基于模糊粗糙集的数据分级融合方法
本发明属于信息处理领域,涉及一种基于模糊粗糙集的数据分级融合方法,具体涉及一种基于小波聚类的属性重要度分级方法和一种基于模糊粗糙集的属性去冗余方法。
背景技术:
1、数据融合是一项充满潜力的领域,它能够整合多个数据集的信息,以进行深入分析和挖掘,从而产生更为准确的结果。在支付、医疗、农业等诸多领域,数据融合已成为不可或缺的助力。然而,尽管数据融合为人们带来了诸多便利,但也面临着一些挑战。由于数据来源和质量无法保证,直接对这些数据进行融合往往会导致融合后数据的质量不佳,甚至存在属性冗余的问题。例如,一个数据集的数据中记录了用户的住址信息,另一个数据集的数据中记录了用户的邮政编码,由于从用户的住址信息就可以得到邮政编码,因此邮政编码就是冗余的。属性冗余是数据融合中一个亟待解决的问题,冗余数据过多不仅会浪费计算资源,还会引起后续的分析和挖掘工作的分析结果失真、模型性能下降、复杂度高等问题。
2、目前,解决属性冗余的重要方法之一是属性约简,其主要分为基于信息熵、基于证据理论和基于粗糙集的方法。前两种方法都是针对两个属性之间的,通过一些方法寻找两个属性变量之间的关联程度,从而隐去高于某个相似度的属性。然而,在现实生活中,数据融合过程中往往存在多个属性共同蕴含某一特定属性信息的情况,如个人身份证号就包含出生日期、性别、所属省份等信息,这种情况下使用前两种方法就无法解决属性冗余问题。
3、现有的基于粗糙集的属性约简方法能处理多属性的冗余问题,但是目前这种方法主要应用于决策系统中。该方法旨在针对某个决策属性进行约简,从而得到能分类该决策属性的最小条件属性集,用于后续的决策过程。然而,实际的数据挖掘任务需要高质量的融合数据集,以支持各种分析和决策,而不仅仅是针对某项特定决策。此外,目前的粗糙集理论不适用于连续性数据,而现实的数据集中大多包含连续型数据。同时,在数据融合中,不同的属性所包含的信息量是不同的,数据分布也会对属性重要程度产生影响,因此在得到属性约简的结果后,如何对属性进行取舍,舍去信息量少的属性,留下更有价值的属性也是一个需要考虑的问题。
技术实现思路
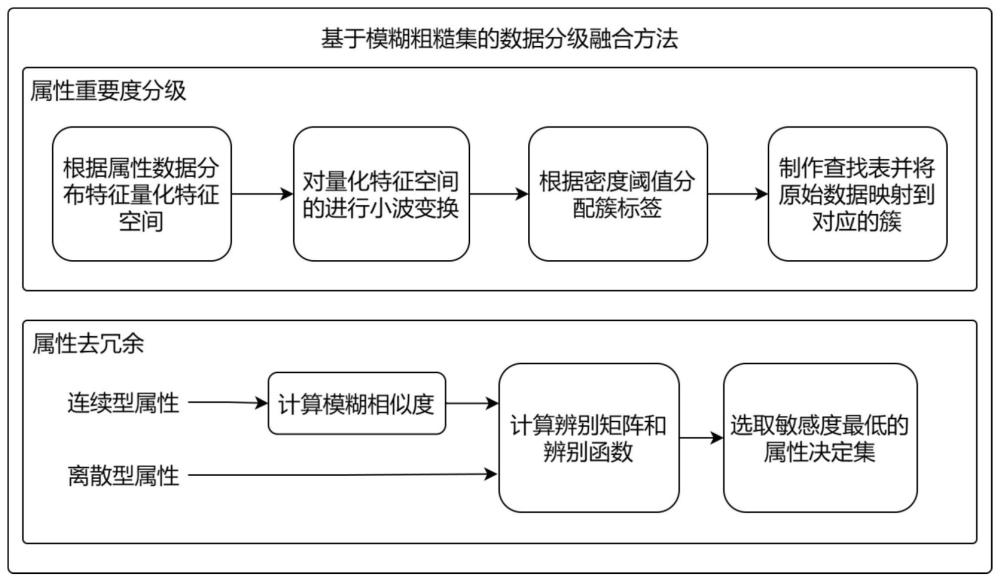
1、为了有效解决数据融合中存在的属性冗余问题并保留最有价值的属性,本发明提出了一种基于模糊粗糙集的数据分级融合方法。首先,该方案提出了一种基于小波聚类算法的重要度分级策略,考虑数据的偏态和峰态对属性敏感度的影响,对融合数据按照属性重要程度进行分簇。然后,提出利用基于粗糙集的属性约简方法解决数据融合中单属性蕴含在多个属性中的属性冗余问题。最后,引入基于核函数的模糊相似关系,解决了粗糙集理论在连续型属性或带扰动的属性上不兼容的问题。
2、本发明的技术方案:
3、一种基于模糊粗糙集的数据分级融合方法,步骤如下:
4、定义变量:
5、表1常用的变量及说明
6、
7、续表1常用的变量及说明
8、
9、具体步骤如下:
10、(1)利用小波聚类算法对属性重要程度进行分簇,使用属性敏感度、偏态系数和峰态系数共同作为属性重要程度的特征,选择属性重要程度最高的作为待约简属性;
11、对属性重要程度进行分簇,具体过程如下:
12、(1.1)首先利用属性敏感度、偏态系数、峰态系数得到属性重要度特征,并利用变异系数量化特征空间划分网格;
13、属性敏感度(as):对数据集d中的属性ai(为数据集d中所有属性的集合)中所含信息不同将属性敏感度定义为属性最大离散熵与属性信息熵的差值和属性最大离散熵的比值,公式定义如下:
14、
15、其中,h(ai)为属性xi的信息熵,hmax(ai)为属性ai的最大离散熵。
16、asi∈(0,1),属性敏感度asi越小,说明属性越敏感,反之则越不敏感。
17、偏态系数(sk):用于测量数据集d中某一属性ai的偏斜程度,对未分组原始属性计算偏态系数时,公式定义如下:
18、
19、其中,n表示数据集d中的数据条数,xj表示数据集d中第j条记录对应的属性ai的值,s表示属性ai的所有取值的标准差,表示属性ai的所有取值的平均值。
20、|sk|=0表示数据是对称分布,|sk|>0表示数据是右偏分布,|sk|<0表示数据是左偏分布。
21、峰态系数(k):用于测量数据集d中某一属性ai的尖峰程度,公式定义如下:
22、
23、其中,n表示数据集d中的数据条数,xj表示数据集d中第j条记录对应的属性ai的值,s表示属性ai的所有取值的标准差,表示属性ai的所有取值的平均值。
24、k=0表示数据是正态分布;k>0表示尖峰分布,数据更集中;k<0表示扁平分布,数据更分散。
25、变异系数(cv):用于度量数据集d中某一属性ai概率分布离散程度,公式定义如下:
26、
27、其中,s表示属性ai的所有取值的标准差,表示属性ai的所有取值的平均值。
28、(1.2)得到以上计算结果后,将属性ai的{asi,|sk|,k}作为特征,对属性集进行分簇。首先对特征空间进行小波变换,得到变换后的特征空间然后根据小波变换后特征空间中数据的分布情况确定阈值,将密度大于阈值的网格标记为稠密,接着将稠密且相连的网格作为一个簇并编号,最后把网格中的数据打上其所在的簇序号的标签;
29、(1.3)建立映射表,将簇标签映射到原始特征空间把原始特征空间中的数据按照簇标签映射到各自的簇,并根据每个簇的中心点的属性敏感度决定该簇的重要度等级,然后选取重要度最高的簇中的属性作为待约简属性。
30、(2)选取待约简属性后,对剩余的连续型属性计算模糊相似度,离散型属性则不需要处理,然后利用基于粗糙集的属性约简算法计算属性的最小决定集,选取敏感度最低的属性决定集作为属性约简集;
31、使用基于模糊粗糙集的属性约简算法进行属性去冗余,具体过程如下:
32、(2.1)首先从重要程度最高的簇中选取敏感度最高的属性作为待约简属性,然后对余下的属性进行遍历,如果该属性是连续型属性就计算该属性下任意两个数据对象的模糊相似度,如果该属性是离散型属性则不需要处理,重复此过程直至对所有的连续型属性都计算了模糊相似度;
33、连续型数据对象的模糊相似关系:用于判断两个任意的连续型数据对象之间是否相似,公式定义如下:
34、
35、其中,ac是任意连续型属性,x,y是两个任意的数据对象,表示数据对象x,y在属性ac的条件下是相似的,是高斯核函数,ε是一个阈值,ε∈[0,1]。
36、(2.2)计算待约简属性的辨别矩阵和辨别函数,根据属性重要度分簇结果选取敏感度最低的属性决定集。
37、本发明的有益效果:数据融合能够整合多个数据集的数据以便进行数据分析和挖掘,但在带来方便的同时,也带来了一系列的问题。直接对多个数据集的数据进行融合会导致得到的融合数据可用性较低,特别是会造成当前研究较少的属性冗余问题,因此,本发明提出一种基于模糊粗糙集的数据分级融合方法。
38、在对属性重要度进行分级时,考虑到每个属性蕴含的信息量不同导致的每个属性的重要程度也不同,同时属性分布情况也会对属性重要程度造成影响的问题,利用属性敏感度、偏态系数和峰态系数共同作为属性重要度的特征,能够更准确地度量属性的重要程度。
39、利用核函数改进连续型属性的模糊相似关系,将一定范围内的属性视为相似,一方面可以解决粗糙集不适用于连续型属性的问题,另一方面也提升了对噪声的抗干扰能力。
- 还没有人留言评论。精彩留言会获得点赞!