一种速溶阿胶粉加工过程监测数据智能分析方法与流程
本发明涉及模式识别,具体涉及一种速溶阿胶粉加工过程监测数据智能分析方法。
背景技术:
1、速溶阿胶粉是一种传统的中药材,被广泛应用于保健品和药品中。为了保证速溶阿胶粉的生产质量和提高速溶阿胶粉的生产效率,因此,需要对速溶阿胶粉加工过程中的加工数据变化进行准确分析,及时调整加工数据,提高速溶阿胶粉的生产效率。
2、现有方法中通过连通图的分裂聚类算法识别出速溶阿胶粉生产过程中的每种加工数据的各种模式,比如温度、湿度、物料比例和设备运行状态等因素的规律性变化,但在实际情况中,速溶阿胶粉的加工过程存在多个不同的阶段,在不同阶段中,每种加工数据会存在正常的不同变化,进而影响到连通图的构建,使得连通图的分裂聚类结果不准确,无法对速溶阿胶粉的加工数据进行准确监测,无法对各个阶段的加工数据进行准确调整,影响速溶阿胶粉的生产效率。
技术实现思路
1、为了解决在不同阶段中,每种加工数据会存在正常的不同变化而影响连通图的构建不准确的技术问题,本发明的目的在于提供一种速溶阿胶粉加工过程监测数据智能分析方法,所采用的技术方案具体如下:
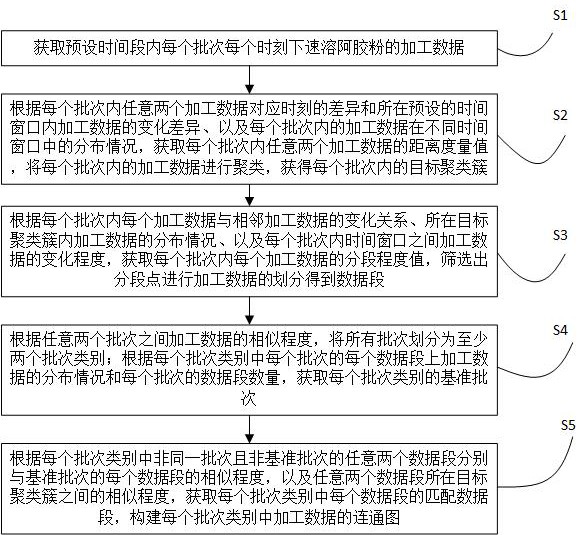
2、本发明提出了一种速溶阿胶粉加工过程监测数据智能分析方法,该方法包括以下步骤:
3、获取预设时间段内每个批次每个时刻下速溶阿胶粉的加工数据;
4、根据每个批次内任意两个加工数据对应时刻的差异和所在预设的时间窗口内加工数据的变化差异、以及每个批次内的加工数据在不同时间窗口中的分布情况,获取每个批次内任意两个加工数据的距离度量值,将每个批次内的加工数据进行聚类,获得每个批次内的目标聚类簇;
5、根据每个批次内每个加工数据与相邻加工数据的变化关系、所在目标聚类簇内加工数据的分布情况、以及每个批次内时间窗口之间加工数据的变化程度,获取每个批次内每个加工数据的分段程度值,筛选出分段点进行加工数据的划分得到数据段;
6、根据任意两个批次之间加工数据的相似程度,将所有批次划分为至少两个批次类别;根据每个批次类别中每个批次的每个数据段上加工数据的分布情况和每个批次的数据段数量,获取每个批次类别的基准批次;
7、根据每个批次类别中非同一批次且非基准批次的任意两个数据段分别与基准批次的每个数据段的相似程度,以及任意两个数据段所在目标聚类簇之间的相似程度,获取每个批次类别中每个数据段的匹配数据段,构建每个批次类别中加工数据的连通图。
8、进一步地,所述根据每个批次内任意两个加工数据对应时刻的差异和所在预设的时间窗口内加工数据的变化差异、以及每个批次内的加工数据在不同时间窗口中的分布情况,获取每个批次内任意两个加工数据的距离度量值,将每个批次内的加工数据进行聚类,获得每个批次内的目标聚类簇的方法为:
9、设定第一预设数量种不同长度的时间窗口,任选一种时间窗口作为目标时间窗口,任选一个批次作为目标批次,以目标批次内的每个加工数据为中心,构建目标批次内每个加工数据对应的目标时间窗口;
10、将每个目标时间窗口内的第一个加工数据与最后一个加工数据相连构成的线段,作为目标批次内对应加工数据的目标线段;
11、根据目标批次内每个加工数据对应的目标时间窗口内相同时刻下的加工数据与目标线段上的加工数据的差异,获取目标批次内目标时间窗口的置信程度值;
12、对于目标批次内的第a个加工数据和第b个加工数据,根据目标批次内每种时间窗口的置信程度值、第a个加工数据与第b个加工数据在每种时间窗口下的目标线段的斜率差异、以及第a个加工数据与第b个加工数据对应时刻的差异,获取目标批次内第a个加工数据与第b个加工数据的距离度量值;
13、根据每个批次内任意两个加工数据的距离度量值,通过dbscan聚类算法将每个批次内的加工数据进行聚类,获得每个批次内的目标聚类簇。
14、进一步地,所述置信程度值的计算公式为:
15、;式中,为第i个批次内第u种时间窗口的置信程度值;n为第i个批次内加工数据的总数量;为第u种时间窗口的长度大小;为第i个批次内第n个加工数据对应的第u种时间窗口内第个时刻下的加工数据;为第i个批次内第n个加工数据的目标线段上第个时刻下的加工数据;exp为以自然常数为底数的指数函数;为绝对值函数。
16、进一步地,所述距离度量值的计算公式为:
17、;式中,为第i个批次内第a个加工数据和第b个加工数据的距离度量值;u为时间窗口的种类总数量;为第i个批次内第u种时间窗口的置信程度值;为第i个批次内第a个加工数据在第u种时间窗口下的目标线段的斜率;为第i个批次内第b个加工数据在第u种时间窗口下的目标线段的斜率;为第i个批次内第a个加工数据对应的时刻;为第i个批次内第b个加工数据对应的时刻;为绝对值函数;norm为归一化函数。
18、进一步地,所述根据每个批次内每个加工数据与相邻加工数据的变化关系、所在目标聚类簇内加工数据的分布情况、以及每个批次内时间窗口之间加工数据的变化程度,获取每个批次内每个加工数据的分段程度值,筛选出分段点进行加工数据的划分得到数据段的方法为:
19、将目标批次内每个加工数据在目标时间窗口下的目标线段的斜率,均作为第一斜率;
20、将最大第一斜率与最小第一斜率的差值,作为目标批次内目标时间窗口的变化程度值;
21、获取目标批次内每种时间窗口的变化程度值,将最大变化程度值作为目标批次的参考变化值;
22、根据目标批次中的第q个加工数据分别与前后相邻的两个加工数据所构成线段的斜率差异、第q个加工数据所在目标聚类簇内的加工数据的分布情况、以及参考变化值,获取目标批次中第q个加工数据的分段程度值;
23、获取目标批次中每个加工数据的分段程度值,当将大于预设的分段程度值阈值的分段程度值对应的加工数据作为分段点,对目标批次内的加工数据进行划分得到数据段;其中,目标批次中每个目标聚类簇的边界加工数据,均为分段点。
24、进一步地,所述分段程度值的计算公式为:
25、;式中,为第i个批次中第q个加工数据的分段程度值;为第i个批次中第q-1个加工数据与第q个加工数据所构成线段的斜率;为第i个批次中第q个加工数据与第q+1个加工数据所构成线段的斜率;为第i个批次中第q个加工数据所在目标聚类簇的离散程度;为预设超参数;为第i个批次中的参考变化值;为绝对值函数;norm为归一化函数。
26、进一步地,所述根据任意两个批次之间加工数据的相似程度,将所有批次划分为至少两个批次类别;根据每个批次类别中每个批次的每个数据段上加工数据的分布情况和每个批次的数据段数量,获取每个批次类别的基准批次的方法为:
27、通过word2vec模型将每个批次的加工数据转化为对应批次的向量,根据任意两个批次的向量的余弦相似度,通过k-means聚类算法,将所有批次进行聚类,获得至少两个批次类别;
28、对于任一批次类别,获取该批次类别中每个批次的数据段数量,作为对应批次的第一数量;
29、对于该批次类别内第z个批次的任一数据段,将该数据段内所有加工数据的切线斜率的均值,作为该数据段的整体变化值;
30、获取该数据段的整体变化值与该批次类别内非第z个批次的其他每个批次的每个数据段的整体变化值的比值,均作为第一值;
31、将每个第一值与第一预设常数的差值绝对值均作为第一差异值,将最小的第一差异值作为该数据段的不稳定程度值;其中,第一预设常数大于0;
32、根据第z个批次的第一数量在该批次类别内所有第一数量中的偏离程度、第z个批次的每个数据段的变异系数和不稳定程度值,获取第z个批次的基准程度值;获取该批次类别内每个批次的基准程度值,将最大的基准程度值所对应的批次,作为该批次类别的基准批次。
33、进一步地,所述基准程度值的计算公式为:
34、;式中,为第y个批次类别内第z个批次的基准程度值;为第y个批次类别内最大的第一数量;为第y个批次类别内第z个批次的第一数量;为第y个批次类别内第一数量的均值;为第y个批次类别内第z个批次的第s个数据段的变异系数;为第y个批次类别内第z个批次的第s个数据段的不稳定程度值;为绝对值函数;exp为以自然常数为底数的指数函数。
35、进一步地,所述根据每个批次类别中非同一批次且非基准批次的任意两个数据段分别与基准批次的每个数据段的相似程度,以及任意两个数据段所在目标聚类簇之间的相似程度,获取每个批次类别中每个数据段的匹配数据段,构建每个批次类别中加工数据的连通图的方法为:
36、对于任一批次类别内的任一数据段,通过动态时间规整算法,获取该数据段与基准批次的每个数据段之间的dtw距离,将该数据段对应的最小的dtw距离,作为该数据段的第一特征值;其中,该数据段一定不属于基准批次;
37、根据每个批次类别中非同一批次且非基准批次的任意两个数据段的第一特征值和所在目标聚类簇之间的互信息值,获取每个批次类别中非同一批次且非基准批次的任意两个数据段的匹配程度值;
38、将每个批次类别中每个数据段对应的最大匹配程度值所对应的另一个数据段,作为对应数据段的匹配数据段;
39、将每个批次类别中每个数据段与其匹配数据段进行连接,构建每个批次类别中加工数据的连通图。
40、进一步地,所述匹配程度值的计算公式为:
41、;式中,为第y个批次类别内第z个批次的第l个数据段与第x个批次的第h个数据段的匹配程度值;为第y个批次类别内第z个批次的第l个数据段的第一特征值;为第y个批次类别内第x个批次的第h个数据段的第一特征值;为第二预设常数,大于0;为第三预设常数,大于0;为第y个批次类别内第z个批次的第l个数据段与第x个批次的第h个数据段所在目标聚类簇之间的互信息值;norm为归一化函数;exp为以自然常数为底数的指数函数。
42、本发明具有如下有益效果:
43、根据每个批次内任意两个加工数据对应时刻的差异和所在预设的时间窗口内加工数据的变化差异、以及每个批次内的加工数据在不同时间窗口中的分布情况,获取每个批次内任意两个加工数据的距离度量值,准确的表示加工数据之间的相似程度,进而基于距离度量值,将每个批次内的加工数据进行聚类,获得每个批次内的目标聚类簇,将每个批次内的加工数据进行初步划分,为准确获取每个批次内的各个阶段的加工数据做准确;进而根据每个批次内每个加工数据与相邻加工数据的变化关系、所在目标聚类簇内加工数据的分布情况、以及每个批次内时间窗口之间加工数据的变化程度,获取每个批次内每个加工数据的分段程度值,确定每加工数据为分段点的可能程度,进而基于分段程度值,筛选出分段点进行加工数据的自适应划分得到数据段,确定每个批次内各个阶段的加工数据,提高对加工数据进行分析的准确性;考虑到不同批次之间的加工数据存在差异,影响对加工数据的分析,因此,根据任意两个批次之间加工数据的相似程度,将所有批次划分为批次类别,提高对批次分析的效率和准确性;为了对每个批次类别内的加工数据进行准确的分析,进而根据每个批次类别中每个批次的每个数据段上加工数据的分布情况和每个批次的数据段数量,获取每个批次类别的基准批次,在基准批次的基础上,准确获取每个批次类别中每个数据段的匹配数据段,自适应构建每个批次类别中加工数据的连通图,使得构建的连通图越准确,进而使得连通图的分裂聚类结果越准确,进而对每个批次类别中的各个阶段的加工数据进行准确分析,便于后续准确调整不同批次类别的速溶阿胶粉进行加工的各个阶段的加工数据,提高速溶阿胶粉的加工效率。
- 还没有人留言评论。精彩留言会获得点赞!