文本处理方法、装置、产品、设备和介质与流程
本技术涉及文本处理的,尤其涉及一种文本处理方法、装置、产品、设备和介质。
背景技术:
1、在人工智能领域中,可以对文本生成其相应的特征向量,以便于通过各个文本的特征向量实现文本之间的检索。现有应用中,可以采用预训练得到的自然语言模型来对文本中的各个词进行嵌入处理,以生成文本的特征向量,但是在该过程中,预训练得到的自然语言模型重点关注到的是文本中的各个独立的词,而对词与词之间的联系则并不关注,导致自然语言模型对文本所生成的特征向量并不能很好地体现文本整体的语义信息。因此,如何更为有效地实现对自然语言模型的训练,从而通过训练得到的自然语言模型准确地生成文本的特征向量,是一个亟待解决的问题。
技术实现思路
1、本技术提供了一种文本处理方法、装置、产品、设备和介质,可提高通过人机交互解决用户问题的准确性。
2、本技术一方面提供了一种文本处理方法,该方法包括:
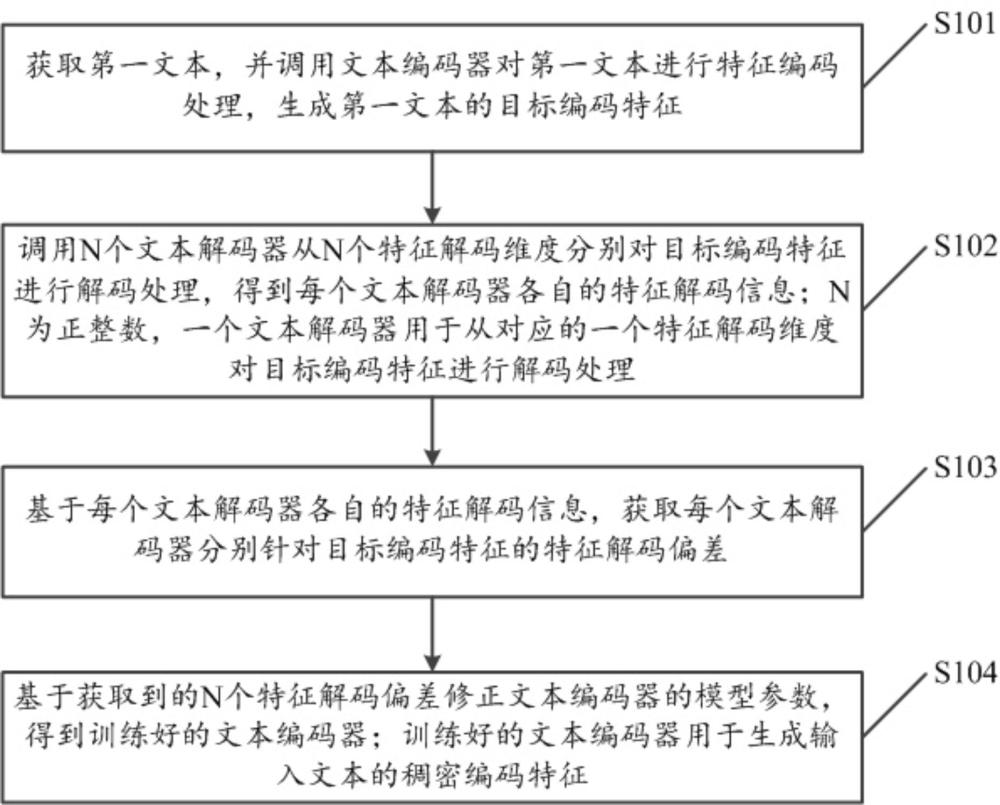
3、获取第一文本,并调用文本编码器对第一文本进行特征编码处理,生成第一文本的目标编码特征;
4、调用n个文本解码器从n个特征解码维度分别对目标编码特征进行解码处理,得到每个文本解码器各自的特征解码信息;n为正整数,一个文本解码器用于从对应的一个特征解码维度对目标编码特征进行解码处理;
5、基于每个文本解码器各自的特征解码信息,获取每个文本解码器分别针对目标编码特征的特征解码偏差;
6、基于获得到的n个特征解码偏差修正文本编码器的模型参数,得到训练好的文本编码器;训练好的文本编码器用于生成输入文本的稠密编码特征。
7、本技术一方面提供了一种文本处理装置,该装置包括:
8、编码模块,用于获取第一文本,并调用文本编码器对第一文本进行特征编码处理,生成第一文本的目标编码特征;
9、解码模块,用于调用n个文本解码器从n个特征解码维度分别对目标编码特征进行解码处理,得到每个文本解码器各自的特征解码信息;n为正整数,一个文本解码器用于从对应的一个特征解码维度对目标编码特征进行解码处理;
10、获取模块,用于基于每个文本解码器各自的特征解码信息,获取每个文本解码器分别针对目标编码特征的特征解码偏差;
11、训练模块,用于基于获得到的n个特征解码偏差修正文本编码器的模型参数,得到训练好的文本编码器;训练好的文本编码器用于生成输入文本的稠密编码特征。
12、可选的,第一文本是采用第一掩码比例对原始文本进行掩码处理后得到的,n个文本解码器包括文本重建解码器;解码模块调用n个文本解码器从n个特征解码维度分别对目标编码特征进行解码处理,得到每个文本解码器各自的特征解码信息的方式,包括:
13、获取第二文本;第二文本是采用第二掩码比例对原始文本进行掩码处理后得到的,第二掩码比例大于第一掩码比例,第二文本包含对原始文本中第二掩码比例的局部文本进行掩码替换后得到的第二掩码文本;
14、调用文本重建解码器基于目标编码特征和第二文本,对第二掩码文本进行重建处理,生成第二掩码文本针对第二对照文本的重建概率;第二对照文本是原始文本中第二掩码文本对应的局部文本;
15、将第二掩码文本针对第二对照文本的重建概率,确定为文本重建解码器的特征解码信息。
16、可选的,第二掩码文本和第二对照文本均包含一个或多个字符,第二掩码文本中的每个字符与第二对照文本中的每个字符一一对应,第二掩码文本中的一个字符针对第二对照文本中的对应字符具有一个重建概率;
17、获取模块基于每个文本解码器各自的特征解码信息,获取每个文本解码器分别针对目标编码特征的特征解码偏差的方式,包括:
18、基于第二掩码文本中的每个字符分别针对第二对照文本中对应字符的重建概率,生成第二掩码文本中每个字符分别对应的特征解码子偏差;
19、对第二掩码文本中的每个字符分别对应的特征解码子偏差进行加和处理,生成文本重建解码器针对目标编码特征的特征解码偏差。
20、可选的,第一文本是对原始文本进行掩码处理后得到的,n个文本解码器包括摘要预测解码器;
21、解码模块调用n个文本解码器从n个特征解码维度分别对目标编码特征进行解码处理,得到每个文本解码器各自的特征解码信息的方式,包括:
22、获取原始文本的摘要文本;
23、将摘要文本和目标编码特征输入摘要预测解码器;
24、调用摘要预测解码器基于目标编码特征和摘要文本进行摘要预测处理,生成摘要预测解码器对摘要文本中的每个字符的预测概率;
25、将摘要文本中每个字符对应的预测概率,确定为摘要预测解码器的特征解码信息。
26、可选的,获取模块基于每个文本解码器各自的特征解码信息,获取每个文本解码器分别针对目标编码特征的特征解码偏差的方式,包括:
27、基于摘要文本中每个字符对应的预测概率,分别生成摘要文本中每个字符对应的特征解码子偏差;
28、对摘要文本中每个字符对应的特征解码子偏差进行加和处理,生成摘要预测解码器针对目标编码特征的特征解码偏差。
29、可选的,编码模块获取第一文本的方式,包括:
30、获取原始文本以及针对原始文本的第一掩码比例;
31、采用第一掩码比例对原始文本进行掩码处理,生成第一文本;
32、其中,第一文本包含对原始文本中第一掩码比例的局部文本进行掩码替换后得到的第一掩码文本。
33、可选的,上述编码模块还用于:
34、调用文本编码器基于第一文本,对第一掩码文本进行重建处理,生成第一掩码文本针对第一对照文本的重建概率;第一对照文本是原始文本中第一掩码文本对应的局部文本;
35、基于第一掩码文本针对第一对照文本的重建概率,获取文本编码器的第一文本重建偏差。
36、可选的,训练模块基于获取到的n个特征解码偏差修正文本编码器的模型参数,得到训练好的文本编码器的方式,包括:
37、对第一文本重建偏差以及n个特征解码偏差进行叠加处理,生成目标训练偏差;
38、基于目标训练偏差修正文本编码器的模型参数,得到训练好的文本编码器。
39、可选的,训练模块对第一文本重建偏差以及n个特征解码偏差进行叠加处理,生成目标训练偏差的方式,包括:
40、获取每个文本解码器分别针对文本编码器的辅助训练系数;
41、采用每个文本解码器针对文本编码器的辅助训练系数,分别对每个文本解码器针对目标编码特征的特征解码偏差进行加权运算处理,生成每个文本解码器各自针对文本编码器的辅助训练偏差;
42、对第一文本重建偏差以及n个文本解码器针对文本编码器的n个辅助训练偏差进行加和处理,生成目标训练偏差。
43、可选的,上述文本处理装置还包括预训练模块,该预训练模块用于:
44、获取通用文本集和初始文本编码器;通用文本集中包含多个通用领域下的m个通用文本;m为正整数;
45、对通用文本集中的每个通用文本分别进行掩码处理,生成m个掩码处理后的通用文本;一个掩码处理后的通用文本包含对对应通用文本中的局部文本进行掩码替换后得到的一个通用掩码文本;
46、调用初始文本编码器基于每个掩码处理后的通用文本,对所包含的通用掩码文本进行重建处理,生成每个通用掩码文本针对对应通用对照文本的重建概率;一个通用掩码文本对应的通用对照文本为该通用掩码文本在对应的通用文本中原始的局部文本;
47、基于每个通用掩码文本针对对应通用对照文本的重建概率,生成初始文本编码器的第二文本重建偏差;
48、基于第二文本重建偏差修正初始文本编码器的模型参数,得到文本编码器。
49、可选的,上述文本处理装置还包括问答模块,该问答模块用于:
50、获取答复文本集;答复文本集包含问答领域中的多个答复文本;
51、调用训练好的文本编码器,对答复文本集中的每个答复文本进行特征编码处理,生成每个答复文本各自的稠密编码特征;
52、基于每个答复文本各自的稠密编码特征,构建编码特征集。
53、可选的,上述问答模块还用于:
54、获取问答客户端发送的询问文本,并调用训练好的文本编码器对询问文本进行特征编码处理,生成询问文本的稠密编码特征;
55、获取询问文本的稠密编码特征分别与编码特征集中的每个稠密编码特征之间的特征相似度;
56、基于询问文本的稠密编码特征分别与编码特征集中的每个稠密编码特征之间的特征相似度,从编码特征集中选取答复编码特征;
57、将答复编码特征所属的答复文本,作为询问文本的答复文本,并将询问文本的答复文本返回至问答客户端,使问答客户端输出询问文本的答复文本。
58、可选的,问答模块基于询问文本的稠密编码特征分别与编码特征集中的每个稠密编码特征之间的特征相似度,从编码特征集中选取答复编码特征的方式,包括:
59、按照询问文本的稠密编码特征与编码特征集中的每个稠密编码特征之间的特征相似度的由大到小的顺序,对编码特征集中的稠密编码特征进行排序处理,得到排序后的稠密编码特征;
60、将排序后的稠密编码特征中的前k个稠密编码特征,作为答复编码特征;k为正整数。
61、可选的,问答模块基于询问文本的稠密编码特征分别与编码特征集中的每个稠密编码特征之间的特征相似度,从编码特征集中选取答复编码特征的方式,包括:
62、获取针对稠密编码特征之间的特征相似度的相似度参考值;
63、将编码特征集中与询问文本的稠密编码特征之间的特征相似度大于或等于相似度参考值的稠密编码特征,作为答复编码特征。
64、本技术一方面提供了一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,计算机程序被处理器执行时,使得处理器执行本技术中一方面中的方法。
65、本技术一方面提供了一种计算机可读存储介质,该计算机可读存储介质存储有计算机程序,该计算机程序被处理器执行时使该处理器执行上述一方面中的方法。
66、根据本技术的一个方面,提供了一种计算机程序产品,该计算机程序产品包括计算机程序,该计算机程序存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机程序,处理器执行该计算机程序,使得该计算机设备执行上述一方面等各种可选方式中提供的方法。
67、本技术可以获取第一文本,并调用文本编码器对第一文本进行特征编码处理,生成第一文本的目标编码特征;还可以调用n个文本解码器从n个特征解码维度分别对目标编码特征进行解码处理,得到每个文本解码器各自的特征解码信息;n为正整数,一个文本解码器用于从对应的一个特征解码维度对目标编码特征进行解码处理;以及,可以基于每个文本解码器各自的特征解码信息,获取每个文本解码器分别针对目标编码特征的特征解码偏差;从而,可以基于获取到的n个特征解码偏差修正文本编码器的模型参数,得到训练好的文本编码器;训练好的文本编码器用于生成输入文本的稠密编码特征。由此可见,本技术提出的方法可以采用多个文本解码器,对文本编码器生成的编码特征(如目标编码特征)进行不同特征解码维度上的解码处理,以生成各个文本解码器在各自的特征解码维度下的特征解码偏差,从而,可以通过该多个文本解码器在多个特征解码维度下的特征解码偏差,来实现对文本编码器的辅助和增强训练,使得文本编码器的模型参数也可以在该多个特征解码维度下得到更为丰富且有效的优化,因此,提升了对文本编码器的训练效果,采用训练得到的文本编码器也可以对输入文本生成更为准确的编码特征。
- 还没有人留言评论。精彩留言会获得点赞!