一种多维度矩阵式对接科研工作者和技术型企业的方法
本发明涉及科研合作领域的信息技术应用,特别是涉及一种利用大型语言模型和数据分析技术提高科研工作者与技术型企业间合作效率的方法。
背景技术:
1、在现代科研环境中,高效的合作与资源共享对于推动科学进步至关重要。尽管存在各种平台和工具促进科研合作,但它们往往存在信息不对称和资源匹配困难的问题。科研工作者和技术型企业在寻找合适的合作伙伴和共享资源时,常受限于平台的功能局限性和信息获取的效率。当前的科研合作平台通常缺乏足够的个性化服务和高效的资源匹配功能,导致科研资源的利用不够高效,且合作机会的发掘不尽人意。此外,跨文化和跨语言的交流障碍也增加了国际合作的复杂性。因此,迫切需要一种集成现代信息技术的解决方案,特别是融合人工智能和大数据分析的方法,以提高科研合作的效率和质量,同时优化全球科研资源的配置。
2、现有技术中(申请号为202110104529.8的中国专利,公开了“一种企业技术对接系统及方法”)的企业对接方法,其虽然能够支持企业间的匹配和对接,但却极大依赖人为输入和数据库的搭建,不能保障准确性和灵活性,对人工成本的要求很高,同时无法保证覆盖面的广泛性。
技术实现思路
1、本发明的目的在于提供一种多维度对接科研工作者和技术型企业的方法及系统,以解决上述背景技术中提出的问题。
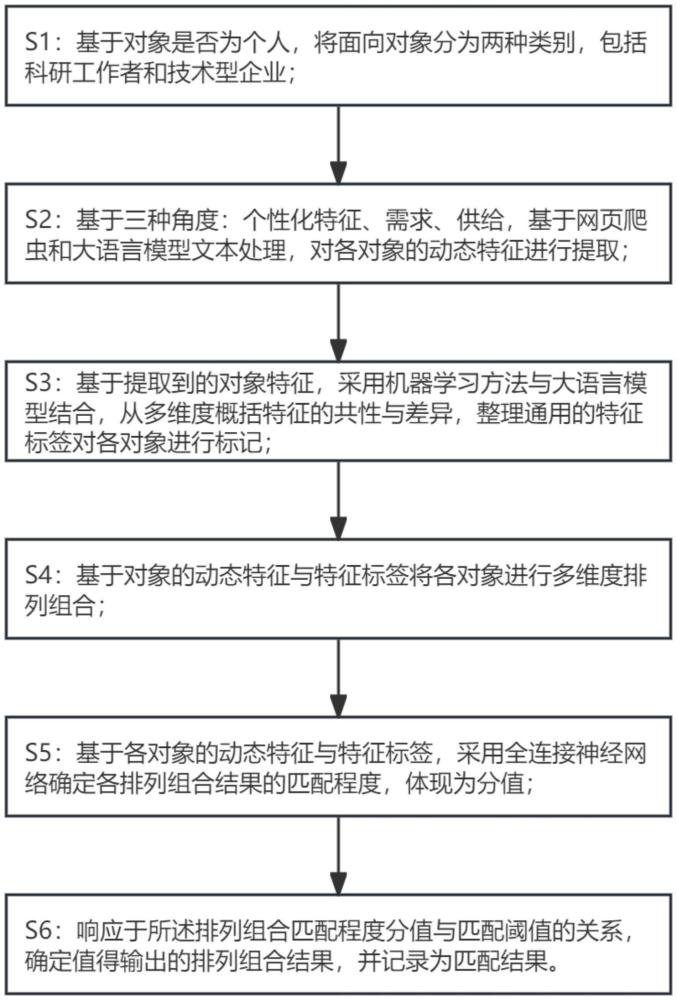
2、为实现上述目的,一种多维度矩阵式对接科研工作者和技术型企业的方法,所述方法用于提高科研工作者与科技企业间的合作效率,所述方法包括:
3、(1):基于对象是否为个人,将面向对象分为两种类别,即科研工作者和技术型企业;
4、(2):从个性化特征、需求和供给三种角度,基于网页爬虫和大语言模型文本处理,对对象的动态特征进行提取;
5、(2.1):基于科研工作者或技术型企业的主页链接,采用网页爬虫获取链接中的文本内容,并使用面向语言处理的机器学习模型进行文本清洗;
6、(2.2):基于包含对象特征信息的相关文本,采用大语言模型进行特征提取,从文本中筛选出对象的个性化特征,并根据这些特征和实时的领域现状推测出对象可能的需求和供给;
7、(3):基于提取到的对象特征,采用机器学习方法与大语言模型结合,从多维度概括特征的共性与差异,整理通用的特征标签对各对象进行标记;
8、(4):基于对象的动态特征与特征标签将各对象进行多维度排列组合;
9、(4.1):根据对象的需求与特征标签,使用大语言模型预测其匹配期望与特征标签的对应关系;
10、(4.2):收集所有待匹配对象的匹配期望,使用机器学习模型对匹配期望进行归纳与分类;
11、(4.3):基于各对象的供给与特征标签,使用机器学习模型针对每个类别的匹配期望生成多种组合结果;
12、(5):基于各对象的动态特征与特征标签,采用全连接神经网络确定各排列组合结果的匹配程度,体现为分值;
13、(5.1):将组合中对象的特征标签进行数字化编码,转化为特征向量;
14、(5.2):将步骤(5.1)中获取的各对象特征向量进行拼接,输入全连接神经网络;
15、(5.3):全连接神经网络对输入特征向量进行处理,输出预测的匹配分值;
16、(6):响应于所述排列组合匹配程度分值与匹配阈值的关系,确定值得输出的排列组合结果,并记录为匹配结果。
17、本发明中,步骤(1)中使用网页爬虫收集各研究所、高校、企业、个人的网站链接,并依据收集结果对链接性质进行归类,对面向对象进行分类;步骤(2)提取到的动态特征具有时间敏感性;具体的,每隔一段时间会针对所有对象进行特征的更新,以保证特征的实时性和有效性,同时,也会针对对象数量进行更新,收纳新增的对象并删除已无效的对象;步骤(3)概括对象特征标签,包括:采用机器学习方法和大语言模型针对所有对象特征进行比较与总结,从多维度概括特征的共性与差异,并整理出一系列特征标签将离散的对象特征模块化、具体化;步骤(6)基于匹配程度分值与匹配阈值对匹配结果进行筛选,包括:将匹配分值与匹配阈值进行比较,选取高于阈值的组合结果作为输出;如果在某次组合中,没有匹配分值超过阈值要求,则对匹配分值进行排序,选取分值最高的组合结果作为输出,并在结果中表明该输出具有一定模糊性。
18、本发明中,步骤(2.2)包含的特征提取用大语言模型,采用了相关领域内大量数据集进行针对性训练,包括:论文、专利、实时资讯、以及公开的研究结果。
19、本发明提出的多维度矩阵式对接科研工作者和技术型企业的方法使用的多维度矩阵式系统,该系统包括:对象收集与分类模块、动态特征提取模块、特征标签整合模块、多维度排列组合模块和分值预测模块结果筛选与输出模块;对象收集与分类模块收集对象主页链接集合,并将其分为科研工作者信息集合和技术型企业信息集合,动态特征提取模块收集科研工作者信息集合和技术型企业信息集合,并将其分别放入科研工作者数据库和技术型企业数据库,特征标签整合模块将科研工作者数据库和技术型企业数据库进行整理,得到带有特征标签的科研工作者数据库和带有特征标签的技术型企业数据库;多维度排列组合模块依据带有特征标签的科研工作者数据库和带有特征标签的技术型企业数据库进行排列组合,得到初步匹配结果集合,分值预测模块对初步匹配结果集合运用全连接神经网络技术进行匹配程度量化,得到匹配结果的分值集合,结果筛选与输出模块将匹配结果分值集合进行筛选,得到输出的匹配结果集合;
20、对象收集与分类模块:利用网页爬虫技术收集科研工作者和技术型企业的相关信息。该模块不仅能区分个人和企业对象,还能根据特定的标准对收集到的信息进行初步分类和筛选;
21、动态特征提取模块:结合网页爬虫和大语言模型文本处理技术,从个性化特征、需求、供给三个角度出发,对科研工作者和技术型企业的动态特征进行全面而深入的提取;
22、特征标签整合模块:通过机器学习方法和大语言模型的强大分析能力,对提取到的特征进行多维度的概括和对比,从而整理出通用的特征标签,并以此为基础对各对象进行有效标记;
23、多维度排列组合模块:依据对象的动态特征和特征标签,对科研工作者和技术型企业进行多维度的排列组合,为后续的匹配工作奠定基础;
24、分值预测模块:运用全连接神经网络技术,根据各对象的动态特征和特征标签,精确计算出各排列组合结果的匹配程度,并将此匹配程度量化为具体分值;
25、结果筛选与输出模块:基于预设的匹配阈值,筛选出匹配程度分值达到一定标准的排列组合结果,并将这些结果记录和输出,以供进一步分析或直接使用。
26、本发明中,所述对象收集与分类模块包括:使用网页爬虫收集各研究所、高校、企业、个人等对象的网站链接,并依据收集结果对链接性质进行归类;所述动态特征提取模块提取到的动态特征具有时间敏感性;具体的,每隔一段时间会针对所有对象进行特征的更新,以保证特征的实时性和有效性,同时,也会针对对象数量进行更新,收纳新增的对象并删除已无效的对象。
27、本发明中,所述模块动态特征提取模块包括:
28、模块2.1:基于个人或组织的主页链接,采用网页爬虫获取链接中的文本内容,并使用面向语言处理的机器学习模型进行文本清洗;
29、模块2.2:基于包含对象特征信息的相关文本,采用大语言模型进行特征提取,从文本中筛选出对象的个性化特征,并根据这些特征和实时的领域现状推测出对象可能的需求和供给;
30、定义筛选后的科研工作者对象为x数量为a,技术型企业对象为y数量为b;则有集合x={x1,x2,…,xi,…,xa},y={y1,y2,…,yi,…,yb}分别表示科研工作者和技术型企业对象的集合;
31、其中:所述模块2.2包含的特征提取用大语言模型,采用了相关领域内大量数据集进行针对性训练,包括:论文、专利、实时资讯、以及公开的研究结果。
32、本发明中,所述模块m3特征标签整合模块包括:采用机器学习方法和大语言模型针对所有对象特征进行比较与总结,从多维度概括特征的共性与差异,并整理出一系列特征标签将离散的对象特征模块化、具体化;
33、对于对象集合o,定义其包含的特征集合为v={v1,v2,…,vi,…,vn},其中vi表示第i个特征的量化值,体现为特征向量或特征点;定义参数e表征特征点的邻域半径,m表征邻域内的最少点数;对于每个特征点vi,找出其e-邻域内的所有点(包括vi),即距离vi不超过e的所有点;由表示特征点vi和vj的欧几里得距离,则有特征点vi的e-邻域内点的集合neighborhood(vi,e)={vj∈v|d(vi,vj)≤e};如果特征点vi的e-邻域内至少有m个特征点,则vi是一类特征的核心点,反之则为一边界点;针对所有的核心点进行遍历,假设遍历到核心点vk针对其邻域中包含的边界点,归类到同一簇中,针对邻域中的核心点,则将该核心点邻域中的点也归类到该簇中,并在剩余的遍历中忽略该核心点;最终可以得到多个由相似特征点组合成的特征簇,该簇的特征向量则由簇中的初始核心点vk表征;
34、接着使用大语言模型对特征簇的特征标签进行定义,以文本形式输入特征簇中包含的所有特征信息,并要求大语言模型进行总结与归纳,得到该特征簇的文字特征标签。
35、本发明中,所述模块多维度排列组合模块包括:
36、模块4.1:根据对象的需求与特征标签,使用大语言模型预测其匹配期望与特征标签的对应关系;
37、模块4.2:收集所有待匹配对象的匹配期望,使用机器学习模型对匹配期望进行归纳与分类;
38、模块4.3:基于各对象的供给与特征标签,使用机器学习模型针对每个类别的匹配期望生成多种组合结果。
39、本发明中,所述模块m5分值预测模块包括:
40、模块5.1:将组合中对象的特征标签进行数字化编码,转化为特征向量;
41、模块5.2:将模块5.1中获取的各对象特征向量进行拼接,输入全连接神经网络;
42、模块5.3:全连接神经网络对输入特征向量进行处理,输出预测的匹配分值;
43、假设某组合中包含两个对象xk,yk,其对应的特征标签集合分别为vx={vx1,vx2,…,vxn},vy={vy1,vy2,…,vym}。定义全连接神经网络为fcn,有sxy=fcn(vx1,vx2,…,vxn;vy1,vy2,…,vym),其中sxy为全连接神经网络输出的预测匹配分值。
44、本发明中,所述模块m6结果筛选与输出模块包括:将匹配分值与匹配阈值进行比较,选取高于阈值的组合结果作为输出;如果在某次组合中,没有匹配分值超过阈值要求,则对匹配分值进行排序,选取分值最高的组合结果作为输出,并在结果中表明该输出具有一定模糊性;
45、定义匹配阈值t,对每个组合结果p∈p,即其对应的匹配分值sp,比较sp和t。若sp>t,则输出该匹配对,否则,将p加入集合plist。如果plist不为空,则将plist进行排序,并将其中的最高值作为模糊组合结果进行输出。
46、本发明不仅可以提供科研工作者与企业的多维度对接服务,也可以扩展到其它类型的个人与组织之间的对接服务上,包含求职的个人与需要招聘的企业之间的多维度对接。
47、与现有发明相比,本发明的有益效果是:
48、1.通过使用自动化的方式进行信息收集与数据采集,本发明所涵盖的对象范围更广,运行所需的人工成本更低。
49、2.时间敏感的特征提取策略能够有效更新数据库内容,减少信息的滞后性。
50、3.合理的特征标签总结方式和精确的匹配手段能够提升匹配的有效性,增强匹配的精确程度。
- 还没有人留言评论。精彩留言会获得点赞!