基于视觉语义融合的可控缺陷图像生成方法及设备
本发明涉及人工智能领域,具体涉及一种基于视觉语义融合的可控缺陷图像生成方法及设备。
背景技术:
1、在工业生产环境中,为了保证产品的质量与良品率,表面缺陷检测尤为重要。而训练表面缺陷检测网络需要大量的缺陷图像数据。而在现实环境下,要想得到大量高质量且多样化的缺陷图像通常费时费力。
2、随着卷积神经网络的发展,基于深度学习的方法已被广泛应用于缺陷图像生成,借用神经网络强大的拟合能力,这些方法取得了较好的成果。现有基于深度学习的缺陷图像生成技术大多采用生成对抗网络(generative adversarial network, gan)与扩散模型(diffusion model)来进行缺陷生成。虽然上述两种模型也能生成质量不错的缺陷图像。但基于这两种技术的缺陷图像生成方法存在以下三个问题:
3、1)需要人为地对数据样本进行标注,这个过程费时费力;
4、2)对于每个缺陷图像来说,都需要没有缺陷的正样本进行配对训练;
5、3)生成的缺陷图像不可控,不能针对性地生成想要的数据。
技术实现思路
1、为了克服现有技术的缺陷,本发明设计了基于视觉语义融合的可控缺陷图像生成方法及设备,利用大语言模型对文字描述进行数据标注,从已有数据集中生成新的数据集,并能够生成出可控且多样化的缺陷图像,以解决在训练表面缺陷检测网络时遇到的缺乏数据的问题。
2、本发明所设计的基于视觉语义融合的可控缺陷图像生成方法,包括以下步骤:
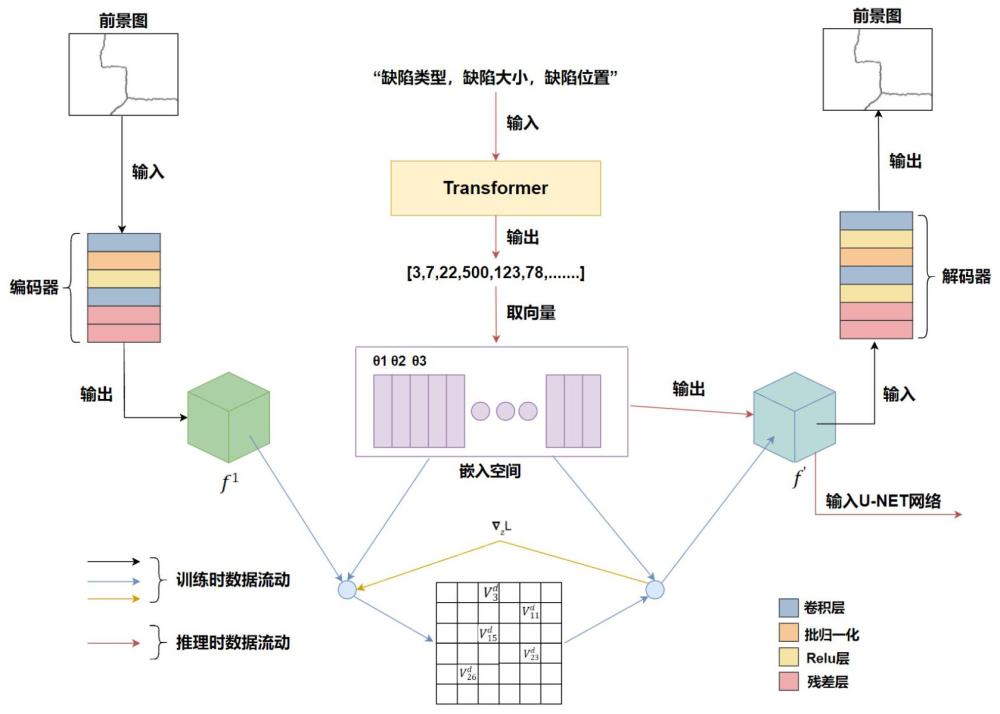
3、数据准备,获取缺陷图像的缺陷文字描述并分割出缺陷前景图,利用算法修复缺陷图像得到背景图;
4、构建缺陷生成模型,该模型包括量子化变分自编码器网络、transformer网络和u-net网络,其中,量子化变分自编码器网络包括编码器、解码器和向量嵌入空间;所述缺陷生成网络生成可控缺陷图像的过程如下:
5、将文字描述输入已训练好的transformer网络,输出一个索引串,利用索引串到已训练好的嵌入空间中进行采样得到缺陷前景图的特征图;背景图输入已训练好的编码器中,得到背景图的特征图,将缺陷前景图和背景图的特征图与对应文字描述一同输入训练好的u-net网络,输出缺陷图像;
6、训练缺陷生成模型,具体包括:
7、利用缺陷前景图对量子化变分自编码器网络进行训练;
8、利用训练好的量子化变分自编码器网络中向量嵌入空间得到每张缺陷前景图对应的向量,把这种对应关系与所述文字描述配对制作成数据集b;将所述缺陷图像,对应的背景图和缺陷前景图利用编码器编码得到配对的三元组特征,该三元组特征构成数据集c;
9、利用数据集b对transformer网络进行训练;
10、利用数据集c与对应文字描述对u-net网络进行训练。
11、进一步地,采用chatgpt大语言模型对缺陷图像的缺陷进行文字描述,文字描述包括缺陷类型、缺陷大小和缺陷位置。采用特殊的文字描述:“缺陷类型,缺陷大小,缺陷位置”,并通过chatgpt大语言模型批量生产这种文字描述,省去了标注缺陷图像所要耗费的大量人力和精力。
12、进一步地,分割缺陷前景图采用grabcut技术结合缺陷图像的掩膜进行缺陷前景图分割,或采用loosecut进行缺陷前景图分割。
13、进一步地,缺陷修复算法包括criminis图像修复算法、pd-gan图像修复算法或者df-net图像修复算法。
14、进一步地,量子化变分自编码器网络的训练具体如下:
15、将缺陷前景图x输入编码器中得到特征图,代表特征图中的第i个特征向量,再利用最近邻算法替换中所有的:
16、=, k=
17、其中j代表访问嵌入空间时使用的索引,代表嵌入空间中索引值为k的特征向量,代表在完成最近邻搜索后所得到的结果,利用得到的所有重建出特征图,记为,再将传入解码器,重建出缺陷前景图;使用“停止梯度”(sg)运算完成梯度的复制:
18、sg(x)=
19、则,从到的重建损失函数为:
20、=
21、解码器d;再次利用停止梯度运算,得到损失函数:
22、=+
23、其中与是设置的参数,用以控制相对学习速度;故量子化变分自编码器网络的总体损失函数为:
24、 l=+
25、利用adam优化器在上述定义好的损失函数上进行梯度下降,待损失趋于稳定时便得到训练好的编码器,向量嵌入空间和解码器。
26、进一步地,transformer网络的训练包括以下步骤:
27、构造分词器处理文字描述,并使用交叉熵损失函数作为优化目标:
28、=
29、其中表示取数据集b中真实的索引串, m表示索引串编号,()表示通过transformer预测出来的索引串,同时使用adam优化器,并设置好学习率。
30、进一步地,u-net网络包括下采样、瓶颈层和上采样;下采样用于捕获输入张量的内容信息,提取特征,输入张量经下采样层被输出为尺寸小但维度高的特征图,被传入瓶颈层,进行特征压缩后进行上采样,上采样恢复张量的尺寸并降低维度;
31、下采样通过卷积层、gelu激活函数和归一化的组合增加网络的非线性特性和学习能力,各个网络层次中使用自注意力层,处理文字嵌入,并多次进行残差连接;
32、瓶颈层,继续进行卷积操作,增加网络的深度和复杂度,同时保留更多的空间信息;
33、上采样通过转置卷积将特征图尺寸恢复到原始尺寸,使用跳跃连接将下采样时对应的特征图和上采样时的特征图进行连接,帮助信息传递和梯度流动,在通过卷积层、gelu激活函数和归一化的组合继续学习特征。
34、更进一步地,u-net网络的训练具体如下:
35、取数据集c中的缺陷前景图的特征图、背景图的特征图,缺陷图像的特征图,再取数据对应的文字描述(prompt),传入到已经训练好的transformer的编码器,得到文字嵌入s:
36、s =
37、将、、s传入u-net中,输出对于与融合后的特征图的预测,计算与的均方损失:
38、mseloss =
39、其中表示缺陷图像之中的一个特征向量,表示之中的一个特征向量, n表示特征向量的总数,同时使用adam优化器,并设置好学习率。
40、基于同一发明构思,本方案还设计了一种电子设备,包括:
41、一个或多个处理器;
42、存储装置,用于存储一个或多个程序;
43、当一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现基于视觉语义融合的可控缺陷图像生成方法。
44、基于同一发明构思,本方案还设计了一种计算机可读介质,其上存储有计算机程序,其特征在于:所述程序被处理器执行时实现基于视觉语义融合的可控缺陷图像生成方法。
45、本发明的优点在于:
46、1、创新性地设计了文字描述,省去了标注缺陷图像所要耗费的大量人力和精力。并且使得transformer能够更容易学到这种文字描述跟向量嵌入空间中索引的映射关系。
47、2、创新地设计了一种通过文字描述从离散的向量嵌入空间中采样的机制。传统的方法一直无法方便快捷地从离散的嵌入空间中进行采样。但我们的方法能够通过transformer接收给定的文字预测出要生成的前景图所需要的索引串,并构建出这个前景图的特征图。实现了通过文字描述采样向量嵌入空间得到有意义的特征图的机制。
48、3、设计了一种从已有数据集中生成新的数据集的机制。通过最初的数据集训练好量子化变分自编码器网络的编码器后,再利用此网络得出文字描述-索引串的配对数据集b对transformer进行训练,同时也利用此网络得出“前景图的特征图-背景的特征图-原图的特征图”三元组配对数据集c对u-net进行训练。
49、4、通过u-net网络对特征图进行融合,创新性地使用了u-net在背景图上生成缺陷。
- 还没有人留言评论。精彩留言会获得点赞!