基于对比学习和条件计算的个性化联邦学习方法与流程
本发明属于机器学习,涉及联邦学习方法,尤其涉及一种基于对比学习和条件计算的个性化联邦学习方法。
背景技术:
1、边缘云计算是边缘计算和云计算的结合,与传统的云计算相比效率得到了很大的提升。边缘云计算提供低延迟、高带宽和更好的用户体验。不需要把大量本地数据发送到云端进行处理,缩短了数据处理计算节点与用户之间的距离,在满足用户低时延需求的同时,用户数据可以在本地训练进而实现数据隐私保护。而联邦学习是分布式机器学习技术,其核心思想是各个参与方在不共享本地数据源的前提下协同构建全局模型,即数据不动模型动、数据可用不可见。边缘云计算和联邦学习相结合可以提供更高的数据处理效率和更好的机器学习结果。联邦学习不需要将原始数据上传到云服务器上,只需要交换模型参数和一些中间结果,从而保证了数据的隐私性和安全性并且减少了数据的传输量。边缘云计算将云服务从网络核心推向更接近物联网设备和数据源的网络边缘,减少了数据传输的延迟,使得联邦学习可以更快速地进行模型训练和更新。
2、公开号为cn114694015a的专利申请公开了基于通用框架的多任务联邦学习场景识别方法及相关组件,虽然其提出的框架无需对不同训练任务的训练数据集进行参数调整,但是它对高度异构数据的收敛性较差,并不能达到理想的效果。
3、公开号为cn115511108a的专利申请公开了一种基于数据集蒸馏的联邦学习个性化方法,对本地数据进行处理生成蒸馏数据并将蒸馏数据加密后上传至服务器;服务器利用所有的加密蒸馏数据进行全局模型训练,但是没有考虑模型的通信成本的问题,因此仍有很大的提升空间。
4、公开号为cn115688939a的专利申请公开了一种基于对抗式特征增广的长尾数据个性化联邦学习方法,利用特定的采样平衡样本特征集dbal和生成平衡样本特征集训练所述全局分类器f,结合全局特征提取器g,得到本地个性化模型,但是没有考虑边缘客户端和其他客户端的区别。
5、公开号为cn114385376a的专利申请公开了一种异构数据下边缘侧联邦学习的客户端选择方法,通过计算权重变化信息来衡量客户端更新的重要性,实现了fl服务器在真实的异构数据环境中确保被选择的数据样本符合科学性和代表性,同时通过增加额外选择的客户端数量参数s和周期参数p进一步提升fl训练模型的准确率,并且减少能耗;但网络性能不佳,仍有改进的空间。
6、因此,在大尺寸和复杂通信网络的物联网环境下,异质性的边缘设备是大量存在,带来了隐私、连接、带宽和延迟的挑战。现阶段,边缘云协同下的联邦学习(federatedlearning,fl)方法面临几个基本挑战:(i)对高度异构数据的收敛性较差,以及(ii)缺乏个性化解决方案。在存在异构本地数据分布的情况下,这些问题会恶化单个客户端上的全局fl模型的性能,甚至可能会阻碍受影响的客户端加入fl流程。由于客户端的数据集之间往往是非独立同分布的(non-independent and identically distributed,non-iid),直接进行模型聚合往往会影响模型的整体性能。传统的卷积神经网络(cnn)在计算机视觉任务中非常成功,但是它们对输入图像的尺寸和固定形状有着严格的要求。
技术实现思路
1、本发明的目的在于针对现有技术中的不足,提供一种基于对比学习和条件计算的个性化联邦学习方法,可以有效的提升联邦学习模型的效率,并大大降低了通信轮次。
2、为了达到上述目的,本发明采样以下技术方案来实现。
3、本发明提供的基于对比学习和条件计算的个性化联邦学习方法,由中央服务器和若干客户端实现;所述中央服务器包括全局模型;所述客户端包括全局模型、对比模型和客户端本地模型;所述全局模型、对比模型和客户端本地模型网络结构相同,均包括特征提取器和头部网络;该个性化联邦学习方法包括以下步骤:
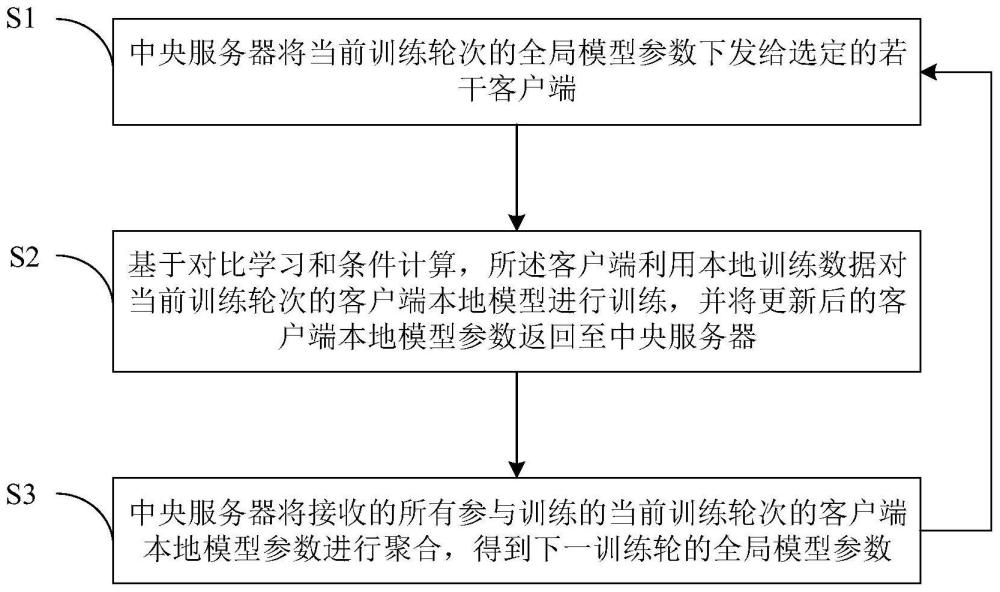
4、s1中央服务器将当前训练轮次的全局模型参数下发给选定的若干客户端;
5、s2基于对比学习和条件计算,所述客户端利用本地训练数据对当前训练轮次的客户端本地模型进行训练,并将更新后的客户端本地模型参数返回至中央服务器;该步骤包括以下分步骤:
6、s21将本地训练数据分别输入全局模型、对比模型和本地模型中;
7、s22依据全局模型、对比模型和本地模型特征提取器提取的特征获取对比损失;
8、s23依据全局模型和本地模型特征提取器提取的特征,基于条件计算获取mmd损失;
9、s24依据全局模型头部网络和本地模型头部网络得到的总输出获取分类损失;
10、s25上述对比损失、mmd损失和分类损失构成总损失;
11、s26依据总损失对本地模型参数进行优化更新;
12、重复上述步骤s21-s26,直至本地模型收敛,各客户端将训练更新后的本地模型参数上传至中央服务器;
13、s3中央服务器将接收的所有参与训练的当前训练轮次的客户端本地模型参数进行聚合,得到下一训练轮的全局模型参数,并返回至步骤s1,直至所述中央服务器的全局模型收敛。
14、上述基于对比学习和条件计算的个性化联邦学习方法,总体架构假设有一个中央服务器和n个客户端,表示为m1,...,mn。每个客户端都有一个本地的训练数据集di。第i个客户端的优化目标为:
15、
16、其中,f(·;θi)表示基于参数θi的预测函数,f(xi;·)返回softmax操作之前的“logits”,l(·,·)表示损失函数,xi表示客户端的输入数据,yi表示标签数据,表示第i个客户端的期望损失。表示第i个客户端在第t个全局训练回合中的本地模型参数。θt表示中央服务器上的全局模型参数。在第t轮的个性化学习阶段,选择st个客户端,被选择的客户端下载全局模型参数,即,其中i∈st,并使用本地的训练数据集di训练该本地模型。一个数据集(xi,yi)在上述公式中的损失如下所示:
17、
18、其中,b是数据批量的大小。可以通过深度学习的方法进行个性化,将个性化训练后的本地模型参数表示为在聚合过程中,中央服务器收到这些个性化本地模型并取参数的平均值作为全局模型参数:中央服务器会将θt+1分发给下一训练轮次的另一个客户集当中,以进行下一训练轮次的个性化和聚合。在本地客户端,为下一训练轮次的客户端本地模型参数。
19、用d、k和c分别是输入空间、特征空间和标签空间的维度。本发明将全局模型、对比模型和客户端本地模型网络分为特征提取器及头部两个部分,特征提取器将输入映射到特征空间,头部head从低维特征空间映射到标签空间。本发明将全局模型、对比模型和客户端本地模型网络给定主干网络中的最后一个全连接层视为头部。
20、本发明中,全局模型、对比模型和客户端本地模型使用的是vit(visiontransformer),其为一种基于transformer架构的图像分类模型。所述vit包括嵌入层、变换编码器和多层感知机(mlp);以嵌入层和变换编码器作为特征提取器,以mlp作为头部。所述客户端还包括cpn模块;所述全局模型和本地模型的特征提取器提取的特征经cpn进行处理后再输入相应的头部,来分离全局特征信息和个性化特征信息;针对不同客户端的non-iid情况在不同的路由中处理它们。所述cpn模块包括全连接层、归一化层和relu激活函数。
21、上述步骤s2的目的是,基于对比学习和条件计算,对当前训练轮次的客户端本地模型进行训练。步骤s21中全局模型使用的是当前训练轮次的全局模型参数,对比模型使用的是上一训练轮次的本地模型参数;本地模型使用的是当前训练轮次的本地模型参数,当前训练轮次的本地模型参数,当前训练轮次开始时,首先使用当前轮次的全局模型参数对当前训练轮次的本地模型参数进行重写。进一步的,所述全局模型参数和对比模型参数都处于冻结状态,只参与前向传播。在冻结全局模型头部中的全局信息和个性化头部中的个性化信息的指导下,cpn可以学习生成特定于样本的策略,并自动分离全局信息和个性化信息,并且cpn网络θi在每轮学习中也会进行更新。在每一轮的学习中,我们先基于θt参数去重写然后再进行本轮的训练,使用对比学习能够让模型进行有效学习,贴近全局模型的优化方向,在这种情况下,模型的优化方向会受到改变,而让上一轮的本地个性化模型参与对比学习有效缓解了模型的遗忘性。
22、上述步骤s22中,依据全局模型、对比模型和本地模型的特征提取器提取的特征(ft、和)构建对比损失函数lsim,加快收敛速度。
23、对比损失函数计算公式如下:
24、
25、式中,sim(·)表示相似函数。
26、上述步骤s23中,为了让全局模型和本地模型特征提取器提取的特征(ft和)进行特征对齐,将二者送入mmd损失函数进行约束。
27、mmd损失函数计算公式如下:
28、
29、式中,表示ft和的最大均值差异。
30、上述步骤s24中,使用交叉熵损失函数来对本地模型头部和全局模型头部网络的分类结果进行约束。
31、
32、式中,lcls表示分类损失,c表示类别数,yj表示真实标签的one-hot编码向量中第j个元素的取值(0或1),pj表示预测概率向量中第j个元素的取值。该公式是将所有类别的交叉熵损失进行求和,通过最小化交叉熵损失来优化多分类模型的参数。
33、因此,上述步骤s25中的总损失函数为:l=lcls+lmmd+lsim。
34、上述步骤s26中,使用adam优化算法对本地模型参数进行优化。按照前面给出的优化目标,判断本地模型是否收敛;也可以通过设置迭代次数来实现。然后,各客户端将训练更新后的本地模型参数上传至中央服务器。
35、在本地模型训练过程中,每一轮冻结全局模型头部head,经过cpn网络得到全局特征信息和个性化特征信息。与本地训练的个性化head相加,形成新的本地模型头部head权重进行上传,以使个性化主体部分与全局主体部分拉近距离。
36、
37、式中,表示本地模型头部参数,ht表示全局模型头部参数,表示上传至中央服务器的头部参数。
38、上述步骤s3中,中央服务器将接收的各客户端本地模型参数进行聚合得到全局模型参数。本发明中使用fedavg算法将各客户端本地模型参数进行聚合,得到全局模型参数,并返回至步骤s1,下发至下一轮训练选择的客户端。如此循环,直至所述中央服务器的全局模型收敛。可以通过设置训练轮次来判断全局模型是否收敛。
39、与现有技术相比,本发明具有以下有益效果:
40、(1)本发明引入对比学习和条件计算,使用对比学习拉大本地模型与对比模型的差异;使用条件计算对全局模型和个性化本地模型特征提取部分进行选择,选取合适的参数进行聚合,使得个性化本地模型的准确率大大提高,并减少通信轮次;
41、(2)本发明将vit网络与个性化联邦学习结合,提出了vit-pfl,提升了个性化本地模型的准确率。
- 还没有人留言评论。精彩留言会获得点赞!