一种面向医疗图像的光学字符识别方法
本发明涉及一种面向医疗图像的光学字符识别方法,属于光学字符识别领域。
背景技术:
1、近年来,随着数字化医疗信息的快速增长,从医疗图像中提取和识别文本的需求日益迫切。医学报告、病历、处方笺和医疗影像等都包含了大量的文本信息。然而,传统的医疗图像是以图像形式存储的,无法直接进行文本搜索和分析。因此,将医疗图像中的文本提取出来并转换为可编辑和可搜索的格式对于医疗信息的管理和利用至关重要。面向医疗图像的光学字符识别方法能够自动识别和转换医疗图像中的文本,如出院小结、门诊档案、体检结论、药品信息等。这项技术的发展将极大地提高医疗数据的可访问性和可搜索性,促进医疗信息管理和决策的效率。
2、传统的光学字符识别方法通常基于规则或模板。基于规则的光学字符识别方法通过事先定义的规则和模式来识别和提取医疗图像中的文本。这些规则可以包括字母和数字的形状、尺寸、颜色等特征。基于模板的光学字符识别方法使用预先构建的模板来匹配和识别医疗图像中的文本。这些模板可以是字符、单词或特定的文本模式。通过与模板的匹配,识别和提取文本信息。此外机器学习方法在医疗图像光学字符识别方法中也被广泛应用。这些方法使用特征提取和分类算法来识别医疗图像中的文本。常见的特征提取方法包括边缘检测、形状描述符和纹理特征等。分类算法可以包括支持向量机(svm)、k最近邻(knn)和随机森林(random forest)等。
3、但是基于规则的方法往往对复杂布局和不规则文本处理能力有限,且需要手动定义和调整规则,难以应对各种不同类型的医疗图像。对于复杂布局、不规则文本或低对比度图像的处理效果有限。基于模板的方法对于不同字体、大小和布局的文本识别能力有限,且需要大量的模板构建和管理。至于机器学习方法对于复杂的医疗图像和文本特征提取可能存在局限性,且需要手动设计和选择特征,对大规模数据的处理和泛化能力有一定挑战。此外,传统机器学习方法往往需要大规模标注数据进行训练,且在处理大量数据时性能下降明显。
4、而深度学习技术的兴起为图像识别和光学字符识别领域带来了新的突破。卷积神经网络(cnn)和循环神经网络(rnn)等深度学习模型在文本检测和识别任务中取得了显著的成果。这些模型能够自动学习特征表示和上下文信息,从而提高光学字符识别的准确性和鲁棒性。
5、然而,深度学习技术仍面临一些挑战。首先,现有技术往往依赖大规模标注数据,这限制了其在现实场景的应用。其次,由于在面向医疗图像的场景下,对于识别准确性的要求较高,而医疗图像类型繁多,不同种类的医疗图像特征差距较大,例如场景类别的医疗图像的文本存在不同尺度和形变的问题,而这样的特征在文档类的医疗图像中是不存在的,若仅使用单独的模型对图像进识别,便难以准确地处理。此外,目前的光学字符识别结果通常是成行状独立输出的,而医疗图像的特殊结构往往会是多栏、分立的,使得识别文本的单行输出结果存在多种条不相干的语句,造成文本语义上的割裂和杂糅,丧失了原本的结构信息,这往往是研究人员所不期望看到的。
技术实现思路
1、技术问题:本发明提供一种对于给定的一张医疗文档的图像或扫描副本,能够自动化地识别图像中每个包含文本信息的区域,并提取出对应医疗信息文本,根据上下文语义,分块组合成拥有完整语义的段落,形成医疗信息的结构化输出的面向医疗图像的光学字符识别方法。
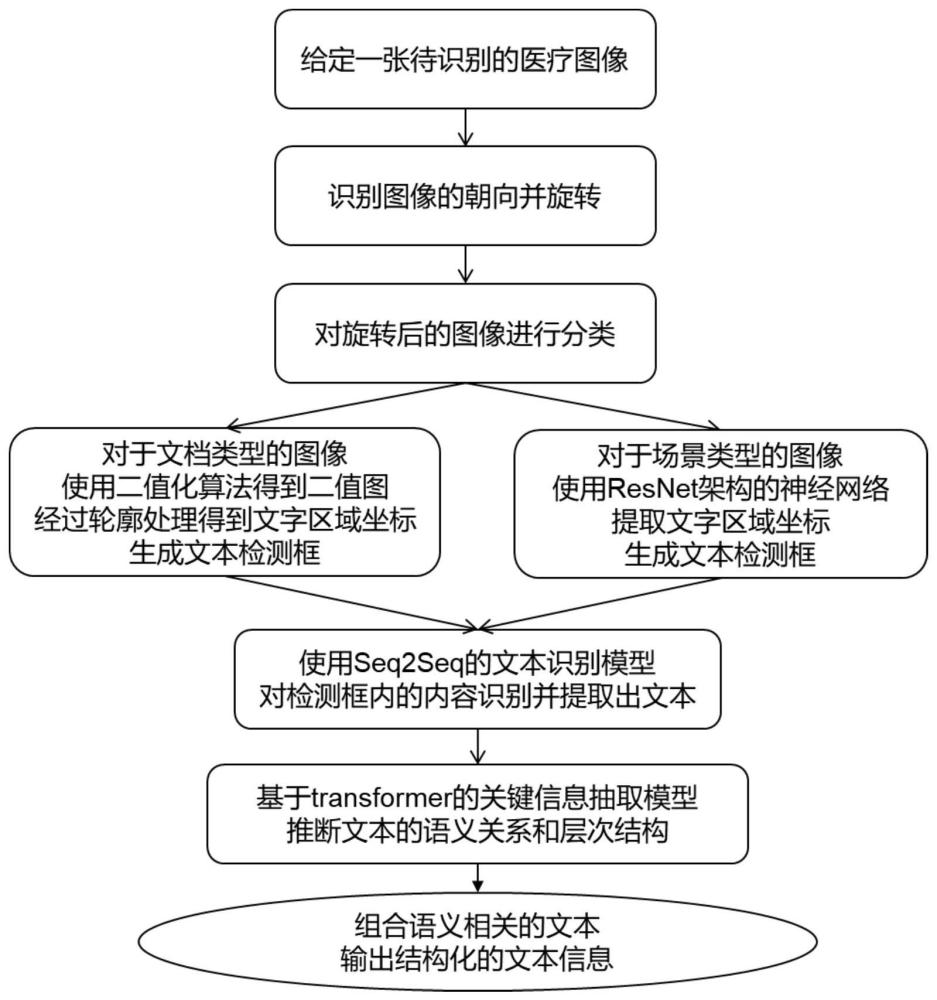
2、技术方案:本发明的面向医疗图像的光学字符识别方法,首先加载训练的神经网络模型,对于给定医学图像进行识别图像的朝向,并对图像的方向进行纠正。然后基于矫正后的图像进行分类任务,得到图像的两种细分类别,对于两种不同的类别分别使用不同的方法对图像进行文本检测,选择出包含医学文本的图像部分,形成检测框。再训练一种文本识别模型根据检测框识别并提取出文本内容。最后使用一种基于transformer的模型,进行上下文建模和特征提取。推断出文本的语义和层次结构,以及元素之间的关系。组合相关文本进行结构化的输出。
3、本发明的面向医疗图像的光学字符识别方法,包括如下步骤:
4、步骤1:首先对图像进行处理。给定医疗图像或文档的扫描副本作为输入,这些图像可以包括病人的出院小结、门诊档案、体检结论、药品图片等。对输入图片进行预处理,包括调整大小、裁剪或填充等操作,以确保图像的一致性和易处理性。利用卷积神经网络模型预测并调整图像的朝向,得到矫正后的图像。在进行以下步骤之前,对输入图像进行分类。
5、步骤2:其次,对分类后的图像进行文本检测。对于文档类的图像,使用二值化算法对将分类后的图像进行处理得到二值图,二值图经过连通区域分析得到文本检测框。对于场景类的图像,使用resnet架构的神经网络提取文字区域坐标,记录文本检测框信息。
6、步骤3:然后在步骤2中得到的文字区域的检测框信息的基础上,进行文本识别。其特征在于:将输入图像分割为小块。这些小块被转换为一维的图像嵌入,对于每个小块将其图像嵌入与其对应的位置嵌入拼接作为seq2seq模型的输入,该模型经过端到端的训练,以预测字符序列,获得识别文本。
7、步骤4:最后,基于步骤2中的位置信息和步骤3中获得的识别文本,融合文本、位置、视觉信息,进行关键信息抽取,实现结构化文本的输出。其特征在于:基于步骤3中获得的识别文本获取文本嵌入。基于步骤2中的检测框获取位置嵌入。提取输入图像的特征信息并形成视觉嵌入。将文本、位置、视觉的嵌入信息组合作为文本检测模型的输入。进行上下文建模和特征提取。推断出文本的语义和层次结构,以及元素之间的关系。组合相关文本,进行结构化文本的输出。
8、本发明方法的优选方案中,所述步骤1中,按照如下方式调整图片的方向:
9、1-1构建一个卷积神经网络,对于待训练图像,经过重新调整大小、裁剪或填充等方式调整至一个固定大小的图像,如1024*1024像素,作为模型的输入,模型预测并输出一个连续值,表示图像的旋转角度。使用标签为旋转角度的训练集进行模型训练,通过最小化预测的旋转角度与真实标签差值的交叉熵损失来优化模型参数。
10、模型训练完毕后,对于待识别的图像,需要进行同样的预处理,将其调整为相同大小的图像。然后,将该图像输入训练好的模型中,模型将预测出图像的旋转角度。根据预测出的角度,对图像进行相应的旋转矫正。
11、1-2根据1-1所述的通过训练卷积神经网络来学习图像特征:模型输入经过5个卷积层,使用relu激活函数进行非线性映射,每个卷积层之间使用最大池化和归一化提取特征。随后经过全连接层将提取的特征映射到类别上。
12、本发明方法的优选方案中,所述步骤1中对医疗图像的分类并检测文本区域处理流程如下:
13、利用卷积神经网络,将图像分为文档类的医疗图像和场景类的医疗图像。模型采用与步骤1中的卷积神经网络相同的架构,训练图像为标记为文档类和场景类的两类医疗图像。对这两种医疗图像采用不同的文本检测方法。
14、本发明方法的优选方案中,所述步骤2中对于文档类医疗图像的处理流程如下:
15、(1)输入的待检测图像首先经过resnet的特征提取网络,经过不同层级的采样之后获得不同大小的特征图,提取图像的高级特征表示。然后,通过fpn(feature pyramidnetwork)模块,将不同层级的特征图进行融合,从顶层特征图开始,通过上采样将其尺寸增大,然后与较低层级的特征图进行逐元素相加,以融合不同层级的特征信息,获取统一尺度的特征图f。该特征图f将经过一系列卷积和转置操作获取分割概率图p(probability map)与阈值图t(threshold map)。
16、(2)然后通过将p、t这两个特征图进行差分操作,得到文字区域的二值图。最后,进行连通区域分析,使用四连通方法,广度优先遍历二值图的每个像素,将相邻的像素分配给同一个区域,并为每个区域分配一个唯一的标记。根据标记的像素,创建不同的连通区域,形成单行的文本检测框。
17、(3)采用下述的方法进行二值化:
18、
19、其中b是近似二值图,bi,j表示近似二值图中第i行第j列的二值化数值;p是经过一系列卷积和转置操作获取分割概率图,pi,j表示概率图第i行第j列的数值;t是从网络获知的自适应阈值图,ti,j表示自适应阈值图第i行第j列的数值;k表示放大因子,k根据经验设置为50。
20、本发明方法的优选方案中,所述步骤2中对于场景类医疗图像的处理流程如下:
21、(1)待检测图像经过基于resnet的fpn特征金字塔网络,其操作类似于对文档类图像的处理,然后通过3×3的全卷积层输出与原图尺寸相同的四个预测结果:图p:待检测图像某像素点属于文本中心线像素点的概率图;文本中心偏置图d1:待检测图像某像素点距其所属的文本检测框中心的x、y方向距离;文本顶点偏置图d2:待检测图像某像素点距其所属的文本检测框四顶点的x、y方向距离;文本边框偏置图d3:待检测图像某像素点距其所属的文本检测框上下边距的x、y方向距离,其中,文本检测框是判定为文本区域的最小外接四边形,文本中心线区域是文本检测框上下边界收缩至20%后得到的区域,而左右边界仍保持不变。
22、(2)然后利用整体信息对像素点进行像素级分类方法,将具有相同特征的、破碎分离的像素点归类为同一文本区域。对概率图p进行阈值过滤,将概率低于某值的假阳性像素点剔除,然后将经过处理的概率图p中每个像素点,根据文本顶点偏置图d2,得到对应的文本检测框四顶点坐标,并进行非最大值抑制,剔除重叠的文本检测框,得到所需的文本检测框及其中心点,该文本检测框将作为整体信息;根据文本中心偏置图d1,计算概率图p中属于文本的像素点其所属文本区域的几何中心点,该中心点将作为像素信息,当计算所得的几何中心点与检测框中心点重合或相近时,该像素点将被归类给文本检测框对应的文本区域。其余未被选中的像素点,将通过此步骤重新聚集归类,将所有高于阈值的像素点划分为属于不同的文本。根据属于同一文本的像素点,重新修正概率图p。
23、(3)在上述基础上,对文本中心线采样,采样点的间距相同。根据文本边框偏置图d3所提供的信息,计算文本中心线的采样点上的上下边界定位点,将所得的边界定位点按照从左上角开始的顺时针方向依次进行连接,得到最终的文本检测框。
24、本发明方法的优选方案中,所述步骤3基于步骤2中得到的文字区域的检测框信息的基础上,进行文本识别,具体步骤如下:
25、3-1将输入图像分割为小块。这些小块通过linear projection进行线性变换,转换为为一维的图像嵌入,对于每个小块将其图像嵌入与其对应的位置嵌入拼接作为seq2seq模型的输入,该模型经过端到端的训练,以预测字符序列,获得识别文本。
26、3-2在seq2seq模型的编码器部分,每个输入首先经过归一化层(ln),然后通过多头自注意层(msa)确定特征向量之间的关系。使用多头注意力机制让模型共同关注来自不同位置的不同表示子空间的信息。注意力头的个数为h。ln与msa的输出进行残差连接后经过归一化层,再使用前馈神经网络进行特征提取,前馈神经网络由2层组成,使用gelu激活,最后前馈神经网络的输出再经过一次残差连接,输出识别的结果。本发明使用[go]标记来标记文本预测的开头,[s]表示结尾或空格。
27、第一个编码器块的输入记作t0,其计算方式如下:
28、
29、多头注意力层的输出如下:
30、t′l=msa(ln(tl-1))+tl-1
31、前馈神经网络的输出如下:
32、tl=f(ln(t′l))+t′l
33、最后,通过线性投影形成单词预测:
34、
35、其中,xclass表示输入图像的类别信息,该类别嵌入会被添加到序列的起始位置,以确保模型在处理序列时能够考虑到整个序列所属的类别。表示第n个小块的嵌入,epos表示所有n个小块的位置嵌入。对于tl中的l,l=1,2,...,l,l是编码器块的数量,而transformer编码器由共l个编码器块组成。yi表示识别的第i个字符,其中i=1,2,...,s,s表示能够识别的最大字符序列长度加上2个特殊字符[go]和[s],并且n<s。linear()是一个线性变换操作,将前馈神经网络的输出投影成预测的字符。
36、本发明方法的优选方案中,所述步骤4进行关键信息抽取,实现结构化输出,具体流程如下:
37、4-1基于步骤3中获得的识别文本进行文本嵌入,其特征在于,步骤如下:先使用n-gram进行分词,分词后的单词作为网络的标记。前面添加<cls>标记,后面添加<sep>标记,如果没到最大长度,用<pad>标记补齐。使用与bert相似的transformer编码器来对输入文本进行编码,形成文本嵌入。并结合一维相对位置信息、二维的位置信息和分段向量,具体如下:
38、texti=tokemb(wi)+posemb1d(wi)+posemb2d(wi)+segment(si)
39、其中,tokemb(wi)表示通过编码器得到的字符wi的文本嵌入;一维相对位置信息posemb1d(wi)表示即字符wi的索引;二维的位置信息posemb2d(wi)表示字符wi的坐标信息的嵌入;segment(si)表示文本的分段向量,对于场景类的图像其值取a,对于文档类的图像其值取b。
40、4-2基于步骤2中获得的检测框信息进行位置嵌入,其特征在于,步骤如下:用(xi,yi)表示检测框的中心坐标,wi和hi表示检测框的宽度和高度。将这些信息转换为嵌入向量posi如下:
41、posemb2dx=linear(xi,yi,wi)
42、posemb2dy=linear(xi,yi,hi)
43、posi=concatenate(posemb2dx,posemb2dy)
44、其中,linear()表示一个线性投影操作,将输入向量(xi,yi,wi)和(xi,yi,hi)投影到嵌入向量空间,concatenate()表示拼接操作。
45、4-3提取图像特征并形成视觉嵌入,其特征在于,步骤如下:通过resnet-fpn提取图像特征转换为嵌入向量,并结合二维的位置信息和分段向量,具体如下:
46、visi=vistokemb(gi)+posemb2d(gi)+segment(si)
47、其中,gi表示单个文本检测框所包含区域的图像,vistokemb(gi)表示通过resnet-fpn提取特征并转换为一维的图像gi的嵌入;二维的位置信息posemb2d(gi)表示图像gi的坐标信息的嵌入;segment(si)表示图像的分段向量,其值取c。
48、4-4该模型从三个模态——文本、位置和图像接收信息,并融入到文本/位置/视觉嵌入中。具体如下:
49、inputi=concatenate(visi,texti)+posi
50、outputi=linear(encoder(inputi))
51、文本和视觉的嵌入向量进行了拼接,concatenate()表示拼接操作,将视觉嵌入向量visi和文本嵌入向量texti进行拼接。并加上位置嵌入posi,得到最终的嵌入向量inputi。将嵌入向量inputi输入到transformer编码器进行编码,encoder()表示编码器,linear()表示一个线性投影操作,经过两步操作最终转换为标签序列outputi并输出,根据标签序列组合相关文本进行结构化的输出。
52、本发明提出的面向医疗图像的光学字符识别方法,在进行文本识别之前对于医疗图像进行预处理,针对于不同类别的医疗图像具有的特征采用针对性的文本检测方法,能够更准确的检测出文本信息。接着通过seq2seq的模型进行文本识别。在文本识别之后,进行了关键信息抽取,分析了识别文本的上下文信息,实现了相关文本的组合和结构化的输出。大大提升了对于医疗图像的识别准确性和结构性。
53、有益效果:本发明与现有技术相比,具有以下优点:
54、相比传统的面向医疗图像的光学字符识别方法,本发明通过在文本检测环节之前进行分类,利用卷积神经网络,将图像分为文档类的医疗图像和场景类的医疗图像,针对图像的类别进行不同方法的文本检测,可以得到更准确的结果。文档类的医疗图像通常是出院小结这样的具有一定的特殊结构的纯文本类型,而场景类的医疗图像通常是药品图片这样的混合有图形、文字衬于其中的场景图片,这两种类型的图片具有不同的特征,针对不同类型的图像使用独特的文本检测方法,对于文本区域的检测更加精确。而传统的面向医疗图像的光学字符识别方法并没有对这两种类型做出区分,用同一种模型进行处理,有出现部分文本区域检测失败的问题,后续的识别步骤也就无法完成。
55、相比传统的面向医疗图像的光学字符识别方法,本发明在光学字符识别之后进行关键信息抽取步骤,进行上下文建模和特征提取,推断文本的语义和层次结构,以及元素之间的关系,组合相关文本,进行结构化文本的输出。医疗图像中的文本信息有其独特的形状结构特征,通常是多段长文本成块状、多列分布于同一水平位置。本发明结合医疗图像的布局,分析识别出单行文本的上下文信息和语义信息,并对具有相关语义的文本区域进行拼接,还原医疗图像中文本原本具有的结构信息。而传统的面向医疗图像的光学字符识别方法,并没有考虑医疗图像的独特结构,仅仅是单独的识别出单行或者多行的文本,这会导致多段文本信息杂糅在一起,不仅使得识别出的文本语义混乱,而且后续对于文本的处理需要消耗更多人力,在医疗图像的光学字符识别领域,对于识别结果的准确性和结构信息的还原不如本发明。
56、经过实验分析证明,利用本发明提出的面向医疗图像的光学字符识别方法,可以完成任意给定医疗图像的文本识别并提取的任务。无论是识别文本准确率,还是还原本图像中文本的结构信息,本发明在这些方面上都是处于一个领先的地位。
- 还没有人留言评论。精彩留言会获得点赞!