基于商空间粒度的数字图书馆信息检索方法、系统及介质
本发明涉及信息检索,具体涉及基于商空间粒度的数字图书馆信息检索方法、系统及介质。
背景技术:
1、数字图书馆是时代变革的产物,为适应数字技术发展和应用特点,数字图书馆改变了传统信息采集、存储及服务方式,实现数字图书馆运行的品质化升级,使得信息服务功能愈发丰富,满足了各领域对信息资源应用的迫切需求;各种知识数据库、数字图书馆、自建数据库等电子信息资源丰富了人们的知识面,拓宽了读者查找信息的途径;但数字图书馆信息资源的丰富,除了缓解信息供求矛盾外,也会带来一定的挑战。
2、数字资源的检索系统之间存在着很大的差异,为了使用不同的检索系统,用户需要花费一定的时间来适应和熟悉;科研机构和院校图书馆通常有几十个甚至数百个数据库可共享选择,用户在搜索信息时不仅要选择与主题对应的数据库,还要花大量的时间了解每个数据库中的搜索定义,熟悉每个数据库中的接口规则;用户搜索信息往往需要在好几个数据库中反复搜索,而数据库中的大多数资源记录是独立的,其相关性并不高,数据库共享的方法可实现统一的检索,但需要各数据库网站各自完成检索后反馈结果统一展示检索结果,检索效率缓慢,各数据库之间无法实现信息交换,大多数文献数据库存在重复内容,影响了用户的检索效率。
技术实现思路
1、针对数字图书馆检索效率缓慢、各资源数据之间独立的问题,本方案提供基于商空间粒度的数字图书馆信息检索方法、系统及介质;在现有共享分数据库检索技术的基础上进行方法上的改进,检索过程中无需对搜索数据库组合以外的其他无关数据库展开不必要的检索,提高检索效率;并以商空间的问题求解形式对用户检索问题进行求解;通过对目标数据库组合中的数据库分层递阶,从粗到细、逐步求精的进行检索,实现数据库中的资源数据关联,相对于传统检索平台总资源库的检索方式,大大提高了使用者的检索效率和检索准确率。
2、本发明通过下述技术方案实现:
3、本方案提供基于商空间粒度的数字图书馆信息检索方法,包括:
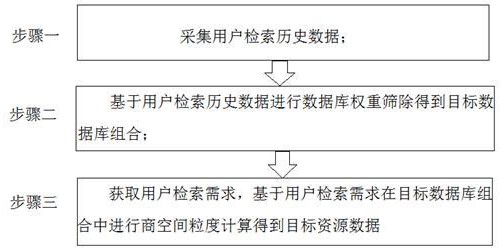
4、步骤一:采集用户检索历史数据;
5、步骤二:基于用户检索历史数据进行数据库权重筛除得到目标数据库组合;
6、步骤三:获取用户检索需求,基于用户检索需求在目标数据库组合中进行商空间粒度计算得到目标资源数据。
7、本方案工作原理:针对数字图书馆检索效率缓慢、各数据库之间独立的问题,本方案提供基于商空间粒度的数字图书馆信息检索方法,在现有共享分数据库检索技术的基础上进行检索方法上的改进:
8、一方面,根据用户检索历史数据构建出意向数据库组合,初步筛选出用户常用的数据库,剔除完全不会用到的数据库,检索过程中无需遍历搜索所有的共享数据库,避免了意向数据库组合以外的其他无关数据库的无效搜索过程,提高检索效率;至于被剔除的数据库可以在用户根据索结果判定是否需要单独搜索,按照自定义模式进一步展开搜索。
9、另一方面,本方案还在目标资源数据的搜索过程层面进行了搜索方法上的改进;以商空间的问题求解形式对用户检索问题进行求解;通过对目标数据库组合中的数据库分层递阶,从粗到细、逐步求精的进行检索,相对于传统检索平台总资源库的检索方式,大大提高了使用者的检索效率。
10、进一步优化方案为,所述基于用户检索历史数据进行数据库权重筛除得到目标数据库组合,包括方法:
11、t1,获取用户检索日志,从用户检索日志中提取出有效检索记录;所述有效检索包括具有一个或多个检索结果输出的检索过程;
12、t2,获取各有效检索对应的使用数据库;所述使用数据库包括对检索结果具有操作动作的数据库,所述操作动作包括:点击、复制、浏览或下载;
13、t3,基于各有效检索对应的使用数据库构建用户u的动作数据库组合:
14、;
15、其中,表示第n个数据库;用向量表示;表示第n个数据库的权重;
16、t4,将动作数据库组合中权重小于权重阈值t的所有元素删除得到用户u的目标数据库组合。
17、进一步优化方案为,第n个数据库的权重根据下式计算:
18、
19、其中,表示有效检索 i的检索结果的总浏览量和总下载量总数,表示有效检索i在数据库中检索结果的最大下载量,t表示最大下载量系数,1.1≥t≥0.98;表示有效检索i的检索结果总数,表示数据库中包含的检索结果总数。
20、进一步优化方案为,所述基于用户检索需求在目标数据库组合中进行商空间粒度计算得到目标资源数据,包括方法:
21、s1,用图向量表示目标数据库组合,并用三元组表示出所述图向量;
22、s2,对所述三元组进行快速粒化操作得到检索商空间模型:
23、从论域方向、属性函数方向或商空间结构的颗粒化方向获取商空间粒度;在不改变论域的属性函数f的情形下,对论域x和拓扑结构t分别进行粒化;
24、s3,根据检索商空间模型得到目标资源数据。
25、进一步优化方案为,步骤s1包括以下子步骤:
26、s11,由图g=(v,e)表示目标数据库组合中的各数据库,其中集合v=(v1,v2,… ,vn)表示数据库中资源数据节点的集合,n表示资源数据节点的总数;集合e=(e1,e2,… ,em)表示与检索需求关联的资源数据节点的集合,m为与检索需求关联的资源数据节点的总数;
27、s12,用三元组(x,f,t)表示图g=(v,e),其中论域x表示集合v;f表示资源数据节点与检索需求的关联属性信息;拓扑结构t表示集合e。
28、进一步优化方案为,对论域x粒化的方法包括:
29、先初始化每个资源数据节点为一个粒子,并按节点度对各粒子升序编号;
30、依次按照步骤a-步骤b遍历每个粒子,直至所有粒子包含的节点都不再变化:
31、步骤a,将当前节点从它归属的粒子删除,并计算将当前节点分别加入每个相邻粒子后的节点度增量△q;
32、步骤b,判断最大节点度增量△qmax的值是否大于0;若是,则将当前节点加入最大节点度增量△qmax对应的相邻粒子中;否则,将当前节点放回原归属粒子。
33、进一步优化方案为,对拓扑结构t粒化的方法包括:
34、将各粒子进行两两连边:对于a粒子与b粒子,拓扑结构tab为a粒子对应的所有节点与b粒子对应的所有节点两两连线;
35、计算介于a粒子与b粒子之间的节点连线的权值之和;a粒子内部所有节点连线的权值之和,b粒子内部所有节点连线的权值之和;
36、构建粒子关联系数:
37、;
38、其中t表示当前数据库的权重;
39、当时,保留拓扑结构tab作为粒化后的拓扑结构,否则删除拓扑结构tab。
40、进一步优化方案为,获取检索商空间模型中节点度值最高的粒层,输出粒层中包含的每个粒子对应的资源数据。
41、本方案还提供基于商空间粒度的数字图书馆信息检索系统,用于实现上述的基于商空间粒度的数字图书馆信息检索方法,所述系统包括:
42、采集模块,用于采集用户检索历史数据;
43、数据库组合构建模块,用于基于用户检索历史数据进行数据库权重筛除得到目标数据库组合;
44、计算模块,用于获取用户检索需求,基于用户检索需求在目标数据库组合中进行商空间粒度计算得到目标资源数据。
45、本方案还提供一种计算机可读介质,其上存储有计算机程序,所述计算机程序被处理器执行可实现如上述的基于商空间粒度的数字图书馆信息检索方法。
46、本发明与现有技术相比,具有如下的优点和有益效果:
47、1、本发明提供的基于商空间粒度的数字图书馆信息检索方法、系统及介质;根据用户检索历史数据构建出意向数据库组合,初步筛选出用户常用的数据库,剔除完全不会用到的数据库,检索过程中无需遍历搜索所有的共享数据库,避免了意向数据库组合以外的其他无关数据库的无效搜索过程,提高检索效率;至于被剔除的数据库可以在用户根据索结果判定是否需要单独搜索,按照自定义模式进一步展开搜索;
48、2、本发明提供的基于商空间粒度的数字图书馆信息检索方法、系统及介质;在目标资源数据的搜索过程层面进行了搜索方法上的改进;以商空间的问题求解形式对用户检索问题进行求解;通过对目标数据库组合中的数据库分层递阶,从粗到细、逐步求精的进行检索,实现数据库中的资源数据关联,相对于传统检索平台总资源库的检索方式,大大提高了使用者的检索效率和检索准确率。
- 还没有人留言评论。精彩留言会获得点赞!