服务器的运维监控方法、装置、设备、存储介质及产品与流程
本技术涉及人工智能,尤其涉及一种服务器的运维监控方法、装置、设备、存储介质及产品。
背景技术:
1、目前,对内网服务器的操作主要是通过部署网络安全设备例如堡垒机的方式进行,常规的堡垒机会设置一些策略或者规则库,如果技术人员操作服务器,出现高危险命令,触碰到规则库,则堡垒机会出现告警信息,对服务器管理员人员进行提示。相关技术中,一些堡垒机中内置一些人工智能模型,例如ocr(optical character recognition,光学字符识别)模型,用于识别技术人员对服务器的操作命令。由于这些模型只能识别到标注数据,未标注的数据不能识别,导致模型的泛化能力较差,最终影响服务器的运维监控预警效果。
技术实现思路
1、本技术实施例通过提供一种服务器的运维监控方法、装置、设备、存储介质及产品,旨在提高模型的泛化能力,改善服务器的运维监控预警效果。
2、本技术实施例提供了一种服务器的运维监控方法,所述服务器的运维监控方法,包括:
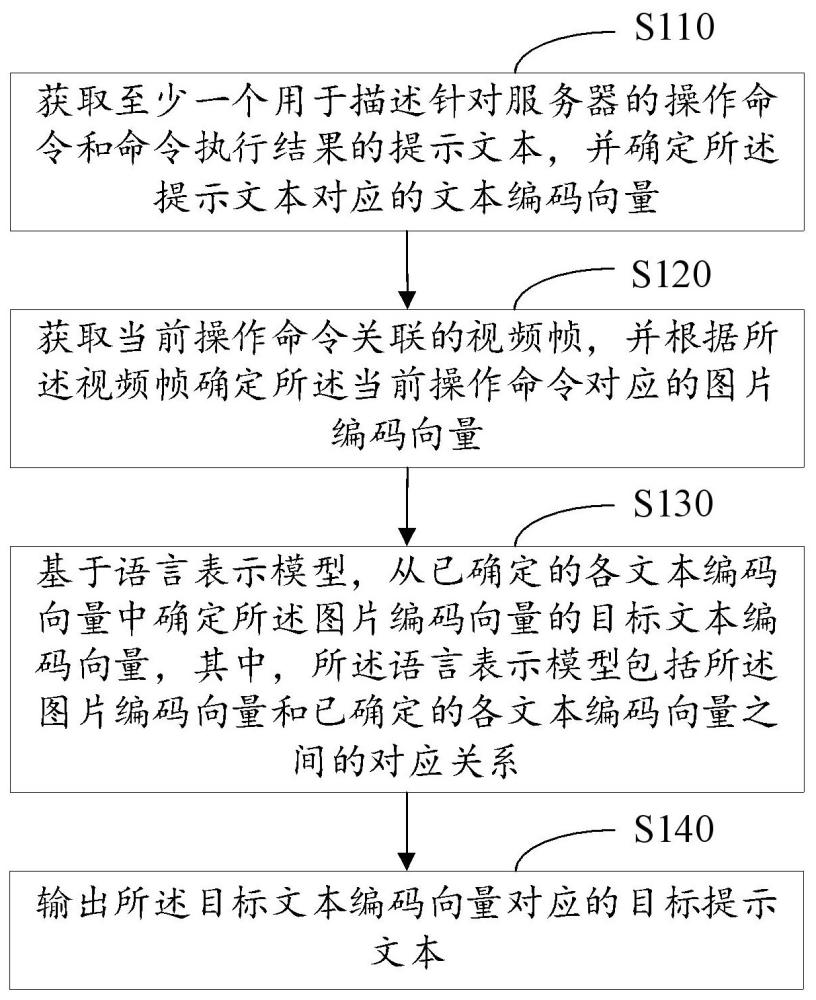
3、获取至少一个用于描述针对服务器的操作命令和命令执行结果的提示文本,并确定所述提示文本对应的文本编码向量;
4、获取当前操作命令关联的视频帧,并根据所述视频帧确定所述当前操作命令对应的图片编码向量;
5、基于语言表示模型,从已确定的各文本编码向量中确定所述图片编码向量的目标文本编码向量,其中,所述语言表示模型包括所述图片编码向量和已确定的各文本编码向量之间的对应关系;
6、输出所述目标文本编码向量对应的目标提示文本。
7、可选地,所述服务器的运维监控方法,还包括:
8、获取服务器的历史录制视频,将所述历史录制视频划分为多个视频帧,并为每个视频帧标注对应的提示文本,所述提示文本用于描述用户对服务器的操作命令和命令执行结果;
9、对每个所述视频帧进行编码,得到每个所述视频帧对应的图片编码向量,以及,对每个所述视频帧标注的提示文本中的操作命令和命令执行结果进行编码,得到每个所述视频帧标注的提示文本的文本编码向量;
10、根据每个视频帧对应的图片编码向量和每个所述视频帧标注的提示文本对应的文本编码向量,得到多个样本向量对;
11、采用所述样本向量对进行初始语言表示模型的损失函数的训练,得到所述语言表示模型。
12、可选地,所述对每个所述视频帧标注的提示文本中的操作命令和命令执行结果进行编码,得到每个所述视频帧标注的提示文本的文本编码向量的步骤包括:
13、对每个所述视频帧标注的提示文本中的操作命令和命令执行结果进行拼接,得到拼接文本;
14、对所述拼接文本进行编码,得到每个所述视频帧标注的提示文本的文本编码向量。
15、可选地,所述样本向量对包括正样本向量对和负样本向量对,所述采用所述样本向量对进行初始语言表示模型的损失函数的训练,得到所述语言表示模型的步骤包括:
16、确定每个负样本向量对中的图片编码向量和文本编码向量之间的相似度;
17、保留任意两个负样本向量中相似度最大的负样本向量对;
18、对所述相似度最大的负样本向量对进行随机遮挡,得到遮挡后的样本向量对;
19、采用所述遮挡后的样本向量对进行初始语言表示模型的损失函数的训练,得到所述语言表示模型。
20、可选地,所述采用所述样本向量对进行初始语言表示模型的损失函数的训练,得到所述语言表示模型的步骤包括:
21、确定每个所述样本向量对中,图片编码向量和文本编码向量的交集结果和并集结果;
22、根据所述交集结果和所述并集结果,确定每个所述样本向量对中的图片编码向量和文本编码向量之间的距离;
23、根据每个所述样本向量对中的图片编码向量的维度和文本编码向量的维度,确定每个所述样本向量对所对应的维度均值;
24、根据每个所述样本向量对中的图片编码向量和文本编码向量之间的距离和所述每个所述样本向量对所对应的维度均值依据损失函数进行计算,得到损失值;
25、基于所述损失值对所述初始语言表示模型的模型参数进行优化,得到所述语言表示模型。
26、可选地,所述基于语言表示模型,从已确定的各文本编码向量中确定所述图片编码向量的目标文本编码向量的步骤包括:
27、确定所述图片编码向量对应的预测提示文本,并确定所述预测提示文本对应的文本编码向量;
28、确定所述预测提示文本对应的文本编码向量与已确定的各文本编码向量之间的余弦相似度;
29、根据所述余弦相似度最小时对应的已确定的文本编码向量,得到所述图片编码向量的目标文本向量。
30、此外,为实现上述目的,本技术还提供一种服务器的运维监控装置,包括:
31、文本编码向量确定模块,用于获取至少一个用于描述针对服务器的操作命令和命令执行结果的提示文本,并确定所述提示文本对应的文本编码向量;
32、图片编码向量确定模块,用于获取当前操作命令关联的视频帧,并根据所述视频帧确定所述当前操作命令对应的图片编码向量;
33、目标文本编码向量确定模块,用于基于语言表示模型,从已确定的各文本编码向量中确定所述图片编码向量的目标文本编码向量,其中,所述语言表示模型包括所述图片编码向量和已确定的各文本编码向量之间的对应关系;
34、目标提示文本输出模块,用于输出所述目标文本编码向量对应的目标提示文本。
35、此外,为实现上述目的,本技术还提供了一种网络安全设备包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的服务器的运维监控程序,所述服务器的运维监控程序被所述处理器执行时实现上述的服务器的运维监控方法的步骤。
36、此外,为实现上述目的,本技术还提供了一种计算机可读存储介质,其上存储有服务器的运维监控程序,所述服务器的运维监控程序被处理器执行时实现上述的服务器的运维监控方法的步骤。
37、此外,为实现上述目的,本技术还提供一种计算机程序产品,所述计算机程序产品包括服务器的运维监控程序,所述服务器的运维监控程序被处理器执行时实现如上文所述的服务器的运维监控方法的步骤。
38、本技术实施例提供了一种服务器的运维监控方法、装置、设备、存储介质及产品的技术方案,通过获取当前操作命令关联的视频帧,并根据视频帧确定当前操作命令对应的图片编码向量,接着从已确定的各文本编码向量中确定当前操作命令对应的图片编码向量的目标文本向量,最后输出所述目标文本向量对应的目标提示文本,以在用户操作服务器时,根据用户的操作命令以及该操作命令的命令执行结果进行相应的提示。由于语音表示模型采用图片编码向量和已确定的各文本编码向量之间的对应关系进行训练得到,语音表示模型对标注过的数据的适应能力较强,训练所使用的图片编码向量和已确定的各文本编码向量无需预先进行标注,因此,能够摒弃相关技术中的监督学习方法中只能识别到标注数据,未标注的数据不能识别的方法,提高了模型的泛化能力。
- 还没有人留言评论。精彩留言会获得点赞!