一种语篇级事件时间线生成方法
本发明属于计算机应用,具体涉及一种语篇级事件时间线生成方法。
背景技术:
1、当今时代,信息技术的高速发展极大提高了社会的生产力水平,以人工智能、云计算、物联网等为代表的技术开启了新一轮工业革命。作为新一轮工业革命中最具代表性的技术,人工智能使得机器具有智能化的行为和思维,极大地提高了人类社会的生产效率。自然语言处理是人工智能的一个重要分支,它的目的是使机器能够理解并生成人类的语言。自然语言处理涉及的领域众多,在众多行业均有广阔的应用前景,如社交媒体、金融分析、电子商务等。
2、随着众多行业数字化转型的趋势,大量文本数据涌现,如新闻、电子病历、科学文献等。这些数据大多以非结构化形式存在,人工管理和利用这些数据极为繁琐且耗费人力。使用信息抽取技术从海量的文本数据中抽取有效信息,将非结构化数据转化为结构化数据,有助于数据的存储、查询、分析。例如,信息抽取技术可从自然语言文本中提取实体、关系、事件、情感、主题、关键词、摘要等。事件是描述现实世界情况的语言单位,相比实体,以事件为基本单位进行信息抽取能更有效地反映文本内容和逻辑关系。以事件为基本单位的信息抽取包括事件抽取与事件关系抽取。研究人员通常将事件抽取与事件时序关系抽取结合以揭示事件间的联系与影响,理解文本的逻辑与结构,即生成事件时间线。事件时间线生成旨在从文本中提取出事件论元参数和事件对时序关系,并以时间线形式展示事件详情,该方向已经成为金融、法律、医疗等领域的研究热点。过去多数事件抽取与事件时序关系抽取技术基于语句级文本,与之相比,语篇级别的技术更符合各大领域的实际需求。例如,对于新闻报道、历史研究等语篇,通过生成语篇级事件时间线梳理文本内容与逻辑结构;对于舆情监测、金融分析等应用场景,通过提取语篇级事件时间线跟踪事件发展、预测事件未来趋势。此外,语篇级事件时间线生成技术对于下游研究任务也起着至关重要的作用。例如,将事件时间线结合问答系统生成文本摘要;将事件时间线中的事件要素与事件关系信息嵌入图谱中,构建时序知识图谱。
3、事件抽取与事件时序关系抽取是构建语篇级事件时间线的两项关键技术,也是自然语言处理领域的研究热点。事件抽取的目标是从非结构化或半结构化文本中识别事件类型并抽取论元参数,是信息抽取领域中最具挑战性的任务之一,而语篇级事件抽取的精确率和召回率远低于语句级事件抽取。语篇级事件抽取任务主要面临两个问题:论元参数分散问题与多事件论元参数组装问题。现有深度学习方法难以理解并建模语篇中语句间、实体提及间的关系,也难以事先识别语篇中事件数量并将所有候选参数正确分配给不同事件。事件的时序关系抽取是事件关系抽取中的一类,其目标是识别事件的发生顺序并将事件对的时序关系进行分类,如“after”、“before”等。语篇级事件时序关系抽取的主要问题在于,相较于语句级任务,语篇级任务以识别非相邻句的事件时序关系为主,使用传统句内方法会因事件对文本距离较长而引入大量对识别时序关系毫无帮助的噪声。此外,语篇级任务还存在全局事件时序关系不一致问题,分类器对某些时序关系的判别的失误会与时序关系本身的性质相矛盾。
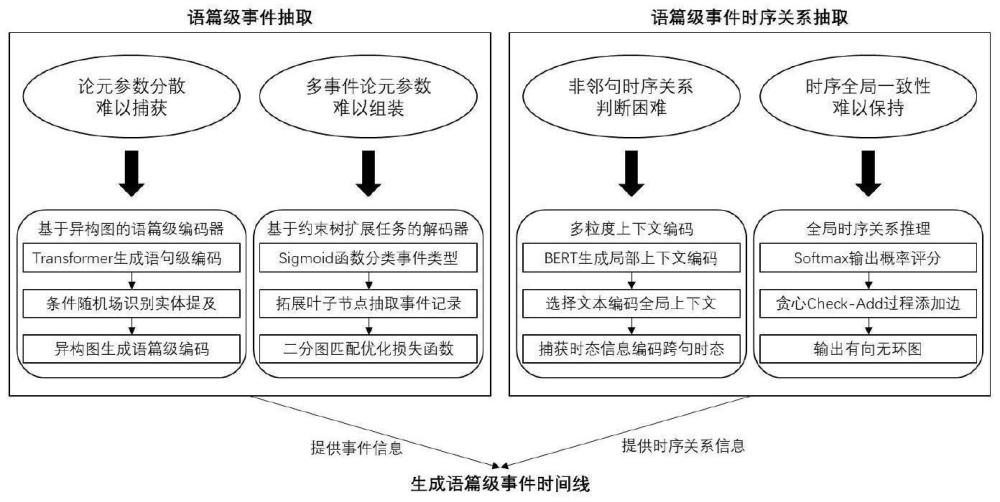
4、综上所述,语篇级事件抽取任务存在论元分散难以捕获、多事件论元参数难以组装两方面的问题;语篇级事件时序关系抽取任务存在非相邻句事件时序关系难以识别、时序关系全局一致性难以保持两方面的问题。解决以上问题,提升语篇级事件抽取与语篇级事件时序关系抽取的精确率,从而生成准确的语篇级事件时间线,具有重要的理论意义和应用价值。
技术实现思路
1、本发明的目的在于克服现有技术中的不足之处,提供了一种语篇级事件时间线生成方法。
2、为了实现本发明的目的,我们将采用如下所述的技术方案加以实施。
3、一种语篇级事件时间线生成方法,包括如下步骤:
4、s1、采用基于异构图的语篇级事件抽取方法提供事件要素;
5、s2、采用多粒度上下文编码的语篇级事件时序关系抽取方法提供时序信息;
6、s3、根据s1和s2所提供的事件要素与时序信息,生成事件时间线。
7、作为本发明的优选方案,所述基于异构图的语篇级事件抽取方法,包括如下所述的步骤:
8、s1、从语篇级文本中构建异构图建模显式交互,通过图转换网络处理异构图,捕捉语篇中实体提及、语句的隐式交互,从而捕获分散在语篇中的论元参数;
9、s2、基于实体的约束树拓展任务,根据预定义的论元抽取顺序拓展叶子节点形成事件记录,使用基于二分图匹配的损失函数匹配预测事件与真实事件,组装多事件论元。
10、作为本发明的优选方案,所述基于异构图的语篇级事件抽取方法的框架分为编码器与解码器两部分,其中:
11、编码器,将文本序列结构转变为图结构,建模语句与实体提及的显性交互,将初始图放入图转移网络,补全语句与实体提及的隐性交互,避免论元参数提取时的遗漏;
12、解码器,通过语句嵌入识别事件类型,抽取各事件类型的记录,将多事件论元参数的组装建模为约束树扩展任务;其中,所述约束树扩展任务的叶子节点为候选论元参数,逐层扩展为多条记录,使用基于二分图匹配的损失函数引导模型训练。
13、作为本发明的优选方案,所述编码器包含语句级编码层、条件随机场层和语篇级编码层,其中:
14、所述语句级编码层根据输入的文档中的语句获得每句语句的上下文表示;
15、所述条件随机场层通过识别实体,在语句级别提取实体提及作为候选论元参数;
16、所述语篇级编码层通过构建具有实体提及节点与句子节点的异构图捕获节点之间的全局交互关系,生成语句和实体提及的语篇级表示。
17、作为本发明的优选方案,所述解码器包含事件类型分类与事件记录抽取两个步骤,其中:
18、所述事件类型分类步骤是以多标签分类任务建模,利用sigmoid函数判断文档中包含的事件类型;
19、所述事件记录抽取步骤是依据论元的预定义提取顺序判断候选实体能否成为当前论元;
20、由所述事件类型分类步骤进入所述事件记录抽取步骤的条件:当事件类型分类步骤判断文档中包含特定类型的事件时,进入事件记录抽取步骤。
21、作为本发明的优选方案,所述的多粒度上下文编码的语篇级事件时序关系抽取方法,包括如下所述的步骤:
22、s1、通过局部上下文编码器、全局上下文编码器和跨句时态编码器分别对局部上下文、全局上下文与跨句时态进行编码,编码后映射至相同的向量空间进行连接,连接后输入softmax层执行分类任务,预测非相邻语句的事件时序关系;
23、s2、使用贪心check-add过程进行全局时序关系推理,按概率降序逐个考察当前边是否会使时序图中引入冲突,结合softmax层对各关系类预测的概率替换低概率强度的边,保持时序关系的全局一致性。
24、作为本发明的优选方案,所述局部上下文编码器用来获取输入事件句的全部语义信息;所述全局上下文编码器采用注意力机制寻找并编码上下文中的相关信息;所述跨句时态编码器采用注意力机制编码跨句时态sdp。
25、作为本发明的优选方案,所述的softmax层作为分类器,用于对每对事件的时序标签进行预测。
26、作为本发明的优选方案,所述的全局时序关系推理的方法,包括如下所述的步骤:
27、s1、以softmax层对每个关系类的概率评分作为边的强度,对于一个给定关系,将所有事件顶点添加至图中;其中,所有边按概率评分降序排序;
28、s2、使用timegraph算法判断是否存在循环,若存在则记录被移除边,不存在则添加至图中;
29、s3、将所有边使用s2判断完毕后,按概率评分升序排列被移除边;
30、s4、逐一使用当前事件对概率评分次高的时序关系类型在图中添加边;
31、s5、添加边后再次使用timegraph算法判断是否存在循环,若存在则使用概率评分第三的时序关系类型,直至被移除边全部添加完毕。
32、作为本发明的优选方案,所述timegraph算法,具体包括以下步骤:
33、①从任意一个未访问的顶点开始,将其压入栈中,并标记为正在访问;
34、②对栈顶的顶点,找出它的一个未访问的邻接顶点,如果存在,则将其压入栈中,并标记为正在访问;如果不存在,则将栈顶的顶点弹出,并标记为已访问;
35、③重复②,直到栈为空或者发现一个正在访问的邻接顶点;
36、④如果发现一个正在访问的邻接顶点,说明存在环;否则,说明不存在环;
37、⑤如果还有未访问的顶点,回到①;否则,结束算法。
38、有益效果
39、一、本发明根据基于异构图的语篇级事件抽取方法,解决了论元参数分散难以捕获和多事件论元参数难以组装两方面的问题;
40、二、本发明根据基于多粒度上下文编码的语篇级事件时序关系抽取方法,解决了非相邻语句事件时序关系判断困难和时序关系全局一致性难以保持问题。
- 还没有人留言评论。精彩留言会获得点赞!