基于强化学习的任务调度方法、装置、设备、介质及产品与流程
本发明涉及人工智能,尤其涉及基于强化学习的任务调度方法、装置、设备、介质及产品。
背景技术:
1、算力网络由广泛、分散、异构的算力和网络组成,包括通用算力(云、边、端)、智算和超算等算力,以及接入网、承载网、核心网和传输网等网络,涉及到的资源类型和数量庞大,并且存在跨区域跨地域的特点,并且随着虚拟化、云化和容器化的普及带来了便利的同时系统架构也变得更加复杂。
2、为了改善算力网络资源的使用性能,需要对任务进行动态调度,在算力网络环境下,传统的任务调度通常采用启发式算法,但是基于启发式算法的任务调度不能完全适应云、边、端资源动态变化和不确定等特性,容易引发负载不均衡,从而对算力网络环境下的服务性能和资源利用效率产生影响。
技术实现思路
1、本发明提供基于强化学习的任务调度方法、装置、设备、介质及产品,用以解决现有技术中任务调度容易引发负载不均衡,影响算力网络的服务性能和资源利用效率的缺陷,实现提高算力网络的服务性能和资源利用效率。
2、本发明提供一种基于强化学习的任务调度方法,包括:
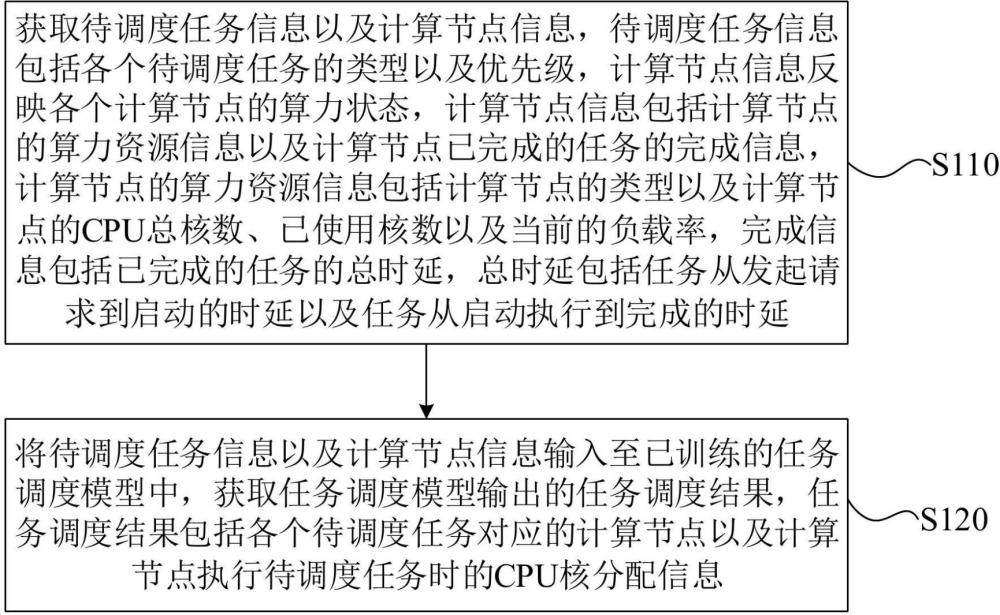
3、获取待调度任务信息以及计算节点信息,所述待调度任务信息包括各个待调度任务的类型以及优先级,所述计算节点信息反映各个计算节点的算力状态,所述计算节点信息包括所述计算节点的算力资源信息以及所述计算节点已完成的任务的完成信息,所述计算节点的算力资源信息包括所述计算节点的类型以及所述计算节点的cpu总核数、已使用核数以及当前的负载率,所述完成信息包括已完成的任务的总时延,所述总时延包括任务从发起请求到启动的时延以及任务从启动执行到完成的时延;
4、将所述待调度任务信息以及所述计算节点信息输入至已训练的任务调度模型中,获取所述任务调度模型输出的任务调度结果,所述任务调度结果包括各个所述待调度任务对应的所述计算节点以及所述计算节点执行所述待调度任务时的cpu核分配信息;
5、其中,所述任务调度模型基于强化学习训练得到,所述任务调度模型在强化学习中的奖励值基于所述任务调度模型输出的样本任务调度结果对应的任务总时延以及所述计算节点执行任务时的负载率。
6、根据本发明提供的一种基于强化学习的任务调度方法,所述任务调度模型的训练过程包括:
7、将样本待调度任务信息以及样本计算节点信息输入至所述任务调度模型中,获取所述任务调度模型输出的样本任务调度结果,所述样本待调度任务信息基于样本待调度任务得到,所述样本计算节点信息基于样本计算节点得到;
8、基于所述样本任务调度结果进行任务调度,将各个样本待调度任务分配至对应的所述样本计算节点进行执行,得到各个所述样本待调度任务被执行后的总时延以及所述样本计算节点执行所述样本待调度任务时的负载率;
9、基于各个所述样本待调度任务的总时延与预设时延阈值的关系确定各个第一评价值,基于各个所述样本计算节点执行所述样本待调度任务时的负载率与预设负载率范围的关系确定第二评价值;
10、对所述第一评价值和所述第二评价值进行加权求和,得到所述奖励值;
11、基于所述奖励值更新所述任务调度模型。
12、根据本发明提供的一种基于强化学习的任务调度方法,所述基于各个所述样本待调度任务的总时延与预设时延阈值的关系确定各个第一评价值,包括:
13、若所述样本待调度任务的总时延低于所述样本待调度任务对应的所述预设时延阈值,则所述第一评价值为第一值,否则所述第一评价值为第二值,所述第一值大于所述第二值;
14、所述基于各个所述样本计算节点执行所述样本待调度任务时的负载率与预设负载率范围的关系确定第二评价值,包括:
15、若所述样本计算节点执行所述样本待调度任务时的负载率在所述样本计算节点对应的所述预设负载率范围内,则所述第二评价值为第三值,否则所述第二评价值为第四值,所述第三值大于所述第四值。
16、根据本发明提供的一种基于强化学习的任务调度方法,所述基于各个所述样本待调度任务的总时延与预设时延阈值的关系确定各个第一评价值之前,包括:
17、基于所述样本待调度任务的优先级确定所述样本待调度任务对应的所述预设时延阈值。
18、根据本发明提供的一种基于强化学习的任务调度方法,所述基于各个所述样本计算节点执行所述样本待调度任务时的负载率与预设负载率范围的关系确定第二评价值之前,包括:
19、基于所述样本计算节点的节点类型确定所述样本计算节点对应的所述预设负载率范围。
20、根据本发明提供的一种基于强化学习的任务调度方法,获取所述计算节点信息,包括:
21、基于所述待调度任务的类型,在所述计算节点已完成的任务中确定参考任务;
22、基于所述参考任务确定所述完成信息。
23、本发明还提供一种基于强化学习的任务调度装置,包括:
24、状态信息获取模块,用于获取待调度任务信息以及计算节点信息,所述待调度任务信息包括各个待调度任务的类型以及优先级,所述计算节点信息反映各个计算节点的算力状态,所述计算节点信息包括所述计算节点的算力资源信息以及所述计算节点已完成的任务的完成信息,所述计算节点的算力资源信息包括所述计算节点的类型以及所述计算节点的cpu总核数、已使用核数以及当前的负载率,所述完成信息包括已完成的任务的总时延,所述总时延包括任务从发起请求到启动的时延以及任务从启动执行到完成的时延;
25、模型推理模块,用于将所述待调度任务信息以及所述计算节点信息输入至已训练的任务调度模型中,获取所述任务调度模型输出的任务调度结果,所述任务调度结果包括各个所述待调度任务对应的所述计算节点以及所述计算节点执行所述待调度任务时的cpu核分配信息;
26、其中,所述任务调度模型基于强化学习训练得到,所述任务调度模型在强化学习中的奖励值基于所述任务调度模型输出的样本任务调度结果对应的任务总时延以及所述计算节点执行任务时的负载率。
27、本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种所述基于强化学习的任务调度方法。
28、本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述基于强化学习的任务调度方法。
29、本发明还提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上述任一种所述基于强化学习的任务调度方法。
30、本发明提供的基于强化学习的任务调度方法、装置、设备、介质及产品,通过获取待调度任务信息以及计算节点信息,待调度任务信息包括各个待调度任务的类型以及优先级,计算节点信息反映各个极端节点的算力状态,将调度任务信息以及计算节点信息输入至已训练的任务调度模型,得到任务调度模型输出的任务调度结果,可以实现同时考虑待调度任务以及计算节点状态的任务调度,并且,本发明中的任务调度模型基于强化学习训练得到,强化学习训练过程中的奖励值基于任务调度模型输出的样本任务调度结果对应的任务总时延以及计算节点执行任务时的负载率,从而使得任务调度模型能够输出总时延低、负载均衡的任务调度结果,实现提高算力网络的服务性能和资源利用效率。
- 还没有人留言评论。精彩留言会获得点赞!