一种基于蒸馏CLIP模型的生成式零样本目标检测方法及系统
本发明属于目标检测,特别涉及一种基于蒸馏clip模型的生成式零样本目标检测方法及系统。
背景技术:
1、零样本目标检测(zero-shot object detection,zsd)是一项具有挑战性但潜力巨大的任务。该任务旨在要求系统在没有任何有关未见类(unseen class)的有标注训练样本的前提下,识别且定位这些未见类物体。由于现实场景新物体不断出现,罕见物体难以采样,人工对领域内所有类别的标注很难实现完全覆盖,传统的目标检测方法面临训练数据不足的困境,因此零样本目标检测对于实际应用具有重要意义。
2、利用生成模型进行知识迁移是零样本目标检测的一个解决途径。生成式零样本目标检测框架通过已见类的语义嵌入(semantic embedding)和视觉特征为未见类训练一个视觉特征生成器,并使用未见类语义嵌入生成未见类特征以训练分类器,对目标检测主干的分类器进行补充。基于生成的方法可以有效改善已见类偏见和枢纽点(hubness)问题,减少对未见类的负面知识转移。然而,改善效果很大程度上取决于视觉特征生成器的训练质量。由于训练数据有限,生成器模型如gan、vae可能出现严重的过拟合,导致生成效果退化、多样性不足,进而影响分类器的判断。
3、近年来,大型预训练视觉语言模型在自然语言处理和计算机视觉领域取得了显著的突破。这些模型在大规模文本图像数据上进行预训练,具有强大的多模态能力和丰富的视觉语义泛化知识,通过微调在下游与图文关系相关的任务中取得优越表现,甚至具有一定的零样本能力。然而,基于其具有庞大参数量、较高硬件要求和较慢推理速度的特点,在多数情境下并不适合直接部署应用。因此许多研究致力于通过知识蒸馏将大模型内蕴含的丰富知识转移至下游任务的模型中,在不占用过多计算资源的前提下提高性能。
4、目前大模型对于零样本任务的知识迁移工作主要集中于通过对齐特征提高目标检测主干的检测能力,这些方法存在着以下局限性:(1)训练成本大大增加,由于主干训练期间特征提取数量庞大,大模型提取既增加时间又占用显存;(2)虽然大模型拥有丰富的泛化知识,但其数据分布和已见类的分布未必相同,强行对齐会导致模型学习到部分损害检测能力的知识,不利于整体效果的提高;(3)尚未发现有相关工作对于生成式零样本检测框架的生成部分设计优化策略,忽略了大模型对语义监督的生成对抗网络过拟合和多样性不足的改善效果。
技术实现思路
1、为了克服上述现有技术的缺点,本发明的目的在于提供一种基于蒸馏clip模型的生成式零样本目标检测方法及系统,该方法通过蒸馏多模态大模型clip,引导生成式零样本检测框架中的生成训练,能够有效改善未见类特征生成效果,解决大模型指导零样本任务的知识迁移过程中训练成本高、缺少针对生成的优化策略,导致降低零样本目标检测精确度与召回率的问题。
2、为了实现上述目的,本发明采用的技术方案是:
3、第一方面,本发明提供了一种基于蒸馏clip模型的生成式零样本目标检测方法,包括以下步骤:
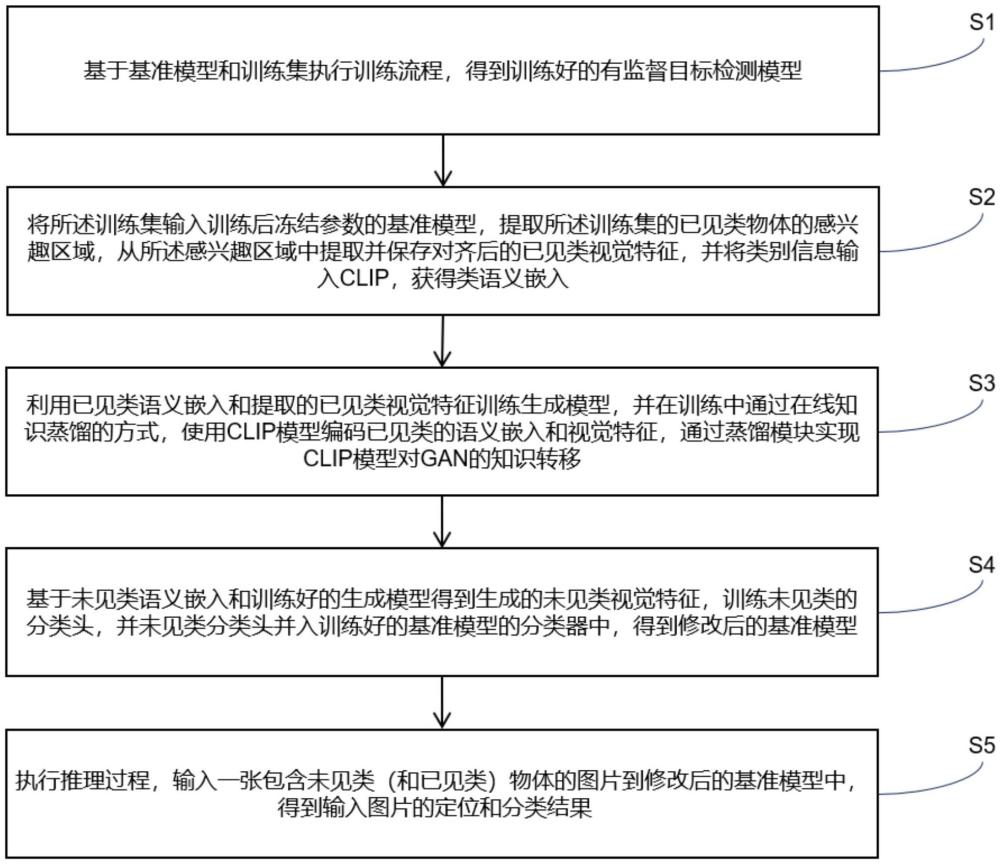
4、s1,获取数据集,并基于基准模型和训练集执行训练流程,得到训练好的有监督目标检测模型;所述数据集中的数据为包含有一个或多个物体的图片,且物体分为已见类和未见类;已见类数据集的图片只包含属于已见类的物体,用作训练集和验证集,未见类数据集的图片包含至少一个属于未见类的物体,用作测试集;所述已见类,指的是在训练和验证期间类别名、物体框的标注、图像可见的类别,所述未见类,指的是在训练和验证期间物体框的标注和图像不可见的类别;
5、s2,将所述训练集输入训练后冻结参数的基准模型,提取所述训练集的已见类物体的感兴趣区域,从所述感兴趣区域中提取并保存对齐后的已见类视觉特征,并将已见类和未见类的类别信息分别输入clip模型,获得类语义嵌入;
6、s3,利用已见类语义嵌入和提取的已见类视觉特征训练生成模型,并在训练中通过离线知识蒸馏的方式,使用clip模型编码已见类语义嵌入和已见类视觉特征,通过蒸馏模块实现clip模型对生成模型的知识转移;
7、s4,基于未见类语义嵌入和训练好的生成模型得到生成的未见类视觉特征,训练未见类的分类头,并将未见类分类头并入训练好的基准模型的分类器中,得到修改后的基准模型;
8、s5,执行推理过程,输入一张包含未见类或者包含未见类和已见类物体的图片到修改后的基准模型中,得到输入图片的定位和分类结果。
9、示例地,s1中,所述执行训练流程,得到训练好的有监督目标检测模型,包括:
10、基准模型使用faster r-cnn(faster region-based convolutional neuralnetwork)两阶段目标检测算法,数据集使用ms-coco;
11、根据所述基准模型和已见类数据集执行faster r-cnn训练流程,得到网络框架中各个模块的初始参数。
12、示例地,s2中,提取所述训练集的已见类物体的感兴趣区域,从所述感兴趣区域中提取并保存对齐后的已见类视觉特征,包括:
13、基于所述训练集,通过卷积网络和特征金字塔模块获得融合后的图片特征;
14、通过rpn(region proposal network)模块从所述融合后的图片特征提取已见类物体的感兴趣区域并分配对应的真实类别标签,再通过roialign模块提取与感兴趣区域的尺寸无关的、按固定尺寸对齐的特征图,并对这些特征图和其对应的真实类别标签进行离线存储操作;
15、将已见类和未见类的类别标签分别token化后输入clip模型的文本编码器t,得到已见类语义嵌入和未见类语义嵌入;
16、将所述类别标签采用固定的提示格式进行构造。
17、示例地,s3中,利用已见类语义嵌入和提取的已见类视觉特征训练生成模型,通过蒸馏模块实现clip模型对生成模型的知识转移,包括:
18、s3-1:使用已见类语义嵌入和提取的已见类视觉特征作为生成模型gan的输入,gan包括生成器g和判别器d两部分,首先被初始化为随机权重;
19、s3-2:在训练中,生成器g输入随机高斯噪声和已见类语义嵌入,输出伪特征其中ts为已见类语义嵌入;
20、以clip模型为教师模型,其图像编码器i输入解码后的已见类视觉特征f和伪特征产生输出i(f)和
21、判别器d输入已见类视觉特征f和伪特征并进行评估,产生输出d(f)和
22、s3-3:根据i(f)、d(f)和计算用于进行教师模型知识迁移的交叉增强蒸馏损失lkd-ce和多样增强蒸馏损失lkd-de;
23、s3-4:通过生成器g和判别器d各自的损失交替更新并迭代生成模型。
24、示例地,所述s3-3:
25、lkd-ce一方面通过l1损失使判别器d对齐图像编码器i的视觉特征空间,另一方面通过l1损失混淆真实特征和伪特征,由下式计算得出:
26、
27、
28、
29、lkd-de一方面通过余弦相似度损失强化伪特征和已见类语义嵌入ts之间的多样相关性,另一方面通过l1损失使判别器d学习所述多样相关性,由下式计算得出:
30、
31、
32、
33、其中,是和ts的l2-归一化内积,是和ts的l2-归一化内积,表示中的第i行,表示中的第j行,是和的余弦相似度,n表示的行数。
34、示例地,s4中,基于未见类语义嵌入和训练好的生成模型得到生成的未见类视觉特征,训练未见类的分类头,方法如下:将未见类语义嵌入输入训练好的生成模型的生成器g中,输出生成的未见类视觉特征,并将未见类视觉特征通过由神经网络全连接层构成的分类器进行前向传播,得到具有权重信息的未见类分类头。
35、第二方面,本发明提供了一种基于蒸馏clip模型的生成式零样本目标检测系统,用于实现第一方面所述的基于蒸馏clip模型的生成式零样本目标检测方法,包括:
36、准备单元,用于训练一个能够进行目标检测的基准模型,完成获取图片特征,提取感兴趣区域,从感兴趣区域中提取待检测物体特征,分类和物体框回归的目标检测过程;
37、提取单元,用于构造生成单元的训练数据,即从训练集图片中得到感兴趣区域,提取并保存已见类物体视觉特征,以及利用clip模型的文本编码器从类别信息中得到已见类语义嵌入;
38、蒸馏单元,用于利用物体视觉特征、类语义嵌入和知识蒸馏的方法将预训练教师模型clip模型和对抗生成网络之间以方法中所述的方式作蒸馏并计算蒸馏损失,用于通过离线蒸馏的方式训练学生模型对抗生成网络;
39、生成单元,用于利用未见类语义嵌入生成未见类视觉特征,训练未见类分类器,对准备单元的分类部分进行补充,得到推理单元;
40、推理单元,用于输入一张包含未见类或者包含未见类和已见类物体的图片到修改后的基准模型中,得到输入图片的定位和分类结果。
41、第三方面,本发明提供了一种计算机可读存储介质,其特征在于,用于存储计算机程序,所述计算机程序使得计算机执行本发明第一方面所述的方法。
42、第四方面,本发明提供了一种包含指令的计算机程序产品,当所述指令在计算机上运行时,使得所述计算机执行本发明第一方面所述的方法。
43、与现有技术相比,本发明的有益效果是:
44、根据本技术实施例的基于蒸馏clip模型的生成式零样本目标检测方法和系统,不同于在训练基准模型阶段使用蒸馏,旨在提高检测能力的方法,在提取到已见类特征和语义嵌入后,利用clip模型的文本编码器和图像编码器,通过离线知识蒸馏的方式将clip模型丰富的视觉语义知识用以优化对抗生成网络的辨别器,达到优化生成质量的效果,从而以优化未见类视觉特征生成的方式实现对零样本目标检测精度的提高。
45、本发明的方法中所涉及的算法,避免了基准模型引入大模型蒸馏时提取大量区域特征所导致的耗时长、内存占用大的问题,以及直接对齐特征引入不匹配信息的损害。同时,切合了影响生成式零样本检测精度的关键组成部分,保留了生成式零样本检测相对于传统零样本检测不容易发生已见类偏见和枢纽点问题的优势,在此基础上进行了优化,极大地提升了零样本目标检测的性能。
46、本发明的系统通过准备单元、提取单元、蒸馏单元、生成单元及推理单元的配合,构建了一个离线知识蒸馏结构,实现了将预训练视觉语义大模型的知识转移到生成式零样本检测框架的生成模型部分。
- 还没有人留言评论。精彩留言会获得点赞!