一种基于大语言模型思维链的少样本篇章级事件抽取方法
本发明涉及自然语言处理,具体涉及一种基于大语言模型思维链的少样本篇章级事件抽取方法。
背景技术:
1、随着互联网的发展,大量的事件信息通过各种途径广泛传播。篇章级事件抽取作为自然语言处理领域的一项子任务,即是从文档级文本出发,从中抽取出结构化的事件信息,这有助于用户从大量的信息中快速、准确地捕获感兴趣的事件信息。
2、目前研究较多的是从一个句子中提取事件信息的句子级事件抽取,然而这种句子级事件抽取在面对篇章文本时,因为篇章级事件抽取面临的常规问题(论元分散,及一个事件的论元分散在文档的多个句子中。角色重叠,及在一个篇章中,某个论元可能在不同事件中扮演不同的角色),会造成事件信息(事件数量、类型、要素)提取不全面、不完整的情况。为了解决篇章级事件抽取任务的论元分散、角色重叠等常规问题,现有的模型结构非常复杂且精密,训练难度很大,同时跨领域和跨数据集性能不佳。
3、此外,因为事件信息的人工标注成本很高,从而导致高质量数据集稀少,且实际应用中普遍没有大量的标注样本供模型训练,为了处理具有有限注释的新兴事件信息并使其适应真实世界的文档级别情景,这项富有研究价值和高挑战度的少样本篇章级事件抽取成为了研究热点。然而由于长文档和有限的示例,这一新颖任务的难度非常大,传统模型性能普遍较低,提取分数不佳。因此,只需要一点提示就可以生成结果的大语言模型具有解决少样本事件抽取任务的可能性。
4、现有中国专利文件cn202211669257.7,公开了一种基于机器阅读理解的篇章级事件抽取方法、装置、设备及存储介质。该方法给定输入篇章与对应的填空模板,模型根据篇章内容对模板中相应论元槽位生成填空,实现事件论元的抽取。本发明针对篇章级事件抽取和少样本事件抽取问题,对传统事件抽取任务利用机器阅读理解机制进行实现,提供一种填空模板层面的事件抽取模式信息融合方法与基于预训练语言模型的机器阅读理解方法。本发明进一步公开了一种端到端的编码器-解码器模型,通过利用预训练语言模型的自然语言理解能力,挖掘预训练语言模型的潜在知识,能够提升模型能在少样本情形下的泛化性能,提高模型在不同领域的抽取任务上的自适应能力。
5、使用机器阅读理解的方法通常需要设计大量的模板,这些模板可能会受限于特定的语言结构和事件类型。而大语言模型思维链的方法只需要设计一个通用的思维链结构,不需要设计大量的预定义模板,且可以更灵活地处理不同类型和结构的事件。
6、本发明相比使用机器阅读理解的方法不需要用训练集进行训练,极大减少了训练时间和资源消耗。
7、与简单的模板方法相比,本发明的思维链可以更好地利用文本的上下文信息,这意味着它们可以更好地理解事件之间的关联性,在处理少样本篇章事件抽取时本发明性能更好。
技术实现思路
1、本发明的目的在于提供一种基于大语言模型思维链的少样本篇章级事件抽取方法,以解决现有的传统模型应对少样本篇章级事件抽取任务时,因为仅有非常有限的示例样本等难点,导致性能较低、模型结构非常复杂、训练难度很大、跨领域和跨数据集性能不佳等问题。
2、为实现上述技术目的,达到上述技术效果,本发明是通过以下技术方案实现:
3、一种基于大语言模型思维链的少样本篇章级事件抽取方法,包括以下步骤:
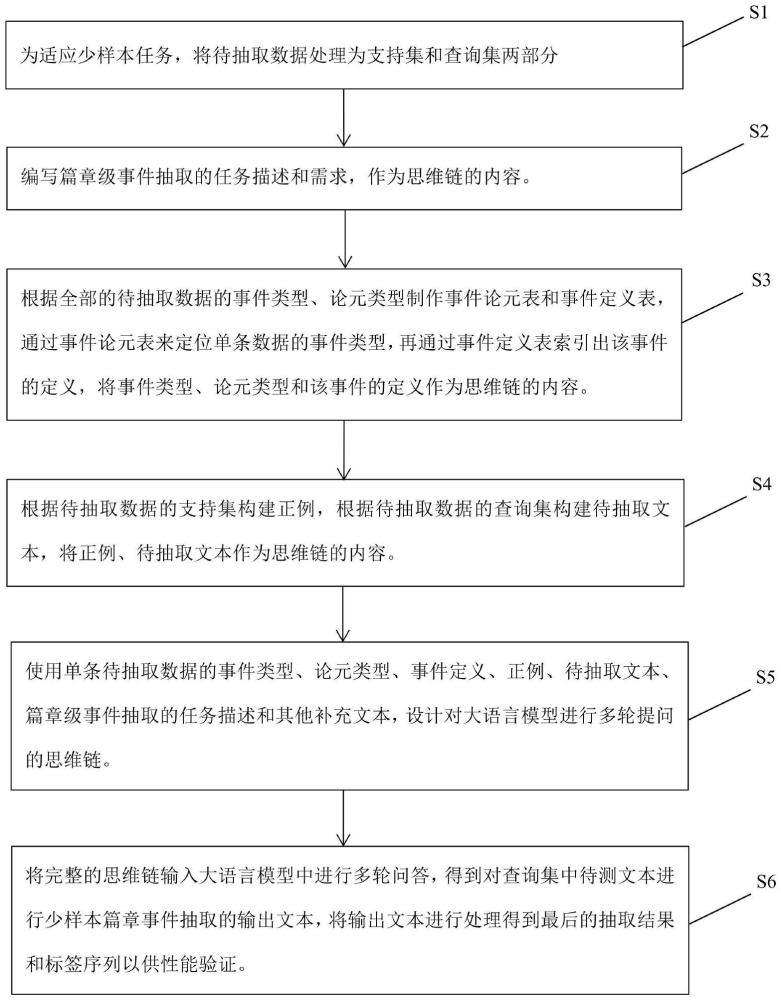
4、s1:为适应少样本任务,将待抽取数据处理为支持集和查询集两部分;
5、s2:编写篇章级事件抽取的任务描述和需求,作为思维链的内容;
6、s3:根据全部的待抽取数据的事件类型、论元类型构建事件论元表和事件定义表,通过事件论元表来索引单条数据的事件类型,再通过事件定义表索引出该事件的定义,将事件类型、论元类型和该事件的定义作为思维链的内容;
7、s4:根据待抽取数据的支持集构建正例,根据待抽取数据的查询集构建待抽取文本,将正例、待抽取文本作为思维链的内容;
8、s5:使用单条待抽取数据的事件类型、论元类型、事件定义、正例、待抽取文本、篇章级事件抽取的任务描述和其他补充文本,设计对大语言模型进行多轮提问的思维链;
9、s6:将完整的思维链输入大语言模型中进行多轮问答,得到大语言模型的生成内容,对生成内容进行处理得到最终抽取结果;
10、进一步的,所述步骤s1具体包括:给定支持集ms和查询集mq;
11、定义待抽取数据集合m={ms,mq},其中(bi,ti)表示支持集ms和查询集mq中文档doci的第i个事件论元类型的边界,是doci中所有事件论元的集合;
12、进一步的,所述步骤s3具体包括:根据待抽取数据集合m中每条数据的事件论元类型ai进行分类,得到每种事件类型对应了何种论元类型,从而建立事件论元表ta;
13、再根据事件论元表ta,将事件类型和对应的论元类型输入大语言模型中,并且提示大语言模型补充出该事件的定义,得到每种事件类型的定义和描述,从而得到事件定义表td;
14、定义事件论元表为ta(e,a),定义事件定义表为td(e,d),其中e代表待抽取数据包含的事件类型集合{e1,e2,…,en},a代表待抽取数据包含的事件论元类型集合{a1,a2,…,an},d代表待抽取数据包含的每种事件类型的定义集合{d1,d2,…,dn},n是包含事件类型的个数;
15、进一步的,所述待抽取数据集合,给定单条待抽取数据mi包含了该条数据的支持集该条数据的查询集和该条数据的事件论元类型ai,定义为而支持集ms包含了支持集文本序列ws、支持集标签序列ls,查询集mq包含了查询集文本序列wq、查询集标签序列lq,定义为ms={ws,ls},mq={wq,lq};待抽取数据集合m是待抽取数据集合{m1,m2,…,mn},n是待抽取数据个数;
16、进一步的,所述步骤s4具体包括:获得待抽取数据集合m,从中提取支持集ms和查询集mq的文本序列w、标签序列l;将文本序列w转换为自然文本wp,将标签序列l转换为正确答案lp的自然文本,从而可以将该文本填充至提示模板中,以便完成思维链的构建:
17、wp=σ1(w)
18、lp=σ2(l)
19、其中,σ1表示文本序列处理函数;σ2表示标签序列处理函数;
20、定义思维链中的正确示例p={wsp,lsp};
21、其中wsp为处理好的支持集自然文本,lsp处理好的支持集正确答案;
22、给定单条数据的待抽取文本为是由单条查询集的文本序列处理后得到的自然文本;
23、进一步的,所述步骤s5具体包括:根据事件论元表,通过数据的事件论元类型来定位数据的事件类型,再根据事件定义表索引出该事件的定义和描述;给定单条待抽取数据mi,根据其包含的该条数据事件论元类型ai,在事件论元表ta(e,a)中索引出该条数据的事件类型ei。再根据所索引出的事件类型ei去事件定义表td(e,d)索引出该事件类型的定义和描述di。
24、设计对大语言模型进行多轮提问的完整思维链包括:
25、定义单条数据的思维链
26、其中ei为该条数据的事件类型;ai为该条数据事件论元类型;di为该事件类型的定义和描述;pi为该条数据支持集处理后得到的正确示例;为该条数据的待抽取文本;r是思维链中固定不变的对大语言模型进行提示的自然文本,其中包含:任务需求模板即提供篇章级事件抽取的任务描述和需求、向大语言模型提供数据前必要的补充文本、对大语言模型提出的补充要求等;
27、进一步的,所述步骤s6具体包括:将此前构建好的思维链输入至大语言模型进行多轮问答:
28、
29、其中hi为该条数据大语言模型最终生成的内容;llm为大语言模型;ti为此条数据的思维链;
30、对最终的生成内容hi通过正则表达式过滤出其中的字典表即预测答案。接着根据该字典表的键和值,即论元类型和预测的原文内容生成出与查询集的标签序列类似的预测标签序列以便进行性能验证:
31、
32、
33、其中σ3为处理生成内容的正则表达式;σ4为标签生成函数;为从大语言模型生成内容中提取出的字典表;为字典表的论元类型;为字典表的预测原文内容;是预测标签序列;
34、另一方面,本发明提出一种基于大语言模型思维链的少样本篇章级事件抽取系统,包括:
35、数据预处理模块,将待抽取数据处理为支持集和查询集两部分以适应少样本任务;
36、拓展模块,用于拓展思维链的内容,包括了编写篇章级事件抽取的任务描述和需求;索引事件类型、论元类型和该事件的定义;构建正例和待抽取文本;
37、思维链构建模块,使用单条待抽取数据的事件类型、论元类型、事件定义、正例、待抽取文本、篇章级事件抽取的任务描述和其他补充文本,设计对大语言模型进行多轮提问的思维链;
38、抽取模块,用于将完整的思维链输入大语言模型中进行多轮问答,得到对查询集中待测文本进行少样本篇章事件抽取的输出文本,将输出文本进行处理得到最后的抽取结果。
39、另一方面,本发明提出一种电子设备,包括:处理器和存储器;
40、所述存储器用于存储一个或多个程序指令;
41、所述处理器,用于运行一个或多个程序指令,用以执行上述基于大语言模型思维链的少样本篇章级事件抽取方法及系统。
42、本发明的有益效果:
43、由于大语言模型在训练阶段学习了大规模数据,因此具有较强的泛化能力。即使在少样本的情况下,它也能够利用预训练的知识来推断未见过的情况,并提供合理的解决方案。本发明利用大语言模型的泛化能力,使其能够在少样本情况下进行事件抽取,这直接减少了对大量人工标注数据的依赖。
44、此外,利用大语言模型的深层次语义理解能力,本发明能够精准地识别和抽取文本中的事件信息。这一点体现在模型对篇章级文本中隐含的复杂语义关系(如因果、转折、并列等)的理解上,能够在深层次上把握文本意义,从而实现对事件的精准定位和抽取。
45、比于传统的构建提示模板,本发明构造的思维链添加了处理任务的推理步骤,通过模拟人类思考的过程,有效提升了大语言模型对复杂任务的推理能力,增强了大语言模型对少量样本中信息的理解和利用,还能使大语言模型按照指定的答案格式生成。
46、本发明的方法不依赖于大量的领域特定数据,通过思维链的构建和大语言模型的多轮问答,使模型能够适应不同领域和数据集。在技术层面,这意味着模型能够在训练过程中学习到更加通用的语言特征和事件模式,从而在面对不同领域的文本时,仍然能够保持较高的抽取精度和鲁棒性。
47、本发明通过引入思维链,简化了模型结构,且不需要使用训练集对模型进行训练,减少了模型训练的难度和资源消耗。此外本发明的少样本性能还可以超越此前模型结构复杂、训练难度大的传统模型。
48、当然,实施本发明的任一产品并不一定需要同时达到以上所述的所有优点。
- 还没有人留言评论。精彩留言会获得点赞!