基于知识蒸馏与模型量化的知识图谱压缩方法
本发明涉及知识图谱压缩,尤其涉及基于知识蒸馏与模型量化的知识图谱压缩方法。
背景技术:
1、知识图谱(knowledge graphs,kgs)是由表示现实世界实体及其关系的事实三元组组成的结构化知识库。其具有高结构、准确性和领域专门化等特点,可以在对话问答、推荐系统和可解释的ai中找到应用。大规模的kgs通常存在稀疏性和不完整性的问题,限制了其应用。为了应对上述挑战,提出利用知识图谱补全(knowledge graph completion,kgc)来补充或纠正现有知识图谱中的缺失信息,提高其完整性。
2、近年来,基于知识图谱嵌入表示(knowledge graph embedding,kge)的模型在知识图谱补全研究中取得了较好的性能。其试图将实体和关系编码到连续低维的嵌入表示空间中,并选取合适的评分函数衡量三元组的合理性。kge简化了符号的操作,同时保留三元组的语义结构和知识图谱的图结构。
3、现有的kge模型主要分为以下三大类:几何方法、张量分解方法和深度神经网络方法。其中几何方法和张量分解方法通常由简单运算和有限的参数进行训练,可扩展到大型知识图谱,但产生的嵌入表示通常表达性能较差。相比之下,深度神经网络方法由于复杂的网络结构和大量的参数,可以学习到更有表现力的嵌入表示。所以近年来,研究人员致力于研发提升深度神经网络方法模型的预测性能,不断的引入学习参数和复杂网络结构,实现了在许多任务中都表现出了出色的性能。
4、然而,附加的计算总量与模型性能提升不是成比例的。而且,复杂的模型在实际应用中存在很大的局限性。且随着kge模型的复杂性和规模的增长,优化kge模型的时间和空间消耗的必要性越来越大。
5、为降低基于深度神经网络的kge方法的复杂性,同时保持其与传统方法相比的优越性能。现有技术公开了一种资源高效的kge模型,其有望显著降低计算和内存需求,使其适合部署在资源受限的嵌入表示式设备上,如物联网和移动设备。同时,kge模型的速度和效率使其适用于需要快速计算的场景,如信息导航和实时分析。此外,资源高效的kge支持cpu上的部署推理,为现有的kge模型提供了一种更经济、更易于访问的替代方案,而不是依赖gpu。通过优先考虑资源效率,有效利用资源的方法扩展了kge模型在各种场景中的适用性,增强了其在各种实际应用中的实用性和可扩展性。
6、具体来说,近年来研究人员相继提出了几种网络压缩方法,如设计高效小型网络、剪枝、量化和蒸馏。其中,二值化网络作为一种基于量化模型的压缩技术,在计算机视觉任务中已经取得了巨大的成功。知识蒸馏使用特殊的迁移学习方法以达到压缩目的,使其已被广泛应用到图像语义识别、目标检测等场景中。
7、然而,上述方法大多数都是为计算机视觉、自然语言处理设计的,由于存在以下问题,使其不能直接用于知识图谱这种复杂的异质图处理任务中:
8、(1)结构复杂性:kgs除了嵌入表示实体和关系外,还需要对事实三元组之间的相互作用进行建模,使其结构不同于具有欧几里得结构的数据(如图像和文本);(2)计算复杂:kgs通常是稀疏且庞大的,需要高嵌入表示维数来表示,这种需求可能会导致网络中涉及大量的计算;(3)浅层网络结构:基于网络的kge模型通常具有1-2层的浅层结构,压缩可学习参数会导致显著的精度损失,并且难以改善浅结构的表示;(4)内存挑战:对于基于图神经网络的kge模型,通常在每个处理步骤中都将整个属性图加载到网络中,这可能会限制内存受限环境下的可扩展性。
技术实现思路
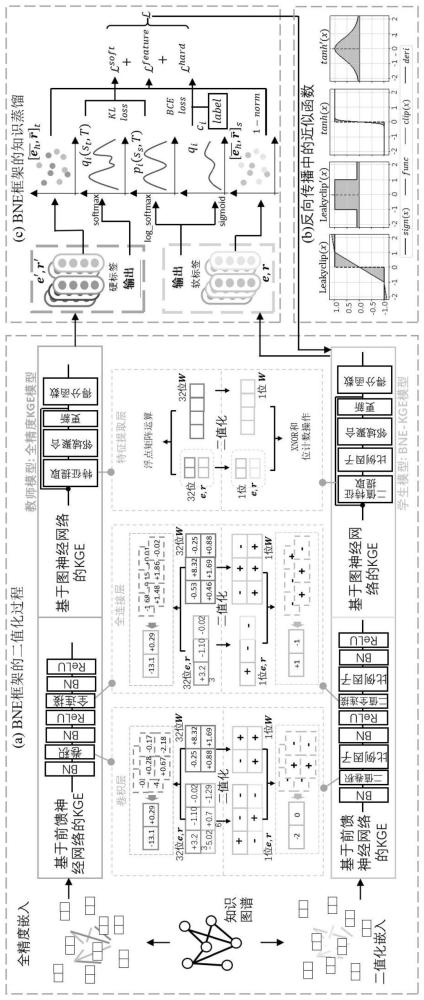
1、为解决上述问题,本发明提供一种基于知识蒸馏与模型量化的知识图谱压缩方法,以1位精度对kge模型的权重和嵌入表示进行二值化,通过反向传播中的梯度近似利用位运算进行计算和训练,可大幅度降低模型的时间和空间复杂度,解决了传统计算复杂以及内存受限的问题;考虑到二值化带来的精度损失,提出了针对kge浅层结构的优化策略:反向传播中二元算子的近似函数和用于在二值化期间恢复丢失信息的因子,解决了传统浅层网络结构存在的精度损失问题;根据知识图谱的结构特征设计了一种知识蒸馏方法,提高了二值化模型的精度,解决了传统结构复杂的问题。
2、为实现上述目的,本发明提供了基于知识蒸馏与模型量化的知识图谱压缩方法,包括以下步骤:
3、s1、利用基于1位的二值化神经网络嵌入表示框架对kge模型的每层网络前的网络权重和嵌入表示进行二值化操作,获得kge初始化二值模型;
4、s2、优化kge二值初始化模型:
5、通过反向传播中的二元算子的近似导数对kge二值初始化模型的浅层结构进行优化;
6、同时通过提取比例因子和单一可伸缩的学习因子恢复网络权重二值化过程中丢失的因子;
7、s3、利用知识蒸馏训练优化后的kge二值初始化模型,得到最终训练好的kge二值化模型,二值化和知识蒸馏技术实现kge模型的压缩,降低训练的时空复杂度;
8、s4、在资源有限的设备上部署kge二值化模型,利用kge二值化模型对输入的知识图谱进行二值化的推理,降低推理的时空复杂度。
9、优选的,步骤s1中,在二值化函数的正向传播中,采用信号函数sign作为二值化算子,其定义如下:
10、
11、式中,x0表示二值化后的输出;x表示kge模型中二值化矩阵的元素;
12、在基于cnn的kge模型的基础上,采用二值化算子将卷积层和全连接层进行二值化,用1-bit的可学习权重和嵌入表示矩阵替代32-bit浮点数,且将基于cnn的kge模型转化为:
13、
14、式中,ψ(eh,r,et)表示评分函数;σ表示激活函数;表示重塑后的头实体嵌入;表示重塑后的关系嵌入;ω表示卷积层的卷积核;w表示全连接层的权重参数;ett表示尾实体嵌入;表示二进制乘法,xnor和bit-count组合的二值化运算;
15、此时,使用直通估计器ste为网络权重和嵌入表示提供有效梯度;
16、步骤s1中,在二值化函数的反向传播过程中,采用截断函数htanh作为二值化算子:
17、x0=htanh(x)=clip(x,-1,1)
18、htanh(x)对x的导数表示为1|x|≤1,则将网络权重的梯度传递表示为:
19、
20、式中,表示损失函数;
21、利用ste估计二值化函数在反向传播的梯度且在当ste的实值大于1时,将梯度置为0,将更新后的实值限制在[-1,+1]间。
22、优选的,在步骤s2中,利用leakyclip函数近似二值化算子sign在反向传播中的函数:
23、
24、式中,f1(x)表示leakyclip函数;
25、或者利用双曲函数hyperbolic近似二值化算子sign在反向传播中的函数:
26、
27、式中,f2(x)表示双曲函数;λ表示超参数。
28、优选的,在步骤s2中,将实值权重在每个输出通道方向上提取一个比例因子,以恢复该通道上的二值化权重的信息,其具体包括以下步骤:
29、针对卷积层的权重参数过滤器中可学习参数ω1,…,ωk分别表示k个卷积核ω,ωp表示第p个卷积核,表示卷积核的四个维度;第p个卷积核权重ωp的比例因子αp定义如下:
30、
31、式中,表示;din表示特征输入维度;kw表示卷积核宽度;kh表示卷积核长度;l1表示1-norm范数;
32、因此,可学习参数ω中元素ω∈ωp通过近似公式如下:
33、ω≈ω'=αpsign(ω)
34、同理,通过1-norm范数计算比例因子得到嵌入的表示:
35、
36、式中,βq表示第q个组合嵌入的比例因子;
37、则卷积层的计算近似为:
38、
39、式中,⊙表示元素乘法;
40、网络层中的二值化计算表示为:
41、
42、式中,★表示全精度网络中的矩阵乘法加法运算操作;x表示嵌入;α表示权重比例因子;β表示嵌入比例因子;
43、将α和β融合到一个单一可伸缩的学习因子γ中
44、
45、优选的,当每个输出通道一个因子时,单一可伸缩的学习因子γ的计算方式如下:
46、
47、式中,a表示可伸缩的学习因子;表示单通道可学习因子;
48、优选的,在步骤s3中,以全精度网络作为教师模型,kge二值化模型作为学生模型,并将链接预测问题转化为多标签二分类问题,引入损失函数;
49、其具体包括以下步骤:
50、s31、以训练好的教师模型为异构图中每个(eh,r)或(r,et)生成所属标签的概率分布软标签;
51、s32、在训练过程中,以学生模型为每个(eh,r)或(r,et)生成概率分布的硬标签;
52、损失函数第一部分是学生模型的硬标签和真实标签之间的二进制交叉熵损失函数:
53、
54、式中,ci表示第i类上的标签值,i∈{1,…,n},n表示节点数;qi=σ(ψ(eh,r)),qi表示输出分布,σ表示激活函数,ψ(eh,r)表示网络输出值;表示批次大小;在此部分,采用sigmoid函数σ(·)生成硬标签的概率分布;
55、损失函数的第二部分是学生模型的硬标签和教师模型的软标签之间的kl散度:
56、
57、式中,pi(ss,t)表示学生模型在特定温度t下softmax函数输出在第i类上的概率值;qi(st,t)表示教师模型在特定温度t下softmax函数输出在第i类上的概率值;
58、计算如下:
59、
60、式中,si表示教师模型的输出;sj表示学生模型的输出;在此部分,采用特定温度t下softmax函数生成软标签、硬标签的概率分布;
61、损失函数的第三部分通过缩小教师模型、学生模型之间嵌入表示向量的距离,缩小教师模型、学生模型之间特征映射的距离:
62、
63、式中,和分别表示教师模型、学生模型的嵌入表示;表示特征的损失函数;表示l2-范数;
64、得到损失函数如下:
65、
66、式中,α和β表示两个超参数。
67、本发明具有以下有益效果:
68、1、基于知识蒸馏与模型量化的知识图压缩框架—bne,适用于现有基于神经网络的知识图嵌入表示模型,且框架使用1-bit将模型的权重和知识图谱嵌入表示(节点和边)进行二值化,使用位运算代替矩阵运算进行计算,并通过近似反向传播中的梯度进行训练,同时考虑到二值化带来的性能下降,采用反向传播函数、恢复二值化中丢失信息的因子和自己设计的多标签分类上的知识蒸馏技术,实现了与全精度模型相比,在训练内存消耗上显著减少了24倍,并在推理学习过程中加速了46倍;
69、2、对反向传播中二元算子的近似导数进行了优化,以缓解梯度失配问题,提高二值化框架的精度;
70、3、通过提取因子来恢复权值二值化过程中丢失的信息;
71、4、通过离线知识蒸馏技术,使二元模型的精度更接近全精度模型,且无需额外的计算成本。
72、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!