一种多用户GPU集群的深度学习任务调度方法
本发明涉及计算机,尤其涉及的是一种多用户gpu集群的深度学习任务调度方法。
背景技术:
1、深度学习任务在各个领域取得巨大成功,促进了用户在图形处理单元(gpu)集群内构建专用的gpu加速器的发展;但是,能源消耗愈发成为降低运营成本和提高资源利用率的关键技术瓶颈。在多用户的gpu集群中,经常存在多个在线分布式深度学习(ddl)任务在短时间内陆续发射的现象,若调度不当,可能导致非常严重的系统资源浪费。对处理不断增加的作业的在线调度系统来说,灵活的资源分配和高效的作业调度对于提高资源利用率是必不可少的。由于gpu内部硬件资源以流式多处理器(sm)为基本单位进行调度,因此,理论上同一块gpu可同时支持多个ddl训练任务运行于其上,受此启发,共享调度策略逐渐开始受到关注与研究。
2、现有的调度器一般有两种优化倾向:抢占式调度与共享式调度。
3、第一种优化方向通过抢占正在运行的任务的资源,或者通过修改用户提交的深度学习网络架构等方式来优化集群的整体资源利用率,这类调度器面临着抢占和迁移所带来的额外开销,以及潜在的训练精度下降等问题。该方向较为先进的启发式调度器tiresias证明,在任务用时已知的前提下,最少剩余服务优先(srsf)算法通常会得到最优解,但该调度器对于资源需求多的短任务、资源需求少的长任务的排队时间是不友好的,容易造成该类任务的饥饿。该方向的调度器pollux提出动态调整分布式深度学习任务的实际gpu分配数,从而达到更高的资源利用率,同时兼顾调度的公平性,最大程度上解决任务的饥饿问题,然而该调度器通常会破坏用户的预期gpu数,更可能擅自修改用户自定义的训练超参数,这可能导致训练精度低的问题,从而导致无法达到用户训练分布式深度学习任务的预期目标,限制了其在实际场景中的实用性。
4、第二种优化方向通过在同一块gpu上为两个或更多的训练任务分配sm来进行训练,从而优化所有任务的排队等待时间,以期降低整体任务完成耗时(jct),这类调度器则面临着难以避免的任务之间竞争计算资源与网络通信资源的问题。该方向具有代表性的调度器lucid考虑了对单机深度学习任务进行共享,从而有效地解决排队时间问题,缓解任务饥饿问题,但其共享方式中为避免网络通信资源争用,不考虑分布式深度学习任务,可能错失相当多的合理共享机会,即共享不充分,导致未能更大程度地开发共享调度的潜力。
5、因此,现有技术还有待改进。
技术实现思路
1、本发明要解决的技术问题在于,针对现有技术缺陷,本发明提供一种多用户gpu集群的深度学习任务调度方法,以解决现有的深度学习任务调度方法导致的调度效率低的问题。
2、本发明解决技术问题所采用的技术方案如下:
3、第一方面,本发明提供多用户gpu集群的深度学习任务调度方法,包括:
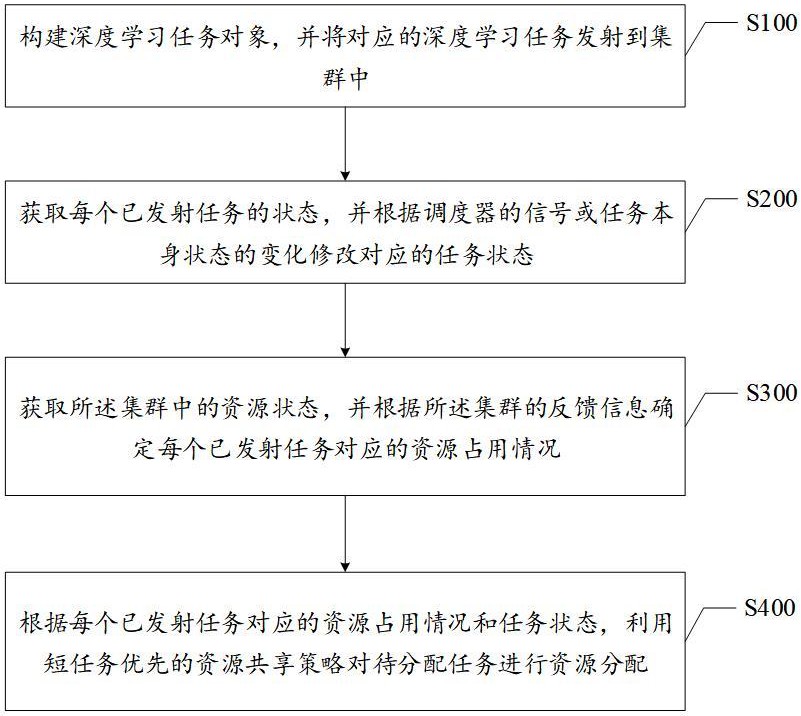
4、构建深度学习任务对象,并将对应的深度学习任务发射到集群中;
5、获取每个已发射任务的状态,并根据调度器的信号或任务本身状态的变化修改对应的任务状态;
6、获取所述集群中的资源状态,并根据所述集群的反馈信息确定每个已发射任务对应的资源占用情况;
7、根据每个已发射任务对应的资源占用情况和任务状态,利用短任务优先的资源共享策略对待分配任务进行资源分配。
8、在一种实现方式中,所述根据每个已发射任务对应的资源占用情况和任务状态,利用短任务优先的资源共享策略对待分配任务进行资源分配,包括:
9、根据每个已发射任务对应的资源占用情况和任务状态,利用共享任务完成用时估计方式计算与待分配任务的共享收益,并根据所述共享收益确定共享任务的候选列队;
10、根据计算得到的共享收益对所述共享任务的候选列队进行排序,并根据排序顺序,选择满足条件的独占任务与所述待分配任务进行资源共享。
11、在一种实现方式中,所述根据每个已发射任务对应的资源占用情况和任务状态,利用共享任务完成用时估计方式计算与待分配任务的共享收益,并根据所述共享收益确定共享任务的候选列队,包括:
12、计算当前集群中所有正在运行的独占任务及对应gpu占用数据;
13、根据所述独占任务及对应gpu占用数据、所述共享任务完成用时估计方式分别计算待分配任务与运行中各独占任务的共享预计任务完成用时;
14、将各共享预计任务完成用时与对应的任务不共享的总体任务完成用时进行对比;
15、若当前共享预计任务完成用时小于对应的任务不共享的总体任务完成用时,则将对应的运行中的独占任务加入候选队列。
16、在一种实现方式中,所述根据计算得到的共享收益对所述共享任务的候选列队进行排序,并根据排序顺序,选择满足条件的独占任务与所述待分配任务进行资源共享,包括:
17、根据所有的共享预计任务完成用时对所述候选列队中潜在共享任务进行升序排序;
18、选择当前候选队列的队首任务,判断所述当前候选队列的队首任务的独占gpu数量是否满足所述待分配任务的运行需求;
19、若所述当前候选队列的队首任务的独占gpu数量满足所述待分配任务的运行需求,则选择所述队首任务与所述待分配任务进行资源共享;
20、若所述当前候选队列的队首任务的独占gpu数量不满足所述待分配任务的运行需求,则选择下一轮的候选队列的队首任务,并判断当前队首任务与下一轮的队首任务累积的独占gpu数量是否满足所述待分配任务的运行需求;
21、若所述累积的独占gpu数量满足所述待分配任务的运行需求,则将累积独占式gpu分配给所述待分配任务。
22、在一种实现方式中,所述判断当前队首任务与下一轮的队首任务累积的独占gpu数量是否满足所述待分配任务的运行需求,之后还包括:
23、若下一轮之后的候选队列为空,且累积的独占gpu数量不满足所述待分配任务的运行需求,则将所述待分配任务挂起,直到满足所述待分配任务的运行需求。
24、在一种实现方式中,所述根据每个已发射任务对应的资源占用情况和任务状态,利用短任务优先的资源共享策略对待分配任务进行资源分配,之前还包括:
25、确定每个已发射任务对应的运行速率受到干扰的速度干扰因子,以及确定所述待分配任务对应的运行速率受到干扰的速度干扰因子;
26、根据确定的速度干扰因子对应计算每个已发射任务在共享时的时间倍率因子和所述待分配任务对应的在共享时的时间倍率因子;
27、根据计算的时间倍率因子和干扰前平均迭代时间,确定每个已发射任务与所述待分配任务确定共享任务完成用时估计方式。
28、在一种实现方式中,所述根据计算的时间倍率因子和干扰前平均迭代时间,确定每个已发射任务与所述待分配任务确定共享任务完成用时估计方式,包括:
29、根据计算的时间倍率因子和干扰前平均迭代时间,分别计算每个已发射任务对应的干扰后平均迭代时间和所述待分配任务对应的干扰后平均迭代时间;
30、将每个已发射任务的干扰后平均迭代时间与对应的迭代次数的乘积,与所述待分配任务的干扰后平均迭代时间与对应的迭代次数的乘积进行比对;
31、若当前已发射任务对应的乘积大于或等于所述待分配任务对应的乘积,则将所述共享任务完成用时估计方式确定为当前已发射任务立即与所述待分配任务进行资源共享的估计方式;
32、若当前已发射任务对应的乘积小于所述待分配任务对应的乘积,则将所述共享任务完成用时估计方式确定为当前已发射任务不与所述待分配任务进行资源共享的估计方式。
33、第二方面,本发明提供一种多用户gpu集群的深度学习任务调度装置,包括:
34、任务发射器模块,用于构建深度学习任务对象,并将对应的深度学习任务发射到集群中;
35、任务管理器模块,用于获取每个已发射任务的状态,并根据调度器的信号或任务本身状态的变化修改对应的任务状态;
36、资源管理器模块,用于获取所述集群中的资源状态,并根据所述集群的反馈信息确定每个已发射任务对应的资源占用情况;
37、调度器模块,用于根据每个已发射任务对应的资源占用情况和任务状态,利用短任务优先的资源共享策略对待分配任务进行资源分配。
38、第三方面,本发明提供一种终端,包括:处理器以及存储器,所述存储器存储有多用户gpu集群的深度学习任务调度程序,所述多用户gpu集群的深度学习任务调度程序被所述处理器执行时用于实现如第一方面所述的多用户gpu集群的深度学习任务调度方法的操作。
39、第四方面,本发明还提供一种介质,所述介质为计算机可读存储介质,所述介质存储有多用户gpu集群的深度学习任务调度程序,所述多用户gpu集群的深度学习任务调度程序被处理器执行时用于实现如第一方面所述的多用户gpu集群的深度学习任务调度方法的操作。
40、本发明采用上述技术方案具有以下效果:
41、本发明将深度学习任务发射到集群中后,通过获取每个已发射任务的状态,可根据调度器的信号或任务本身状态的变化修改对应的任务状态;以及通过获取集群中的资源状态,可根据集群的反馈信息确定每个已发射任务对应的资源占用情况,从而根据每个已发射任务对应的资源占用情况和任务状态,利用短任务优先的资源共享策略对待分配任务进行资源分配;本发明依靠短任务优先的资源共享策略,在缓解任务资源饥饿问题的同时,降低了整体的任务完成时间,提高了深度学习任务的调度效率。
- 还没有人留言评论。精彩留言会获得点赞!