融合嵌入签名的异构实体匹配方法及系统
本发明涉及知识融合领域,尤其涉及一种融合嵌入签名的异构实体匹配方法及系统。
背景技术:
1、在当今信息爆炸的时代,大数据和数据科学的兴起使得各行各业都面临着处理大规模数据的挑战。在这个背景下,实体匹配成为了一项关键任务,特别是在面对异构数据源时。异构实体匹配指的是识别来自一个或多个数据源的数据记录,这些记录的形式不一且指向相同的现实世界实体。这个任务在数据整合、数据清洗和数据分析中起着至关重要的作用,因为当数据能够被链接到其他数据以创建一个统一的数据存储库时,其价值将会呈指数级增长。
2、分组是一种将数据集分成子集的技术,以减少需要进行匹配的记录对的数量。它通过将记录分组到具有一定属性相似性的块中来实现。然而,在大规模数据集上进行分组面临着许多挑战,其中之一是处理数据的异构性。不同数据源之间可能存在不一致的数据表示和格式,这增加了分组的难度。
3、传统的分组方法通常基于手工设计的分组键(blocking keys),例如基于字符串匹配或基于规则的方法。这些方法通常需要大量的人工干预和领域专业知识,而且在处理异构数据时可能会遇到问题。
4、与此同时,异构数据源的特点也增加了实体匹配的复杂性。不同数据源之间存在着数据格式、语义、质量等方面的差异,这导致了实体匹配过程中需要处理各种类型的数据不一致性。传统的实体匹配方法不能很好的处理数据属性之间的不一致性,从而得到的效果不够准确。
技术实现思路
1、针对现有技术存在的问题,本发明提供一种准确性更高的融合嵌入签名的异构实体匹配方法及系统。
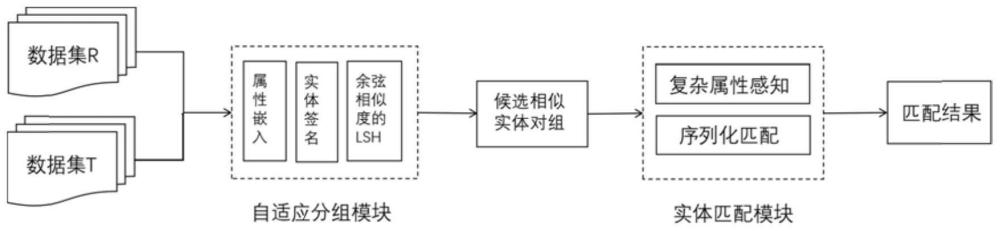
2、为了实现上述发明目的,本发明提供了一种融合嵌入签名的异构实体匹配方法,包括以下步骤:
3、(1)获取包括若干目标实体的目标实体数据集和包括若干源实体的源实体数据集;
4、(2)对于每个目标实体和每个源实体,生成其每个属性的属性名和属性值里的所有词的词嵌入,并将属于一个属性的所有词嵌入拼接作为当前属性的属性嵌入;
5、(3)对于每个目标实体和每个源实体,将属于当前实体的不同属性嵌入随机组合,得到当前实体的多个嵌入签名;
6、(4)基于嵌入签名之间的相似度计算每个源实体的与每个目标实体的相似度,选择相似度高于预设阈值的源实体和目标实体组成候选相似实体组;
7、(5)提取每个候选相似实体组中源实体和目标实体间的属性相似度矩阵;
8、(6)对每个候选相似实体组的源实体和目标实体进行序列化,采用属性相似度矩阵计算得到序列化的源实体和目标实体间的匹配结果。
9、进一步的,步骤(3)具体包括:
10、(31)对于每个目标实体和每个源实体,从所有属于当前实体的属性嵌入中随机选择若干个,得到一组属性嵌入,并选择若干次,从而得到若干组属性嵌入;
11、(32)通过预设组合函数将若干组属性嵌入进行组合,得到当前实体的若干嵌入签名。
12、进一步的,步骤(4)具体包括:
13、(41)计算每个源实体的每个嵌入签名与每个目标实体的每个嵌入签名的余弦相似度;
14、(42)从源实体的所有嵌入签名与目标实体的所有嵌入签名的余弦相似度中,选择余弦相似度最大值作为当前源实体与当前目标实体的相似度;
15、(43)对于每个源实体,使用局部敏感哈希检索与之相似度高于预设阈值的目标实体;
16、(44)将检索结果取并集并进行去重,得到最终的候选相似实体组。
17、进一步的,步骤(5)具体包括:
18、(51)对于每一候选相似实体组,获取其源实体和目标实体中每个属性的属性嵌入;
19、(52)根据训练得到的自注意力矩阵,按照下式计算源实体中每个属性嵌入的自注意力权重:
20、
21、
22、式中,表示源实体第i个属性嵌入的自注意力分数,表示源实体第i个属性嵌入,ns为源实体的属性个数,w为训练好的自注意力矩阵,表示源实体第i个属性嵌入的自注意力权重,m2v()表示归一化函数;
23、(53)根据训练得到的交互注意力矩阵,按照下式计算源实体中每个属性嵌入和目标实体中每个属性嵌入的交互注意力权重,并根据交互注意力权重计算得到源实体中每个属性嵌入和目标实体中每个属性嵌入的交互表示矩阵;
24、
25、
26、式中,βi→j表示源实体中第i个属性嵌入和目标实体中第j个属性嵌入的交互注意力权重,wi→j为训练得到的交互注意力矩阵,nt为目标实体的属性个数,为和的交互表示矩阵;
27、(54)获取交互表示向量在每个词上的交互表示向量,并按照下式计算源实体每个属性嵌入和目标实体每个属性嵌入的词级相似度;
28、
29、
30、式中,sij(x)表示和在词x上的相似度,表示中对应词x的词嵌入,表示在词x上的交互表示向量,表示哈达玛积运算,highwaynet()表示highway网络,表示中词的个数,;
31、(55)根据自注意力权重、源实体和目标实体的相似度,按照下式计算得到源实体和目标实体的属性相似度矩阵;
32、
33、
34、i=1,…,ns,j=1,…,nt
35、式中,表示中间变量,表示中词x的自注意力权重,rij为属性相似度矩阵r的第i第j列的元素值,表示源实体第i个属性和目标实体第j个属性的相似度。
36、进一步的,步骤(6)具体包括:
37、(61)将每个候选相似实体组中的源实体和目标实体分别进行序列化,得到源实体序列和目标实体序列,并将源实体序列和目标实体序列拼接,得到候选相似实体组序列;
38、(62)将候选相似实体组序列输入预训练模型bert中,得到嵌入向量e;
39、(63)将候选相似实体组的嵌入向量e,输入线性层进行线性变换,得到变换向量:
40、q=linear(e,r,b)=e×r+b
41、式中,q是变换向量,r是属性相似度矩阵,b是偏置向量,linear()表示线性层的线性变化;
42、(64)将变换向量通过softmax函数得到匹配结果,0代表不匹配,1代表匹配。
43、本发明还提供了一种融合嵌入签名的异构实体匹配系统,包括:
44、数据集获取模块,用于获取包括若干目标实体的目标实体数据集和包括若干源实体的源实体数据集;
45、属性嵌入生成模块,用于对于每个目标实体和每个源实体,生成其每个属性的属性名和属性值里的所有词的词嵌入,并将属于一个属性的所有词嵌入拼接作为当前属性的属性嵌入;
46、实体签名生成模块,用于对于每个目标实体和每个源实体,将属于当前实体的不同属性嵌入随机组合,得到当前实体的多个嵌入签名;
47、相似度计算模块,用于基于嵌入签名之间的相似度计算每个源实体的与每个目标实体的相似度,选择相似度高于预设阈值的源实体和目标实体组成候选相似实体组;
48、复杂属性感知模块,用于提取每个候选相似实体组中源实体和目标实体间的属性相似度矩阵;
49、序列化匹配模块,用于对每个候选相似实体组的源实体和目标实体进行序列化,采用属性相似度矩阵计算得到序列化的源实体和目标实体间的匹配结果。
50、进一步的,所述实体签名生成模块具体包括:
51、属性嵌入选择单元,用于对于每个目标实体和每个源实体,从所有属于当前实体的属性嵌入中随机选择若干个,得到一组属性嵌入,并选择若干次,从而得到若干组属性嵌入;
52、嵌入签名生成单元,用于通过预设组合函数将若干组属性嵌入进行组合,得到当前实体的若干嵌入签名。
53、进一步的,所述相似度计算模块具体包括:
54、余弦相似度计算单元,用于计算每个源实体的每个嵌入签名与每个目标实体的每个嵌入签名的余弦相似度;
55、相似度确认单元,用于从源实体的所有嵌入签名与目标实体的所有嵌入签名的余弦相似度中,选择余弦相似度最大值作为当前源实体与当前目标实体的相似度;
56、检索单元,用于对于每个源实体,使用局部敏感哈希检索与之相似度高于预设阈值的目标实体;
57、候选相似实体组生成单元,用于将检索结果取并集并进行去重,得到最终的候选相似实体组。
58、进一步的,所述复杂属性感知模块具体包括:
59、数据获取单元,用于对于每一候选相似实体组,获取其源实体和目标实体中每个属性的属性嵌入;
60、自注意力单元,用于根据训练得到的自注意力矩阵,按照下式计算源实体中每个属性嵌入的自注意力权重:
61、
62、
63、式中,表示源实体第i个属性嵌入的自注意力分数,表示源实体第i个属性嵌入,ns为源实体的属性个数,w为训练好的自注意力矩阵,表示源实体第i个属性嵌入的自注意力权重,m2v()表示归一化函数;
64、交互注意力单元,用于根据训练得到的交互注意力矩阵,按照下式计算源实体中每个属性嵌入和目标实体中每个属性嵌入的交互注意力权重,并根据交互注意力权重计算得到源实体中每个属性嵌入和目标实体中每个属性嵌入的交互表示矩阵;
65、
66、
67、式中,βi→j表示源实体中第i个属性嵌入和目标实体中第j个属性嵌入的交互注意力权重,wi→j为训练得到的交互注意力矩阵,nt为目标实体的属性个数,为和的交互表示矩阵;
68、相似度计算单元,用于获取交互表示向量在每个词上的交互表示向量,并按照下式计算源实体每个属性嵌入和目标实体每个属性嵌入的词级相似度;
69、
70、
71、式中,sij(x)表示和在词x上的相似度,表示中对应词x的词嵌入,表示在词x上的交互表示向量,表示哈达玛积运算,highwaynet()表示highway网络,表示中词的个数,;
72、属性相似度矩阵计算单元,用于根据自注意力权重、源实体和目标实体的相似度,按照下式计算得到源实体和目标实体的属性相似度矩阵;
73、
74、
75、i=1,…,ns,j=1,…,nt
76、式中,表示中间变量,表示中词x的自注意力权重,rij为属性相似度矩阵r的第i第j列的元素值,表示源实体第i个属性和目标实体第j个属性的相似度。
77、进一步的,所述序列化匹配模块具体包括:
78、序列化单元,用于将每个候选相似实体组中的源实体和目标实体分别进行序列化,得到源实体序列和目标实体序列,并将源实体序列和目标实体序列拼接,得到候选相似实体组序列;
79、嵌入生成单元,用于将候选相似实体组序列输入预训练模型bert中,得到嵌入向量e;
80、线性变化单元,用于将候选相似实体组的嵌入向量e,输入线性层进行线性变换,得到变换向量:
81、q=linear(e,r,b)=e×r+b
82、式中,q是变换向量,r是属性相似度矩阵,b是偏置向量,linear()表示线性层的线性变化;
83、匹配单元,用于将变换向量通过softmax函数得到匹配结果,0代表不匹配,1代表匹配。
84、本发明与现有技术相比,其有益效果是:
85、1、本发明提出了使用组合函数对实体的属性进行组合作为签名,然后利用签名作为分组键,可以得到实体间更全面的相似信息,接着使用相似度获得可能存在的候选实体对,大大减少了人工,并且找到了更多可能潜在的实体对;
86、2、本发明通过计算不同实体的属性相似度,将相关性纳入匹配过程中,使得异构实体更加关注相似属性的匹配程度,解决实体属性间错综的复杂关系,从而提高匹配准确性。并且将实体匹配转化为序列对分类问题,以更准确地捕捉实体之间的语义信息。通过结合属性关联和实体间的语义关联,有效的解决了异构实体匹配的问题,准确性更高。
- 还没有人留言评论。精彩留言会获得点赞!