一种基于信誉委员会的三阶段自适应联邦学习系统及方法
本发明涉及联邦学习,具体为一种基于信誉委员会的三阶段自适应联邦学习系统及方法。
背景技术:
1、近年来,随着物联网、边缘计算和人工智能等新兴技术的发展,众多领域都呈现数据爆发式增长的趋势,以机器学习为代表的数据驱动型技术得到了深入发展与应用。然而,绝大多数企业之间出于竞争、保护用户隐私等原因无法有效地进行数据共享,阻碍了各行各业的发展。联邦学习的出现为企业提供了新思路,可实现各参与方在数据不出本地的情况下协同训练全局模型。
2、然而,传统的联邦学习模型基于中心化架构,存在单点失效、隐私泄露、性能瓶颈等问题。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术的不足,本发明提供了一种基于信誉委员会的三阶段自适应联邦学习系统及方法,具备降低低质量本地模型的权重,提升模型训练效率与效用,减少恶意参与者的收益,构建积极的联邦学习生态等优点,解决了上述技术的问题。
3、(二)技术方案
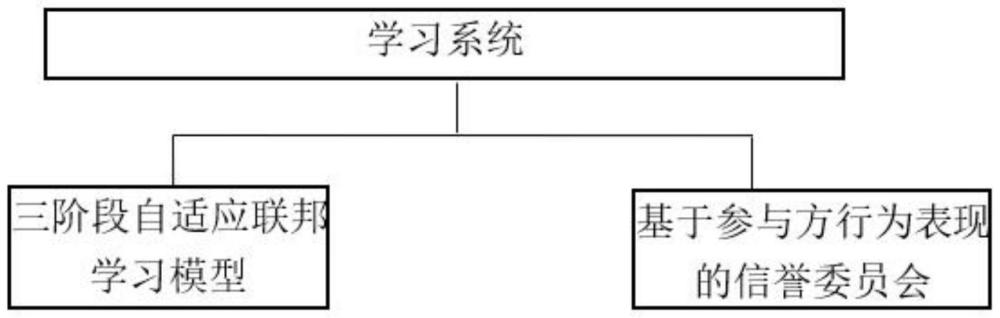
4、为实现上述目的,本发明提供如下技术方案:一种基于信誉委员会的三阶段自适应联邦学习系统,所述学习系统包括三阶段自适应联邦学习模块和基于参与方行为表现的信誉委员会模块;
5、所述的三阶段自适应联邦学习模块用于对各参与者本地训练后的模型梯度参数加入差分隐私噪声,然后由联邦委员会对加噪模型进行交叉审计,依据审计结果,委员会领导人进行全局模型聚合;当达到最大迭代轮次时,将获得一个高质量的联邦学习模型;
6、所述基于参与方行为表现的信誉委员会模块用于计算每一次联邦学习迭代中参与者的训练分和审计分以及历史完成率,然后选出高分的参与者当选委员会成员,最后依据信誉发放激励,以奖励高质量参与者并降低参与方发生恶意行为的概率。
7、优选的,所述联邦学习过程中的模型参数、审计结果均存储于区块链。
8、一种基于信誉委员会的三阶段自适应联邦学习方法,具体包括如下步骤:
9、步骤一:联邦学习任务初始化。任务发起者发布任务,具体信息包括联邦学习超参数、初始模型等,系统将随机选取一位参与者作为初始领导人;
10、步骤二:本地训练,依据信誉分为模型加入噪声,具体为:
11、s2.1各参与者下载最新的全局模型至本地,准备本地数据集。
12、s2.2参与者开始本地训练,计算本地数据集上的损失函数,并采用随机梯度下降法计算本地模型梯度值,其中参与者pi在t轮,计算本地数据集上的损失函数,得到本地模型梯度值
13、s2.3系统根据各参与者的信誉分,规定参与者的差分隐私预算数值,为参与者的本地训练模型梯度加入拉普拉斯噪声,其中参与者pi在t轮的加噪梯度参数其中为隐私预算下的噪声,隐私预算为ε0为默认差分隐私大小,表示t-1轮平均信誉分,表示t-1轮pi的信誉分。然后,pi使用本地模型梯度更新本地模型αi为pi的学习率。
14、s2.4:参与者将本地模型通过共识算法上传至区块链。
15、步骤三:委员会审计,为全局模型与其他参与者的本地模型评分,具体:
16、s3.1委员会在进行本地训练时,也对全局模型进行审计,计算该模型在本地数据集上的交叉熵损失函数,然后对比上一轮的损失函数,进行全局模型审计,其中委员会成员vj在t轮下载最新的全局模型,在数据样本(xk,yk)上的损失函数为然后对比目标函数和其中若大部分委员会均认为训练结果变差,则重新选举委员会领导人。
17、s3.2委员会下载其他参与者的本地模型,利用本地数据集测试参与者的本地模型准确率。例如委员会成员vj在t轮下载pi的本地模型使用本地数据集得到审计结果其中,yk和分别为xk的实际标签值和预测值。
18、s3.3委员会将审计结果通过共识算法上传至区块链。
19、步骤四:全局模型聚合,选取余弦相似度检测合格的本地模型,并按照审计分聚合,具体:
20、s4.1当到达最大时间间隔时,委员会领导人下载参与者的本地模型,计算该本地模型与上一轮全局模型的余弦相似度,在一定范围内的本地模型将选入合格局部模型集合,用于最终聚合,其中领导人下载pi的本地模型计算与上一轮的余弦相似度若在范围(σ,1)内,则将该模型选入合格局部模型集合,σ用于调整阈值。
21、s4.2委员会领导人统计每位参与者对应的审计平均分,其中pi的本地模型的审计平均分为qi表示最大时间间隔内委员会对该模型打分的数量。
22、s4.3委员会领导人计算最终聚合权重,合格局部模型将按照平均审计分的占比分配聚合权重,不合格的局部模型将不分配聚合权重,其中pi的本地模型聚合权重可表示为其中q为合格局部模型数量。
23、s4.4委员会领导人将合格局部模型进行自适应聚合,生成新的全局模型其中聚合权重满足
24、s4.5委员会领导人将全局模型通过共识算法上传至区块链。
25、步骤五信誉分结算,具体:
26、s5.1系统计算联邦训练分,用于衡量参与者的模型质量表现,其中pi在t轮的联邦训练分表示为为合格局部模型。
27、s5.2系统计算联邦审计分,用于衡量委员会对局部模型的审计偏差,其中vi在t轮的联邦审计分表示为
28、s5.3系统计算历史完成率,用于衡量参与者在系统中的稳定性与工作效率,历史完成率表示为其中n为参与事务的数量,s为完成事务的数量。
29、s5.4系统综合统计该轮的信誉分。例如pi在t轮的信誉分可表示为a、β用于调节联邦训练分和联邦审计分的比重。
30、s5.5系统将信誉分结果通过共识算法上传至区块链。
31、步骤六委员会选举,信誉分排名靠前的参与者选入委员会,并选取信誉值最高的参与者为领导人,进行下一轮的联邦学习迭代。
32、步骤七在规定的迭代次数或指定精度达成前,将重复步骤二至步骤六。最终,本系统将得到一个高质量的联邦学习模型,并依据累计信誉分,为所有参与者分配激励。
33、与现有技术相比,本发明提供了一种基于信誉委员会的三阶段自适应联邦学习系统及方法,具备以下有益效果:
34、1、本发明通过“本地训练-委员会审计-全局模型聚合”的三阶段自适应联邦学习方案,达到了降低低质量本地模型的权重,提升模型训练效率与效用的有益效果。
35、2、本发明通过综合计算参与者的训练表现、审计表现与历史完成率,筛选出可靠、高效的参与者作为联邦委员会成员。在“本地训练-委员会审计-全局模型聚合”的三阶段自适应联邦学习过程中,为参与者本地训练所得的模型分配基于信誉分的差分隐私预算,并综合统计委员会对参与者的本地模型评分作为聚合权重,筛除余弦相似度不符的低质量模型,因此,该方案不仅可以有效保护参与者的数据隐私,还能筛选高质量的模型,提升联邦学习的收敛速度与模型效用。同时,信誉分还可以有效激励高质量参与者,达到了减少恶意参与者的收益,构建积极的联邦学习生态的有益效果。
36、3、本发明通过构建基于参与方行为表现的信誉委员会,通过结合信誉分为参与者分配差分隐私预算的方式,达到了降低单点失效风险,为高质量参与者提供更高的隐私保护程的有益效果。
- 还没有人留言评论。精彩留言会获得点赞!