基于多头双仿射模型与注意力机制的嵌套命名实体识别方法
本发明涉及一种基于多头双仿射模型与注意力机制的嵌套命名实体识别方法,属于计算机技术中的自然语言处理领域。
背景技术:
1、命名实体识别(named entity recognition,ner):
2、这是自然语言处理(nlp)中的一个任务,旨在从文本中识别和分类命名实体,如人名、地名、组织机构名等。ner是信息抽取的一部分,有助于理解文本中的实体信息。
3、本发明的背景技术有以下几种:
4、嵌套命名实体(nested named entity):
5、有时,文本中的命名实体不仅仅是简单的实体,而可能包含其他实体的嵌套,如"欢迎来到北京工商大学"这句话中的"北京工商大学"是一个实体,而"北京"是这个实体的一个嵌套实体。嵌套命名实体识别任务是识别和分析这种复杂的实体结构。
6、基于分层的方法:
7、基于分层的方法是嵌套ner的直观解决方案,根据嵌套名称标识中结构的层次性质,这些模型通常包含多个层(或级别),每一层都用于标识一组命名实体,这些实体可以是特定级别的实体,也可以是具有特定长度的实体,由于层模块是基于分层方法的基本单元,我们根据层模块的组成将其分为两个子类,包括(1)编码器-解码器模块和(2)仅解码器模块,具体而言,编码器-解码器模块是指包含特征编码器和标签解码器的基本单元,仅解码器模块是指仅包含标签解码器的基本单元,这意味着这些模块在标签解码之前对句子进行一次编码。
8、基于区域的方法:
9、基于区域的方法通常将嵌套的ner任务视为多类分类问题,并且已经设计了各种策略来在分类之前获得潜在区域(即子序列)的表示,我们主要根据进展策略将现有的基于区域的方法分为两类,包括(1)基于枚举的策略和(2)基于边界的策略,具体地说,基于枚举的策略是指基于区域的方法,该方法从输入句子中学习所有枚举区域的表示,然后将它们分类到相应的实体类别中,基于边界的策略是指基于区域的方法,通过利用边界信息建立候选区域(可能是实体)的表示,并随后完成实体分类。
10、在实际应用中,命名实体识别的嵌套问题往往被忽略,这主要是由于计算复杂性和其他技术限制,直到最近几年,它才得到认可,作为机器学习领域的一种快速发展的效果,特别是深度学习技术,通常要处理的命名实体是非嵌套实体,但是在实际应用中,嵌套实体非常多,大多数命名实体识别会忽略嵌套实体,无法在深层次文本理解中捕获更细粒度的语义信息,因此,嵌套命名实体识别的目的就是为了解决通常的命名实体识别无法对嵌套实体进行处理的问题,在任务过程中去考虑更细粒度的实体信息,在完成通常命名实体识别任务的同时,对嵌套实体进行识别。
11、基于上述需求,本发明提供一种基于多头双仿射模型与注意力机制的嵌套命名实体识别方法,通过利用自注意力机制与多头双仿射模型 ,显著提高嵌套命名实体识别的精度和效率,更好地实现对深层次文本中语义信息的读取。
技术实现思路
1、本发明的目的在于提供一种基于多头双仿射模型与注意力机制的嵌套命名实体识别方法,通过在深度神经网络中添加自注意力机制,提高嵌套命名实体识别的精度和效率。
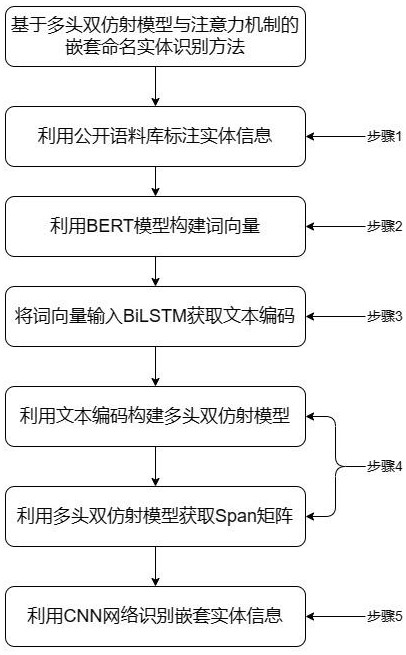
2、为解决上述问题,本发明采用的技术方案是,基于多头双仿射模型与注意力机制的嵌套命名实体识别方法,具体包括以下步骤:
3、步骤1,数据准备:使用公开语料库标记实体信息,构建模型训练的标注数据集。
4、步骤2,利用bert获取词向量:利用bert或其他预训练模型构建词向量,将文本数据转换为模型可以处理的格式,得到词向量数据集,并且可以利用bert模型预训练的参数来提高模型性能。
5、步骤3,构造bilstm模型:将准备好的数据集输入到bilstm模型中进行编码,并将bilstm模型的输出作为新的数据集,利用这个新的数据集来训练一个用于预测实体边界的多头双仿射模型。
6、步骤4,构造多头双仿射模型:使用bilstm模型的输出作为特征,利用实体标注数据集来训练双仿射模型,多头双仿射模型可以预测句子中实体的边界信息,利用它对输入句子中的实体边界进行预测,本发明提出采用起始、结束词来指明对应的片段,利用双仿射模型来得到一个span矩阵,其元素\left [ {i,j} \right ]代表对应片段(开始位置为第个词,结束位置为第个词)为某类实体的分数,该矩阵可以表示文本中所有可能的实体组合。
7、步骤5,嵌套实体分类:最后,使用构造好的span矩阵来进行嵌套实体分类,利用cnn能够有效地捕获局部特征,并且通过卷积操作可以识别不同大小和形状的实体,更好的实现嵌套命名实体识别。
8、进一步的,所述步骤1包括以下步骤:
9、步骤1.1,利用公开的语料库,对其中的语料进行筛选和优化,进行数据清洗,包括去除噪声、分词、规范化文本格式等操作,以确保标注的数据质量,以获得满足本发明要求的高质量数据。
10、步骤1.2,在数据优化时,尽量保持不同实体类型的数据平衡,以避免模型对某些实体类型的过度偏好或忽视,如果某些实体类型在语料库中数量较少,此时进行数据增强和采样等方法来平衡数据。
11、步骤1.3,得到优化过的语料库数据后,选择适合的标注工具来进行实体标注。
12、进一步的,所述步骤2包括以下步骤:
13、步骤2.1,本发明选取合适的预训练bert模型作为字词向量构建的基础模型,该模型具备良好的语义理解能力和广泛的应用性。
14、步骤2.2,将步骤1中获得的数据集输入bert模型,调用bert模型进行推理,获取每个词的对应的词向量,通常情况下,bert模型的输出是每个token的隐藏表示,本发明将提取其中的某一层的表示作为词向量。
15、进一步的,所述步骤3包括以下步骤:
16、步骤3.1,搭建一个bilstm网络,合理选择 bilstm 模型的超参数,如隐藏层大小、学习率、批处理大小等,这些超参数会影响模型的性能和训练效果,需要根据具体任务进行调整和优化,同时确定合适的训练策略,包括优化算法、学习率调度等。
17、步骤3.2,将上述步骤2获得的编码进行截断或填充,以满足bilstm网络的输入要求。
18、步骤3.3,将满足要求的数据直接输入bilstm网络中,此网络会将输入序列同时进行前向和后向建模,能够更好地捕捉语句中双向的语义依赖:
19、其中,前向的lstm网络计算公式为:
20、输入门:计算输入门的输出,以决定当前时间步的输入中哪些信息会被添加到记忆状态中,公式如下:
21、{i}_{t}=s({w}_{i}\left [ {{h}_{t-1},{x}_{t}} \right ]+{b}_{i})
22、式中:是输入门的输出,和是输入门的权重矩阵和偏置向量。
23、遗忘门:计算遗忘门的输出,以决定前一个单元的记忆状态中要保留多少信息,公式如下:
24、{f}_{t}=s({w}_{f}\left [ {{h}_{t-1},{x}_{t}} \right ]+{b}_{f})
25、式中:是遗忘门的输出,是 sigmoid 函数, 和 是遗忘门的权重矩阵和偏置向量,是上一个时间步的隐藏状态,是当前时间步的输入。
26、新的细胞状态:计算当前时间步的新的细胞状态,公式如下:
27、{c}^{\~ }_{t}=tanh({w}_{c}\left [ {{h}_{t-1},{x}_{t}} \right ]+{b}_{c})
28、式中:是新的记忆状态,是双曲正切函数,和是新的记忆状态的权重矩阵和偏置向量。
29、更新细胞状态:使用遗忘门和输入门的输出来更新细胞状态,公式如下:
30、
31、式中:是更新后的记忆状态,表示逐元素相乘操作。
32、隐藏状态:使用输出门的输出和更新后的记忆状态来计算当前时间步的隐藏状态,公式如下:
33、
34、式中:是当前时间步的隐藏状态。
35、输出门:计算输出门的输出,以决定当前时间步的隐藏状态,公式如下:
36、{o}_{t}=s({w}_{o}\left [ {{h}_{t-1},{x}_{t}} \right ]+{b}_{o})
37、式中:是输出门的输出,和是输出门的权重矩阵和偏置向量。
38、反向的lstm网络计算公式与前向的相同,但是输入的序列为从后到前:
39、输入门:
40、{i}^{'}_{t}=s({w}^{'}_{i}\left [ {{h}^{'}_{t+1},{x}_{t}} \right ]+{b}^{'}_{i})
41、遗忘门:
42、{f}^{'}_{t}=s({w}^{'}_{f}\left [ {{h}^{'}_{t+1},{x}_{t}} \right ]+{b}^{'}_{f})
43、新的细胞状态:
44、{c}^{\~ '}_{t}=tanh({w}^{'}_{c}\left [ {{h}^{'}_{t-1},{x}_{t}} \right ]+{b}^{'}_{c})
45、更新细胞状态:
46、
47、输出门:
48、{o}^{'}_{t}=s({w}^{'}_{o}\left [ {{h}^{'}_{t+1},{x}_{t}} \right ]+{b}^{'}_{o})
49、隐藏状态:
50、
51、步骤3.4,前向的lstm将输出隐向量\left [ {{h}_{l}} \right ]\left [ {} \right ]=\left [ {{h}_{l0},{h}_{l1},...,{h}_{ln}} \right ],反向的lstm将输出隐向量\left [ {{h}_{r}} \right ]\left [ {} \right ]=\left [ {{h}_{r0},{h}_{r1},...,{h}_{rn}} \right ]。
52、步骤3.5,将前向与反向输出的隐向量按照文本序列的顺序进行拼接,得到向量\left [ {h} \right ]\left [ {} \right ]=\left [ {{h}_{0},{h}_{1},...,{h}_{n}} \right ]=\left \{{\left [ {{h}_{l0,}{h}_{rn}} \right ],\left [ {{h}_{l1},{h}_{rn-1}} \right ],...\left [ {{h}_{ln},{h}_{r0}} \right ]} \right \},将向量\left [ {h} \right ]\left [ {} \right ]作为数据集。
53、进一步的,所述步骤4包括以下步骤:
54、步骤4.1,搭建一个多头双仿射模型,合理设计多头双仿射模型模型的结构,包括输入层、多头注意力层、双仿射层等,这些结构会影响模型的性能和训练效果,同时确定合适的训练策略,包括优化算法、学习率调度等。
55、步骤4.2,将上述步骤3得到的文本编码\left [ {h} \right ]\left [ {} \right ]依次分别送入两个前馈神经网络,分别是ffnn_start和ffnn_end,得到两个不同的向量表示。
56、步骤4.3,最后,使用一个biaffine模型得到分数矩阵,得到分数矩阵的计算公式为:
57、
58、
59、
60、得到的分数矩阵中的元素表示该span为不同实体类型的分数。
61、我们采用softmax函数确定实体为某种类型的分数,softmax 函数将输入向量的每个元素都映射到一个介于0和1之间的值,并且所有元素的和等于1,表示其对应的类别的概率分布,其公式如下:
62、
63、式中:是自然对数的底(欧拉数),是输入向量的第个元素,是向量的维度。
64、步骤4.5,将得到的span矩阵继续向后传递。
65、进一步的,所述步骤5包括以下步骤:
66、步骤5.1,搭建一个基于cnn的span特征提取模块,合理设计cnn模型的结构,包括输入层、空间注意力与通道注意力层、全连接层等,这些结构会影响模型的性能和训练效果,同时确定合适的训练策略,包括优化算法、学习率调度等。
67、步骤5.2,设置senet作为通道注意力的主要实现方式,将最后一个卷积层输出的特征 输入senet,提取出每一个通道的权重 。
68、步骤5.3,设置dcn作为空间注意力的主要实现方式,将最后一个卷积层输出的特征 输入dcn,提取出空间中每一个区域的权重 。
69、步骤5.4,设置一个cbam,将最后一个卷积层的输出与通道注意力获得的权重相乘,获得通道注意力加权后的图像特征,再将其与通道注意力获得的权重相乘,获得通道注意力与空间注意力融合后的特征。
70、步骤5.5,训练上述span特征提取模块,通过cnn卷积的形式,与cv领域相同去提取实体周围的边界信息,从而丰富更多的识别模式,最终提高模型的识别能力。
- 还没有人留言评论。精彩留言会获得点赞!