一种耦合降维理论的水文丰枯遭遇概率计算方法与流程
本发明属于水文模型计算,具体涉及一种耦合降维理论的水文丰枯遭遇概率计算方法。
背景技术:
1、不同流域或同一流域不同区域间的水文遭遇概率计算,对流域间洪旱灾害联合防御方案的制定和水网工程建设具有重要的意义,例如丰水遭遇概率过大将会制约着流域间的联合防洪调度。对于水网工程而言,若供水区和受水区枯水遭遇概率过大,则不利于跨流域调水的运行。受全球气候变化和人类活动的共同影响,流域水文过程一致性遭受破坏,流域间水文丰枯遭遇的频度和强度更趋复杂。
2、当前,水文非一致性条件下的水文丰枯遭遇概率分析已经形成了以耦合广义可加模型(gamlss)和copula函数为代表的多维联合分布模拟方法,其中广义可加模型(gamlss)用以获得边缘分布函数。但该方法仍存在以下缺陷:一是该方法目前仍是以优选某种频率分布模型(例如p-ⅲ分布)的方式估计水文变量的频率分布特征,在分布模型的选择上虽然避免了一定的主观盲目性,但精度还有待提升。二是该方法往往以单一或某几个指标(时间t、降雨量p以及气温t等)作为解释变量,在解释变量的选择中未能综合考虑气候变化和人类活动的作用。然而,气候和人类活动指标又是复杂多样的,如果考虑全部的指标作为解释变量,则会出现维数灾,甚至导致模型无法运行,因此急需采用科学高效的降维方法获取反映气候和人类活动影响的解释变量。综上,对于变化环境下的水文遭遇概率分析,需要在提高计算精度的同时保持对气候和人类活动影响的充分考量。
技术实现思路
1、本发明为了解决现有方法精度不高、未能综合考虑气候变化和人类活动的作用、传统gamlss模型分析解释变量维数灾的问题,而提供一种能充分反映气候变化和人类活动影响的水文丰枯遭遇计算方法,能实现变化环境背景下高精度水文丰枯遭遇的计算。
2、本发明具体采用以下技术方案:
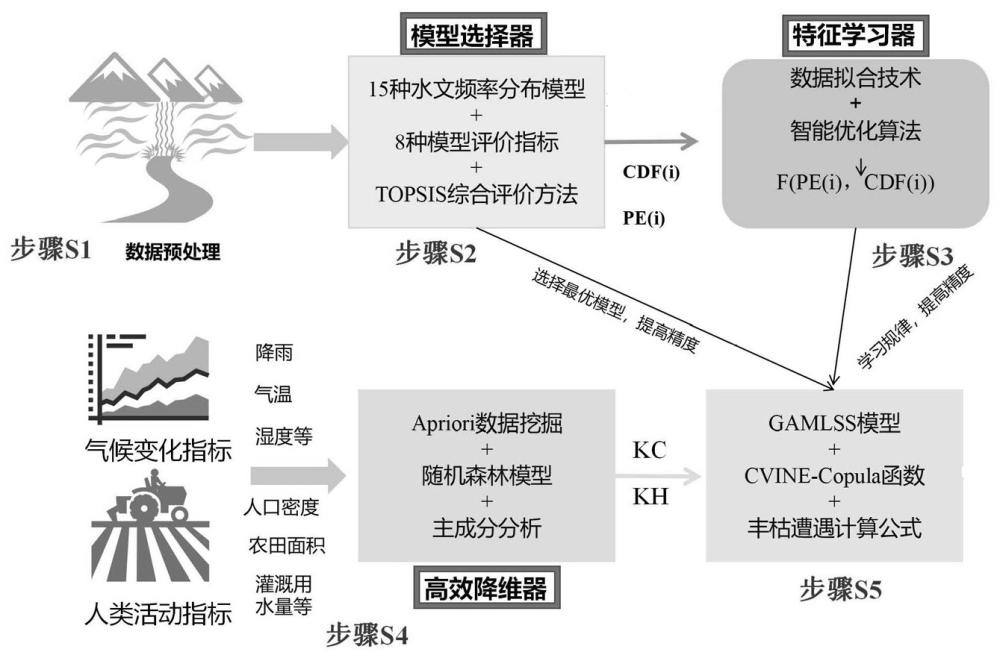
3、一种耦合降维理论的水文丰枯遭遇概率计算方法,具体包括以下步骤:
4、步骤s1:获取研究区气候指标数据、水文指标数据和人类活动指标数据,并进行数据预处理,包括质量控制、噪声去除、插补延长等;
5、步骤s2:基于水文指标数据,采用分布模型选择器选择研究区边缘分布的最优分布模型;
6、步骤s3:将最优分布模型计算得到的累积分布函数cdf( i)和累积经验频率pe( i)加载进特征学习器中,通过特征学习器获得累积分布函数和累积经验频率的关系函数f(pe( i),cdf( i));其中, i代表频率分布模型的个数;
7、步骤s4:将气候指标和人类活动指标加载进高效降维器进行降维处理,得到降维后的综合气候指标kc和综合人类活动指标kh;
8、步骤s5:将综合气候指标kc和综合人类活动指标kh作为最终解释变量,采用gamlss模型分析各边缘分布在考虑变化环境影响后的累积分布函数cdf_cho( i),然后将cdf_cho( i)代入步骤s3对应的关系函数f(pe( i),cdf( i)),获得最终的水文气候变量边缘分布的累积分布函数cdf_ch( i);最后基于获得的cdf_ch( i),采用copula函数方法计算得到丰枯遭遇概率。
9、进一步地,所述步骤s1中数据预处理包括:
10、对气候数据、水文数据和人类活动指标数据,进行缺失值检验、一致性检验和白噪声处理。针对存在缺失数据的情况,对数据进行插补延长。仅有个别数据缺失则采用相邻时间取均值法进行插补,当缺失数据较多时采用水文比拟法和sdsm统计降尺度模型对其进行插补。
11、进一步地,所述步骤s2包括:
12、步骤s2.1:首先在分布模型选择器中采用多种水文频率分布模型对径流序列进行单变量的频率分布拟合。选用的频率分布模型包括10种两参数模型和5种三参数模型;两参数模型包括ga、gu、ig、lo、logno、no、rg、wei、wei2和wei3;三参数模型包括gg、bccg、gig、pe和p-ⅲ。以上15种模型是现有技术,其名称也为现有技术,在此不再对模型缩写名称进行一一解释。
13、本发明中将用于实现分布模型优选的所有方法技术集合命名为分布模型选择器,即本发明分布模型选择器包括十种两参数模型和五种三参数模型。
14、步骤s2.2:基于15种频率分布拟合的结果,采用global deviance、aic、sbc、残差均值指数mean、残差方差指数variance、残差filliben系数、残差偏态系数skewness和残差峰态系数kurtosis 8个评价指标对各频率分布模型进行精度评价。其中global deviance、aic和sbc的值越小,mean和skewness越接近于0,variance和filliben 越接近于1,kurtosis越接近于3,模型的模拟精度越好。若各评价指标的结论一致,则可优选出最佳频率分布模型;若各评价指标结论不一致则进一步进行最终模型优选。
15、步骤s2.3:为了解决步骤2.2中可能存在的多个指标评价时无法有效优选最优结果的问题(例如:部分指标表示模型1最优,而另一部分评价指标则认为模型2为最优),采用基于熵权的topsis综合评价方法进行模型结果的最终优选:
16、
17、,且满足
18、
19、
20、
21、式中,为第 i个频率分布模型第 j项评价指标归一化值, m为模型总数, n为评价指标种类数, r ij表征第 i个频率分布模型的第 j项评价指标所占的比重; s j为第 j项指标的熵值;则为第 j项指标所占的权重,为第 j项指标的理想解,为第 j项指标的负理想解,为各指标与理想解的距离,为各指标与负理想解的距离, c为最终模型评价参数, c值越大模型越优, q j为第 j项指标值。
22、进一步地,步骤s3中特征学习器包含了多种特征函数,用于学习累积分布函数和累积经验频率之间的关系,根据学习效果选择最终的特征函数形式。
23、进一步地,步骤s3中特征学习器包含了五种特征函数,设累积分布函数和累积经验频率分别为x和y,则五种函数形式分别为:
24、指数函数: y=ae bx
25、线性函数: y= ax+ b
26、对数函数: y= aln x+ b
27、多项式函数,以二次函数为例: y= ax2+ bx+ c
28、幂函数: y= ax b
29、其中,参数 a、 b、 c通过人工智能优化算法进行确定,人工智能优化算法包括但不限于遗传算法、粒子群算法或神经网络。
30、进一步地,所述步骤s3具体包括:
31、步骤s3.1;提取出最优分布模型计算得到的累积分布函数cdf( i),并将累积分布函数与累积经验频率pe( i)组成学习对(pe( i),cdf( i));
32、步骤s3.2:将各组学习对组合加载进特征学习器中进行学习,通过特征学习器获得cdf( i)和pe( i)的关系函数f(pe( i),cdf( i))。
33、本发明通过五种特征函数对累积分布函数和累积经验频率之间的关系进行数据拟合,为了方便描述,本发明将用于学习累积分布函数和累积经验频率间关系规律的方法集合命名为特征学习器,即本发明的特征学习器包含了五种特征函数。
34、本发明将多维的各气候和人类活动指标降维至两个维度的综合指标的方法技术集合命名为高效降维器,即本发明中高效降维器包含了apriori数据挖掘算法、随机森林模型和主成分分析方法。
35、进一步地,所述步骤s4包括:
36、步骤s4.1:在高效降维器中首先采用apriori数据挖掘算法对步骤s1预处理过的气候数据和人类活动指标数据进行初步筛选,去除不重要或者不显著的影响因子。
37、apriori数据挖掘算法用于寻找存在于水文要素集合与气候或人类活动指标要素集合之间的频繁模式、关联、相关性或因果结构,属于无监督学习。由于apriori数据挖掘算法中需要数据分类属性数据形式,因此采用k-means聚类算法对原始数据进行分类,构建分类属性数据集。
38、以径流量数据为例,将收集到的径流量表示为一个数据集r,从数据集r中随机选取k个径流量值作为拟划分的k个聚类中心,分别计算任意径流值与任意聚类中心之间的欧式距离。根据欧式距离最小原则,将径流值划分为k类。将划分得到的k类所有径流值取平均,并令其为新的聚类中心,重复操作,直到相邻迭代两次计算的聚类中心值不再发生变化,即获得最终分类结果。
39、计算欧式距离的方法是现有技术,在此不再赘述。
40、完成分类属性数据集构建后,分别计算气候指标、人类活动指标与径流要素的关联规则,并分析关联规则的支持度和置信度。根据关联规则支持度和置信度计算结果,剔除不满足支持度和置信度阈值的气候指标和人类活动指标。最终可从备选的所有气候指标和人类活动指标中选择对水文具有显著影响的要素指标,称之为有效气候影响因素集和有效人类活动影响因素集。
41、支持度和置信度的形式和计算方法属于现有技术,在此不再赘述。
42、步骤s4.2:基于有效气候影响因素集和有效人类活动影响因素集结果,采用随机森林模型,对各影响因素集中各影响要素的重要性进行分析,并按照重要性进行排序。重要性分析的结果将用于确定各影响要素在综合气候指标kc和综合人类活动指标kh计算时的权重。
43、步骤s4.3:采用耦合信息熵的主成分分析方法,构建综合气候指标和综合人类活动指标。以综合气候指标kc为例,耦合信息熵的主成分分析方法步骤如下:
44、①计算各气候影响因素相关系数矩阵
45、
46、式中, cl rs是第 r个气候影响因素和第 s个气候影响因素的相关系数, r=1,2,…, k; s=1,2,…, k ; cl rs= cl sr。
47、②解特征方程得特征值,并降序排列,进而推求对应的特征向量 e cl,r。
48、③计算主成分贡献率为:
49、计算主成分累计贡献率:
50、式中, p为满足累积贡献率大于阈值的特征数,为第 p项的特征值。
51、④计算主成分荷载:其中, e cl,r,s是向量 e cl,r的第 s个分量。
52、⑤ 确定各气候影响因素变量的最终权重。根据各气候影响因素变量指标在各主成分的线性组合系数以及主成分的方差贡献率,并结合步骤42随机森林重要性排序结果可求出其权重 w cl,r。
53、⑥计算气候变化指标;对选取的各代表气候变量进行归一化以避免量纲不统一的问题,然后求取气候变化指标(归一化)如下:
54、
55、式中, kc为最终求取的标准化后的气候变化指标; cc r为第 r个气候影响因素变量, w cl,r第 r个气候影响因素变量对应的权重。
56、进一步地,所述步骤s5包括:
57、步骤s5.1:将步骤s4对应的kc和kh作为最终解释变量,采用最优分布模型分析各边缘分布在考虑变化环境影响后的累积分布函数cdf_cho( i);
58、步骤s5.2:将cdf_cho( i)代入步骤s3对应的关系函数f(pe( i),cdf( i)),获得最终的水文气候变量边缘分布的累积分布函数cdf_ch(i);假设关系函数为线性函数,则具体公式如下:
59、cdf_ch( i)=cdf_cho( i)*a+b
60、步骤s5.3:基于获得的cdf_ch( i),采用copula函数方法计算得到联合分布概率。
61、步骤s5.4:丰枯遭遇计算。我国丰枯等级划分相对应的频率为 p f =37.5%和 p k = 62.5%(不超过概率),本方法中设两个水文时间序列分别为x和 y,其边缘分布函数分别为 u、 v,则 y pf为水文时间序列y中 p f频率对应的水量, y pk为水文时间序列y中 p k频率对应的水量, x pf 为水文时间序列x中 p f频率对应的水量, x pk 为水文时间序列x中 p k频率对应的水量。以水文时间序列x为例,则 x t ≥x pf为丰水、 x t ≤x pk为枯水、 x pk <x t <x pf为平水,其中 x t为第 t年的水文量。则:
62、x和 y同丰 (丰丰型) 的概率为:
63、
64、x和 y同平 (平平型) 的概率为:
65、
66、x和 y 同枯 (枯枯型) 的概率为:
67、
68、x丰y平 (丰平型) 的概率为:
69、
70、x平y丰(平丰型) 的概率为:
71、
72、x丰y枯(丰枯型) 的概率为:
73、
74、x枯y丰 (枯丰型) 的概率为:
75、
76、x平y枯 (平枯型) 的概率为:
77、
78、x枯y平 (枯平型) 的概率为:
79、
80、式中, u pf 、v pf 、 u pk 、 v pk 分别为 x pf 、y pf 、x pk 、y pk所对应的边缘分布函数值, c( ) 为copula连接函数。
81、本发明的有益效果:
82、1、本发明耦合分布模型选择器和特征学习器能显著提高水资源丰枯遭遇概率的计算精度,充分解决了变化环境下水文频率精度不佳、解释变量中对气候和人类活动因子考虑不足的问题。
83、2、本发明充分考虑了气候变化和人类活动对水文的影响,通过高效降维方法,解决了传统gamlss模型分析解释变量维数灾的问题,提升了对变化环境背景下的水文丰枯遭遇分析精度与效率。
- 还没有人留言评论。精彩留言会获得点赞!