一种基于双组件二阶聚合与重优化分类器部分的联邦学习方法、装置及计算机可读存储介质
本发明属于联邦学习的,更具体地,涉及一种基于双组件二阶聚合与重优化分类器部分的联邦学习方法、装置及计算机可读存储介质。
背景技术:
1、随着人工智能与机器学习技术的迅猛发展,以及物联网大数据时代的到来,生活中出现了大量的数据,这些数据蕴含着极为丰富的信息。对这些数据安全可靠共享,以促进医疗、金融、科学等领域的学术研究与技术创新成为当下人工智能领域的迫切需求。然而,这些数据可能包含着一些极其敏感的隐私信息,如果直接对其进行传输利用可能会导致隐私泄露问题。
2、中国发明专利cn116579443a公开了一种面向数据异构性的个性化联邦学习方法及存储介质,该发明仅需每个客户端公开其本地个性化模型的模型分类器部分梯度信息,能够缓解隐私泄露的问题,同时基于模型分类器部分梯度信息进行聚类可以更精确地识别出具有相似数据分布的客户端,降低计算代价,通过具有比全局模型更有价值的聚合模型构造客户端的本地优化目标,可以使客户端获得具有更好的泛化性能和具有收敛性的个性化模型。
3、针对异构数据下的联邦学习成为了备受关注且值得深入探讨的研究问题,当前,一些方法尝试通过在本地训练或全局聚合过程中引入惩罚项,来约束模型更新的幅度,以此应对异构数据的挑战,然而,这些方法在面对高度异构的数据时,对模型性能的提升效果有限。还有一些方法基于个性化联邦学习进行研究,即在本地客户端接收全局模型后,再根据本地数据集对模型进行微调,从而为每个客户端定制特有的模型,但这类方法训练出的模型容易出现过拟合现象,即模型过度适应当前数据集的特征,从而失去了泛化能力。
技术实现思路
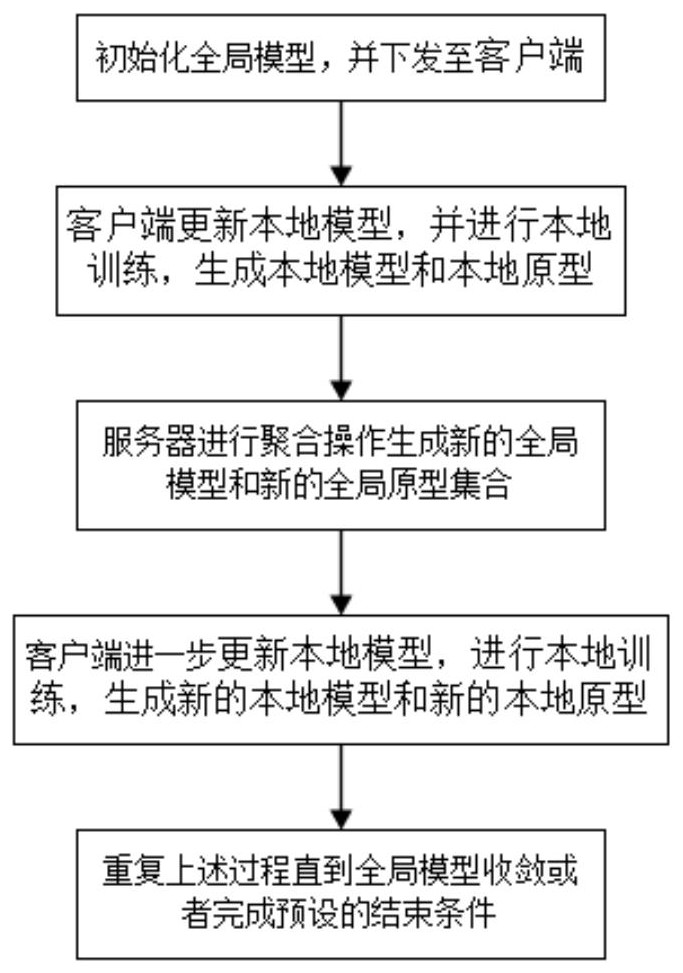
1、s1、在服务器方生成随机初始化全局模型,并将其下发给参与训练的个客户端;
2、s2、在每个参与训练的客户端上进行更新,即将初始化全局模型作为各客户端本地模型;再进行本地模型的训练,并在训练完成后生成客户端的本地原型集合,再将训练后的本地模型与生成的本地原型集合上传到服务器;
3、s3、服务器将客户端上传的本地模型通过二阶重聚合操作生成新的全局模型,同时,将上传的本地原型集合进行一阶加权聚合得到新的全局原型集合,将新的全局模型与新的全局原型集合发送给参与训练的个客户端;
4、s4、各客户端把当前本地模型的特征提取器部分全部更新为新的全局模型的特征提取器部分,同时,把当前本地模型的分类器部分则根据自端当前数据集的异构程度来动态决定新的全局模型的分类器部分在本次分类器部分更新中的占比;
5、然后,当前本地模型更新完成后进行本地训练得到最新的本地模型,并使用最新的本地模型生成本客户端最新的本地原型集合,最后,将最新的本地模型与新的本地原型集合上传到服务器;
6、s5、重复s3-s4,直到全局模型收敛或者完成预设的结束条件,从而让每个客户端获得泛化性能更强且与自端的数据集分布相匹配的个性化联邦学习模型。
7、进一步地,在s2中在每个参与训练的客户端上进行更新,即将初始化全局模型作为各客户端本地模型,下标表示第个客户端,表示第i个客户端第1次本地更新后的模型;本地模型的训练指的是,指的是客户端i第次本地训练得到的本地模型,第个客户端的数据集为,为用于训练的属于数据集的小批次数据,为交叉熵损失函数,为关于的梯度,为训练时的学习率;
8、生成本客户端的原型集合指的,令所有客户端的数据集一共涉及个类,对于客户端i第个类的原型,它的生成过程为,是在数据集中属于第个类的数据,为第个客户端的特征提取器部分在输入中的数据后产生的特征向量,为数据量的大小。
9、进一步地,所述本地模型包括特征提取器部分和分类器部分;
10、所述特征提取器部分是由参数所决定的可学习函数,所述分类器部分是由参数所决定的可学习函数,故模型,其中t为第t轮训练,t=0时为初始状态,i为第个客户端;
11、所述本地模型过程:给定输入数据,为第个客户端的数据集,通过本地特征提取器部分获取维特征向量,随后将传递给分类器部分函数,以获得最终的预测结果。
12、进一步地,所述将客户端训练完成后上传的本地模型通过二阶重聚合操作生成新的全局模型,具体包括:
13、首先使用距离加权聚合形成子公共模型,然后通过平均聚合这些子公共模型以获得全局模型;
14、所述使用距离加权聚合形成子公共模型使用余弦相似度来进行距离衡量:
15、(1);
16、公式(1)中,,,为第个客户端在第t轮本地训练后上传的模型,为第个客户端的私有数据集的大小,下标为第个客户端;
17、获取基于距离的聚合权重之后,首先通过基于余弦相似度的距离加权聚合生成子公共模型,之后通过平均聚合生成全局模型,具体聚合方案如下:
18、(2);
19、(3);
20、公式(2)-(3)中,每个子公共模型在聚合时会随机选择个本地模型,把第个子公共模型聚合时选择的个本地模型的下标放入到集合中,表示第个客户端在第t轮聚合前生成的基于距离的聚合权重,表示第个客户端第t轮本地训练后上传到服务器的模型,表示第t轮聚合时生成的第个子公共模型,共生成个子公共模型,将子公共模型再进行加和取平均操作,得到第t轮聚合后的新的全局模型;
21、所述将上传的本地原型集合进行一阶加权聚合得到新的全局原型集合具体为:
22、对于第t轮本地训练的全局原型集合是通过对本地上传的本地原型集合进行基于客户端样本量的加权聚合来得到,其中k为客户端数据集中的第个类,即。
23、进一步地,所述本地模型的分类器部分则根据自端当前数据集的异构程度来动态决定最新传下来的全局模型的分类器部分在本次分类器部分更新中的占比,具体为:
24、当数据异构程度高于50%时,全局聚合分类器部分的权重占比应低于50%,以提高分类器部分的个性化程度;而当数据异构程度低于50%时,全局聚合分类器部分的权重占比应高于50%,以降低分类器部分的个性化程度:
25、(4);
26、公式(4)中,表示第t+1轮更新后的第个客户端的本地分类器部分,表示第轮聚合后的全局分类器部分,表示第t轮训练后第个客户端的本地分类器部分,代表当前数据的异构程度。
27、进一步地,本地模型更新完成后进行本地训练具体为:
28、对于客户端的本地模型的特征提取器部分的本地训练,采用引入与全局原型相关的正则化项的方式来约束其训练,同时,采用了均方根误差来构造正则化项,关于客户端i训练特征提取器时候所加入的正则化项的设定如下:
29、(5);
30、公式(5)中,t为第t轮本地训练,是用于平衡监督函数损失即交叉熵损失与正则化损失的超参数,为第二范数,为第个客户端数据集中的数据,且它对应的类为,第次聚合后生成的全局原型的集合;
31、对于特征提取器部分和分类器部分分开利用进行训练,即在训练特征提取器部分时将分类器部分进行固定;训练分类器部分时将特征提取器部分进行固定,采用先训练分类器部分后训练特征提取器部分的策略,具体操作如下:
32、(6);
33、(7);
34、公式(6)-(7)中,分别为训练分类器部分和训练特征提取器部分时的学习率,表示用于训练的属于数据集的小批次数据,以及为交叉熵损失函数,而。
35、本发明还包括了一种基于双组件二阶聚合与重优化分类器部分的联邦学习装置,所述装置包括:
36、处理器;
37、存储器,其上存储有可在所述处理器上运行的计算机程序;其中,所述计算机程序被所述处理器执行时实现所述的基于双组件二阶聚合与重优化分类器部分的联邦学习方法的步骤。
38、本发明还公开了一种计算机可读存储介质,所述计算机可读存储介质上存储有基于双组件二阶聚合与重优化分类器部分的联邦学习方法的程序,所述一种基于双组件二阶聚合与重优化分类器部分的联邦学习程序被所述处理器执行时实现所述的一种基于双组件二阶聚合与重优化分类器部分的联邦学习方法的步骤。
39、与现有技术相比,本发明的有益效果为:
40、本发明提出一种基于双组件二阶聚合与重优化分类器部分的联邦学习方法,通过双层聚合,中心方能够获取一个泛化性能更强的全局模型;而将本地模型的特征提取器部分和分类器部分分开处理,则能更好地应对各方数据的差异,同时,全局聚合特征提取器部分允许各方共享模型信息,从而提高模型的泛化能力;而个性化处理分类器部分,则根据每个参与方的本地数据特点进行个性化调整,以提高模型在本地任务上的性能表现,两者结合平衡了共性特征和个性化信息之间的关系,使得联邦学习模型更具灵活性和泛化能力,能够更有效地应对数据异构问题。
- 还没有人留言评论。精彩留言会获得点赞!