户理解并信任。因此,如何对基于深度学习的推荐模型提供解释是当前推荐研究遇到的难题。
2、cn2022111841575公开了个性化联邦学习的训练效率与个性化效果量化评估方法,包括以下步骤:s1、创建一个non-iid的跨域数据集,作为评测数据集;s2、选择合适的模型,作为个性化联邦学习的初始全局模型;s3、进行联邦学习的全局神经网络训练,聚合出一个收敛的全局神经网络模型;s4、各个客户端利用本地的数据集对下发的全局模型进行优化,收敛并形成个性化的本地神经网络模型;本发明充分考虑了跨域异质的场景,实现了模型的个性化功能。
3、cn202010950990.0公开了一种用于强化回复个性化表达的开放域对话模型与方法,包括一对拥有相同编码器-解码器骨干的子网络,由cdnet和pdnet两个子网络构成,两个子网络通过多任务学习的方式交替训练,在交替训练的过程中更新编码器-解码器骨干的参数,从而让整个模型获得两个子网络在训练过程中学习到的个性化选择与个性化嵌入的能力,模型通过多任务训练的方式交替训练cdnet和pdnet,从而学习到这两个子网络的能力,生成个性化信息更加充分的回复。
4、最新的一系列研究表明带文本信息的推荐旨在利用文本信息可用于提高推荐系统的有效性和可解释性。通过整合文本数据并采用自然语言处理和深度学习等最先进的技术,研究人员努力为用户提供更精确、更有意义的推荐。文本信息可以分为两个主要领域:第一个领域包含与产品相关的规范信息。产品规格是描述给定产品属性的文本描述,包括其标题和详细规格。基于神经自然语言处理的模型能够对产品规格进行编码,并将其无缝地整合到推荐框架中,从而更好地学习产品嵌入。第二类是用户评论信息。然而,由于研究限制或用户隐私问题,用户评论的可用性可能有限或无法访问。相反,产品标题信息更容易获得。本发明使用从产品标题中提取的关键字来生成有效捕获用户意图的关键字序列。
5、对比学习(cl)是一种通过对不同样本的比较学习来构建有意义表征的有效方法。cl的基本原则是鼓励锚点表示和“正”样本之间的密切关系,同时加强锚点表示和“负”样本之间的距离。近年来,越来越多的学者采用cl来解决推荐任务。尽管取得了显著的成就,但上述基于cl的方法主要集中于从序列会话中获取自监督信号。然而,这些序列中包含的信息是固有的约束,导致派生的自监督信号不够鲁棒,无法捕获信息嵌入。在提出的方法中,本发明从不同的数据源中提取监管信号,包括长期和短期用户行为,以及产品关键字序列。
技术实现思路
1、本发明的目的在于,提出一种基于对比学习的可解释个性化推荐方法,可以针对所有场景的个性化推荐,如旅游推荐,如购物推荐,如服务前几年推荐等等。
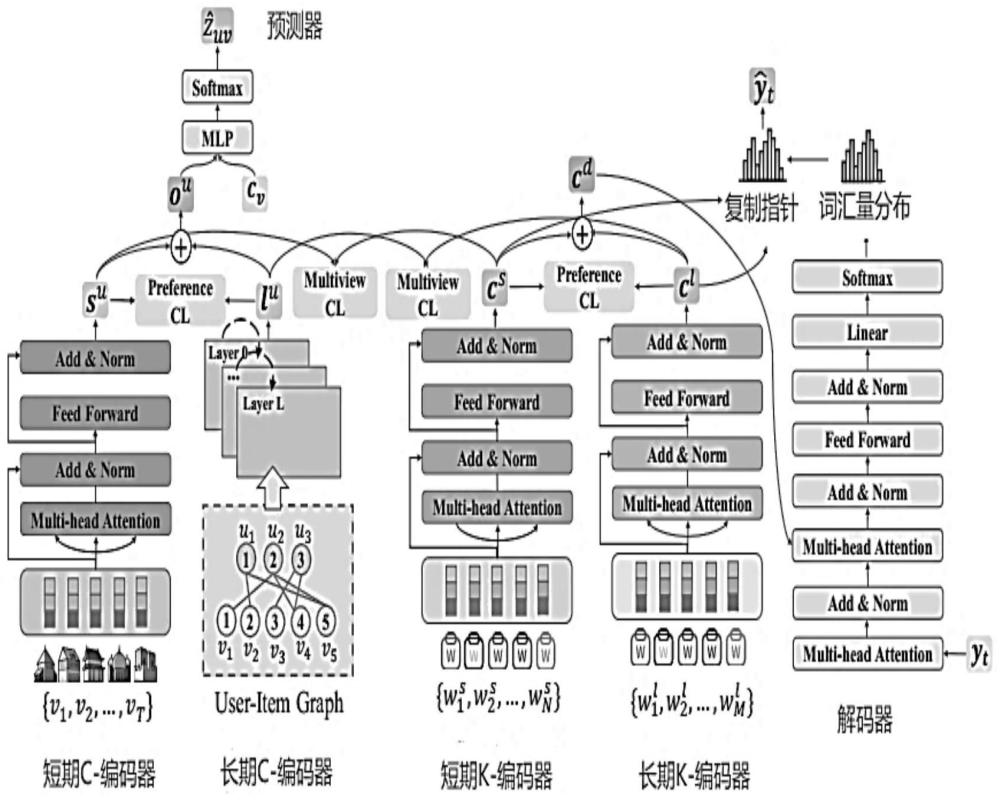
2、实现本发明目的的技术解决方案为:一种基于对比学习的可解释个性化推荐方法,包括如下步骤:框架如图1所示。
3、步骤1)对于个性化推荐任务,本发明设计了三个核心模块:short-term c-encoder、long-term c-encoder和predictor。short-term c-encoder和long-term c-encoder短期和长期和预测模块;从短期和长期用户点击行为中学习用户表示。随后,预测器根据融合的表示生成推荐结果;使用transformer encoder组件来学习用户短期行为的顺序表示;
4、具体来说,对于短期用户行为序列,即当前会话su={v1,v2,···,vt},将序列中的元素编码为序列嵌入{v1,v2,···,vt}用嵌入矩阵;为了整合被点击产品的顺序信息,采用位置嵌入操作来更新产品嵌入:e=[v1+p1,v2+p2,···,vt+pt],pt为旅行产品vt的位置嵌入;
5、transformer encoder组件包括一个多头自关注层,其中transformer encoder用于计算所有产品的关注权重;该组件由多个头部组成,在每个头部内,使用点积来计算乘积之间的关系;
6、
7、其中q、k和v分别代表查询、键和值,表示防止点积变得过大的比例因子。
8、对于每个head headi,查询、键和值进行h次线性投影,然后将结果串联如下:
9、
10、multiattn(q,k,v)=concate(head1,··,headh)wo
11、其中,和wo代表可学习的参数。最后,应用前馈层(记为feedforward(·))和整流线性单元(relu)激活函数来转换上述嵌入,从而得到短期用户偏好的表示。
12、su=wurelu(wsmultiattn(q,k,v)+bs)+bu
13、1)使用图神经网络来模拟用户的长期行为,给定短期用户点击行为序列lu,构造无向图g={o,ε},o和ε分别表示节点集和边集;图中包含两种节点:用户(u)和产品(v),边反映了用户与产品之间的相互关系;
14、在异构用户-产品图中,采用gat,通过引入注意机制来学习用户与产品之间的高阶关系;计算单个gat层中特定节点嵌入的一般公式如下:
15、
16、其中,表示节点i在第l+1层的嵌入,该嵌入是将其相邻节点n(i)的嵌入聚合计算得出的,以关注系数aij加权;aij决定了第l层中每个相邻节点j的重要性:
17、
18、通过gat的应用,能够推导出包含高阶信息的用户和产品的最终表示;从长期行为中习得的用户嵌入有效地捕获了相对持久和稳定的长期用户偏好;将导出的长期用户偏好表示为lu。
19、利用门融合操作来整合在线用户的长期和短期行为偏好;门向量fu表示长期和短期偏好的重要程度;
20、fu=sigmoid(wmlu+wnsu+b)
21、其中,wm、wn、b分别为可学习参数;lu表示长期用户偏好,su表示短期用户偏好,用户偏好的最终表示计算如下:
22、ou=fu⊙lu+(1-fu)⊙su
23、其中⊙是逐元素乘法;随后,利用双线性解码运算将用户表示变换成概率矩阵,得到目标用户u购买产品v的概率:
24、
25、最后,将个性化推荐任务的损失函数定义为预测概率与真实值之间的交叉熵,如下所示:
26、
27、其中i表示旅行产品的个数,表示旅行产品v的预测概率,zuv对应于groundtruth,groundtruth对应用户u对产品v购买的标记,如果购买为1,未购买则为0。
28、(测试收集适当的目标数据的过程。在机器学习中,“ground truth”一词指的是训练集对监督学习技术的分类的准确性)的标号;
29、转入步骤2)。
30、步骤2)对于关键字生成任务,使用transformer组件,它在文本生成中也得到了广泛的应用,并且表现出了优异的性能。该部分由short-term k-encoder、long-term k-encoder、decoder和copy pointer四个部分组成;short-term和long-term k-encoder利用自注意机制捕获短期和长期用户行为中的长期依赖信息;
31、给定提取的关键字序列从当前会话中点击的产品标题中提取关键字序列,使用transformer encoder对关键字序列进行编码。变压器编码器包括多头自关注层和前馈层两个模块:
32、ds=multiattn(ws,ws,ws)
33、cs=feedforward(ds)
34、其中表示通过word2vec获得的关键字嵌入序列。此外,在每一层之后使用残差连接和层范数。
35、采用与short-term k-encoder相同的方法对long-term keyword得到向量cl。
36、decoder与transformer decoder共享架构,由两个多头自注意层和一个前馈层组成:
37、md=maskedmultiattn(od,od,od)
38、xd=multiattn(cd,cd,cd)
39、zd=feedforward(xd)
40、具体来说,利用多头自注意来计算输出序列od中关键字的注意权重,其中每个关键字受到其前面位置以及其自身位置的影响;随后利用多头自注意计算编码器表示cd和解码器表示md之间的注意权重,其中cd=cs||cl,每个解码器位置受所有编码器位置的影响。接下来,利用带有relu激活函数的前馈层将xd转换为固定维度。此外,在每一层加入了剩余连接和层规范化。从解码器组件获得输出zd后,利用全连接网络计算单词概率,从而便于生成关键字:
41、pvocab(w)=sofmax(zdwz+bz)
42、其中pvocab(w)为所有关键词的概率分布,wz和bz为可学习参数。
43、设计了一个复制网络,从短期和长期关键词序列中复制关键词,以增强关键词的生成:
44、
45、
46、其中
47、在时间步t上,λt决定关键字是从关键字分布pvocab中生成的,还是从短期和长期关键字序列中复制的。这将产生一个新的关键字概率分布:
48、
49、λt=softmax(wt[zd,yt-1,cd]+bt)
50、对于关键词生成任务,采用负对数似然作为损失函数:
51、
52、式中,nt表示关键字长度y,ns表示关键字词汇表大小。
53、随后,解码器将信息转换成字的概率分布。此外,复制指针从原始关键字序列中复制单词。转入步骤3)。
54、步骤3)本发明不仅推荐产品,还生成关键字,从而增强了推荐结果的可解释性。
55、具体来说,本发明采用了一个多任务学习框架,其中损失函数可以表示为:
56、
57、提出了一种多视图cl方法(多视图cl(对比学习)在推荐系统中缓解了数据稀疏和流行度偏差问题。对比学习天然适用于对多行为和多视图用户表示之间的粗粒度共性和细粒度差异进行建模),根据不同类型数据之间的相关性,将多种类型的数据组合在一起以改进数据表示。
58、对于短期用户偏好,有两种类型的表示,分别表示为向量su和cs,它们从显式和隐式两个角度描述了同一用户的旅行(购物或服务,如儿童的辅导推荐等)等意图。短期用户偏好跟数值无关,对比学习的思想:同一用户的2种表征向量更加相似,不同的用户向量差异更大。这些表示被认为是语义上接近的。因此,基于这两种类型的表示,将和视为正例,同时将来自同一批不同用户的表示视为负例。用户的多视图cl损失定义为:
59、
60、其中sim(·)为嵌入之间的余弦相似度,τ为参数。
61、同理,下式定义了长期用户偏好的多视图cl损失:
62、
63、偏好cl旨在强调短期和长期用户偏好之间的关系。同一用户的长期和短期偏好的表示应该比其他用户的表示更接近。对于个性化推荐任务,给定一个随机抽样的用户i,认为相同的用户为正对,同时考虑作为负对。用户偏好的偏好cl损失定义如下:
64、
65、对于关键字生成,考虑最小批用户令表示用户ui的嵌入作为cl中的正对。作为负对。对比目标定义如下:
66、
67、根据经典的基于cl的推荐方法,将总损失l定义为:
68、
69、其中λ1和λ2是超参数。
70、该方法同时实现个性化产品推荐和解释关键词生成任务,在这两个任务中整合了长期和短期用户偏好。此外,为了更好地学习用户和产品表征,本发明设计了两种对比学习任务。偏好对比学习旨在弥合用户长期偏好和短期偏好之间的差距。多视图对比学习侧重于对被点击产品及其关键字之间的粗粒度共性进行建模。最后,通过多任务学习进行联合建模,实现个性化产品(如旅游)推荐任务和基于关键词生成的文本解释任务。本发明以电商平台用户点击流数据为驱动,以transformer和图神经网络为模型,基于多任务学习和对比学习的框架构建可解释个性化推荐模型,能够有助于识别用户的兴趣偏好,并为用户提供个性化推荐和推荐结果文本解释服务。
71、与传统的旅游推荐方法不同,本发明将关键词信息整合到推荐系统中,并结合关键词生成任务对产品推荐进行建模。同时,该模型在推荐产品和生成关键词的过程中考虑了用户的长期和短期用户偏好,主要由七个部分组成:short-term c-encoder、long-termc-encoder、predictor、short-term k-encoder、long-term k-encoder、decoder和copypointer。本发明提出了两种类型的对比学习任务,以获得更好的用户和产品表征。具体来说,对于长期用户行为和短期用户行为(关键词序列),引入偏好cl任务作为辅助损失,对于长期(短期)用户行为和关键字序列,引入多视图cl任务作为辅助损失。将长期和短期用户行为融合用于产品推荐,将长期和短期用户行为融合用于关键词生成。
72、有益效果:本发明与现有技术相比,其显著优点在于:
73、(1)本发明集成了旅游推荐和关键字生成任务,从而增强了结果推荐的可解释性。
74、(2)本发明在完成个性化推荐和关键词生成这两项任务时,分别从用户的历史会话和当前会话中捕获稳定的长期用户偏好和临时的短期用户偏好。
75、(3)本发明为了进一步增强模型学习的用户和产品表征,设计了两种对比学习任务。
- 还没有人留言评论。精彩留言会获得点赞!