数字人的控制方法、文本大模型的训练方法、系统与流程
本说明书涉及人工智能,尤其涉及一种数字人的控制方法、文本大模型的训练方法、系统。
背景技术:
1、随着人工智能技术的发展,数字人被广泛应用于多种场景,而如何进行数字人驱动,以提高用户与数字人之间的交互体验是数字人控制的重点方向之一。
2、在相关技术中,控制系统可以设置动作库,动作库中包括与各短语各自对应的动作信息,相应的,在控制系统获得数字人的待播报文本的情况下,可以基于待播报文本中的短语与动作库中的动作信息进行匹配,以获得相应的动作信息,并控制数字人执行获得的动作信息。
3、然而,在动作库中动作信息有限的情况下,存在覆盖率较低的弊端,且文本拆分和匹配度可能导致准确性偏低的弊端。
4、值得说明的是,上述相关技术的内容仅仅是发明人个人所知晓的信息,并不代表上述信息在本公开申请日之前已经进入公共领域,也不代表其可以成为本公开的现有技术。
技术实现思路
1、本公开提供一种数字人的控制方法、文本大模型的训练方法、系统,用以避免上述技术问题中的至少一种。
2、第一方面,本公开提供一种数字人的控制方法,所述方法包括:
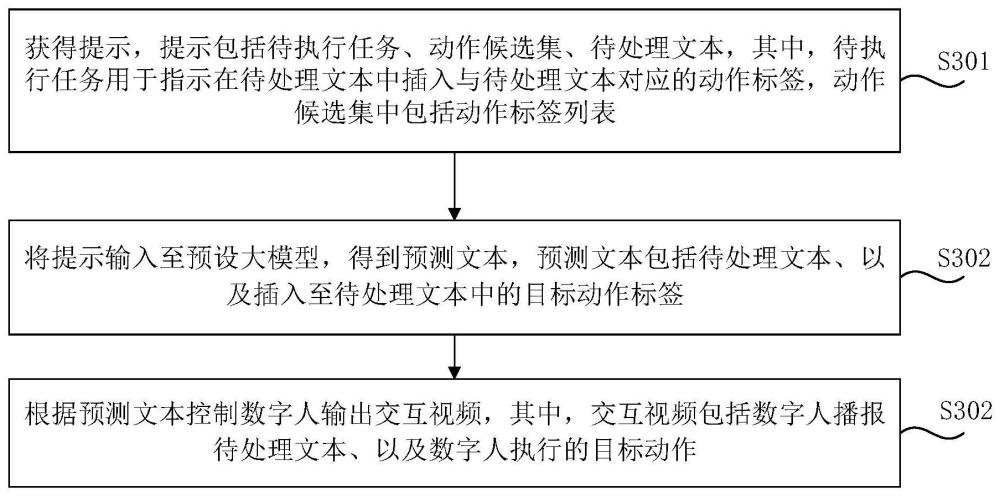
3、获得提示,所述提示包括待执行任务、动作候选集、待处理文本,其中,所述待执行任务用于指示在所述待处理文本中插入与所述待处理文本对应的动作标签,所述动作候选集中包括动作标签列表;
4、将所述提示输入至预设大模型,得到预测文本,所述预测文本包括所述待处理文本、以及插入至所述待处理文本中的目标动作标签,所述目标动作标签对应目标动作;
5、根据所述预测文本控制数字人输出交互视频,其中,所述交互视频包括所述数字人播报所述待处理文本、以及所述数字人执行的所述目标动作。
6、在一些实施例中,在所述预测文本中,所述目标动作标签与所述待处理文本通过预设特殊符号区分;所述根据所述预测文本控制数字人输出交互视频,包括:
7、基于所述预设特殊符号对所述预测文本进行解析,得到所述待处理文本和所述目标动作标签;
8、从预设动作库中获得与所述目标动作标签对应的目标动作执行文件,所述预设动作库中包括各动作标签、以及与各动作标签各自对应的动作执行文件;
9、根据所述待处理文本和所述目标动作执行文件控制所述数字人输出所述交互视频。
10、在一些实施例中,所述根据所述待处理文本和所述目标动作执行文件控制所述数字人输出所述交互视频,包括:
11、根据所述待处理文本的位置信息,预测与所述目标动作执行文件对应的目标动作的时间信息;
12、根据所述待处理文本、所述时间信息、所述目标动作执行文件,渲染并控制所述数字人输出所述交互视频。
13、在一些实施例中,所述获得提示,包括:
14、获得动作决策任务,所述动作决策任务用于指示所述数字人在播报所述待处理文本的情况下,执行与所述待处理文本对应的目标动作;
15、将所述动作决策任务抽象为文本生成任务,所述提示用于表征所述文本生成任务。
16、在一些实施例中,所述待处理文本为与预设的待输出语句对应的文本;或者,
17、所述待处理文本为用于对获得的用户交互信息进行反馈的语句对应的文本。
18、在一些实施例中,所述预设大模型为基于样本数据集训练基础大模型的插入能力得到的文本大模型,所述插入能力是指在所述样本数据集的样本文本中插入对应样本动作标签的能力;或者,
19、所述预设大模型为基于上下文学习进行预测的大模型,所述提示中还包括与所述待执行任务对应的样例。
20、在一些实施例中,不同的数字人控制场景对应不同的数字人,且对应不同的动作候选集,且对应不同的预设大模型。
21、第二方面,本公开提供一种文本大模型的训练方法,所述方法包括:
22、获得样本数据集,所述样本数据集中包括样本提示,所述样本提示包括样本任务、样本动作候选集、样本文本,其中,所述样本任务用于指示在所述样本文本中插入与所述样本文本对应的动作标签,所述样本动作候选集中包括样本动作标签列表;
23、将所述样本数据集输入至基础大模型,以训练所述基础大模型的插入能力,得到文本大模型,所述插入能力是指在所述样本文本中插入对应动作标签的能力;
24、其中,所述文本大模型用于在获得提示的情况下,输出预测文本,所述提示包括待执行任务、动作候选集、待处理文本,其中,所述待执行任务用于指示在所述待处理文本中插入与所述待处理文本对应的动作标签,所述动作候选集中包括动作标签列表,所述预测文本包括所述待处理文本、以及插入于所述待处理文本中的目标动作标签。
25、在一些实施例中,所述样本文本为预设的样本输出语句对应的文本;或者,
26、所述样本文本为用于对获得的样本用户交互信息进行反馈的语句对应的文本。
27、第三方面,本公开提供一种数字人的控制系统,包括:
28、至少一个存储器,所述存储器包括至少一组指令来对数字人进行控制;
29、至少一个处理器,同所述至少一个存储器进行通讯;
30、其中,当所述至少一个处理器执行所述至少一组指令时,实施如第一方面任一项所述的方法。
31、第四方面,本公开提供一种文本大模型的训练系统,包括:
32、至少一个存储器,所述存储器包括至少一组指令来训练文本大模型;
33、至少一个处理器,同所述至少一个存储器进行通讯;
34、其中,当所述至少一个处理器执行所述至少一组指令时,实施如第二方面任一项所述的方法。
35、第五方面,本公开提供一种处理器可读存储介质,所述处理器可读存储介质存储有计算机程序,所述计算机程序用于使所述处理器执行第一方面或第二方面任一项所述的方法。
36、第六方面,本公开提供一种电子设备,包括:处理器,以及与所述处理器通信连接的存储器;
37、所述存储器存储计算机执行指令;
38、所述处理器执行所述存储器存储的计算机执行指令,以实现如第一方面或第二方面任一项所述的方法。
39、第七方面,本公开提供一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现第一方面或第二方面任一项所述的方法。
40、由以上技术方案可知,本公开提供的数字人的控制方法、文本大模型的训练方法、系统,包括:获得提示,提示包括待执行任务、动作候选集、待处理文本,其中,待执行任务用于指示在待处理文本中插入与待处理文本对应的动作标签,动作候选集中包括动作标签列表,将提示输入至预设大模型,得到预测文本,预测文本包括待处理文本、以及插入至待处理文本中的目标动作标签,根据预测文本控制数字人输出交互视频,其中,交互视频包括数字人播报待处理文本、以及数字人执行的目标动作,在本实施例中,控制系统采用大模型对提示进行预测,以得到在提示中的待处理文本的相应位置添加了对应的目标动作的预测文本,以使得预测文本中既包括待处理文本,还包括与待处理文本语义相适配的目标动作,以基于预测文本控制数字人在播报待处理文本的情况下,执行与待处理文本对应的目标动作,以提高目标动作与待处理文本之间的语义匹配程度,即提高数字人执行的目标动作的准确性和可靠性。
41、本说明书提供的数字人的控制方法、文本大模型的训练方法、系统的其他功能将在以下说明中部分列出。根据描述,以下数字和示例介绍的内容将对那些本领域的普通技术人员显而易见。本说明书提供的数字人的控制方法、文本大模型的训练方法、系统的创造性方面可以通过实践或使用下面详细示例中所述的方法、装置和组合得到充分解释。
- 还没有人留言评论。精彩留言会获得点赞!