一种基于大模型的运算环境自动切换系统的制作方法
本发明涉及计算资源任务调度,尤其涉及一种基于大模型的运算环境自动切换系统。
背景技术:
1、在需要大规模简单计算任务各公司会采用gpu,复杂逻辑会选择采用cpu。然而gpu处理单元众多,所需高速缓存空间大,高性能gpu远远比现在市面上的高性能cpu价格贵出好几倍。
2、一种基于大模型的运算环境自动切换系统,能根据任务计算需求自动切换cpu和gpu作业,能很好地利用cpu的资源和解决gpu资源浪费,并且能满足公司不同任务在同一时间区间充分利用有限资源完成任务。
3、中国专利公开号:cn117170878a公开了一种动态调整cpu和gpu缓存的方法所述方法包括实时监听cpu运行数据和gpu运行数据,当一次任务结束时,根据输入、输出和操作信息构建图数据;根据图数据中的开始节点对图数据进行缓存,得到以开始节点为索引的缓存表,并根据缓存表中的数据量对缓存表进行数值标定;基于所述标签对所有缓存表中的数据进行分类,计算每个图数据的占用值,根据所述占用值调整cpu的优先级和gpu的优先级;该发明将cpu和gpu已经处理的数据及其处理过程转换为图数据,由图数据对处理过程的资源消耗量进行计算,进而根据计算出的结果对cpu的优先级和gpu的优先级进行动态调节,优化了配合过程。
4、由此可见,现有技术中在执行运算环境切换过程中,对数据处理的过程控制精准性不足,从而导致cpu和gpu资源浪费的问题。
技术实现思路
1、为此,本发明提供一种基于大模型的运算环境自动切换系统,用以克服现有技术中在执行运算环境切换过程中,对数据处理的过程控制精准性不足,从而导致cpu和gpu资源浪费的问题。
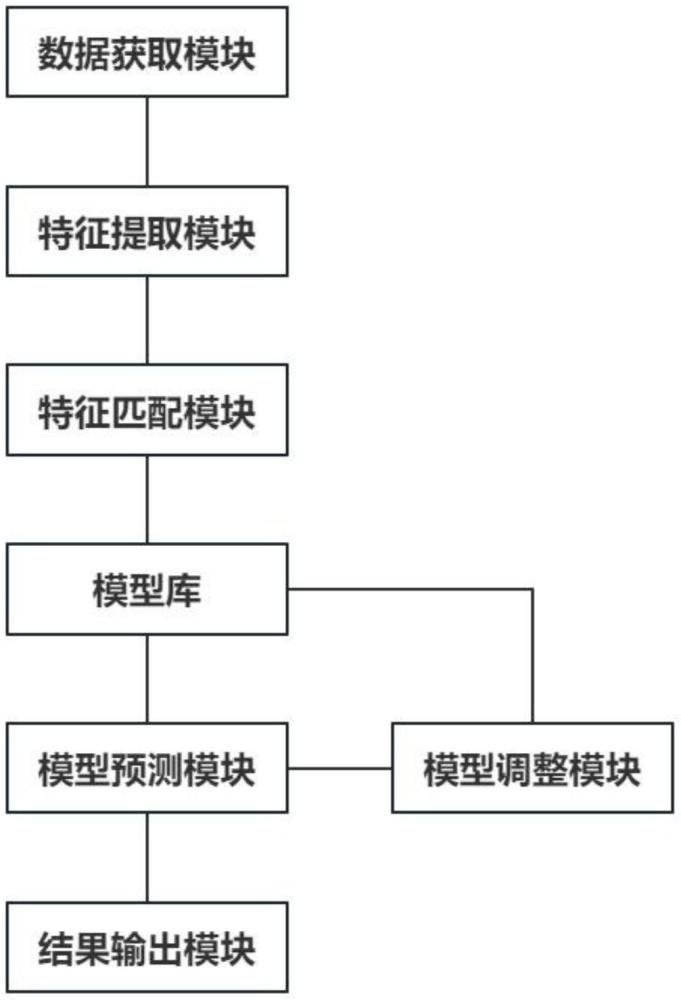
2、为实现上述目的,本发明提供一种基于大模型的运算环境自动切换系统,包括:
3、模型库,其用以存储任务处理过程所需的模型;
4、数据获取模块,其用以获取用户终端的网关请求数据;
5、特征提取模块,其与所述数据获取模块连接,用以提取所述请求数据中的特征数据,并根据特征数据的重要程度确定对所述特征数据的提取,以及确定针对所述特征数据的提取粒度;
6、特征匹配模块,其分别与所述模型库和所述特征提取模块连接,用以将所述特征提取模块提取的特征数据与历史任务的历史特征数据进行匹配,确定相似度最高的历史任务的资源消耗,以对待处理任务进行模糊定级,并根据特征匹配确定所述请求数据对应的待处理任务的行业领域;
7、模型预测模块,其分别与所述模型库和所述特征匹配模块连接,用以根据所述特征匹配模块的匹配结果预测所述待处理任务所需的模型;
8、模型调整模块,其与所述模型预测模块连接,用以对模型进行调整并确定调整后的所述模型的评估准确率,以根据调整次数确定预测断点;同时统计模型调整前的梯度累积数量以确定对所述特征提取模块的提取过程的修正;
9、或,根据调整次数确定对调整过程和所述特征提取模块的提取过程的优化;
10、结果输出模块,其与所述模型预测模块连接,用以输出运算环境的切换结果。
11、进一步地,所述特征提取模块根据特征数据的重要程度确定对所述数据特征的提取包括在重要程度评价值小于等于预设重要程度评价值的条件下根据语义连贯程度确定对所述特征数据的提取。
12、进一步地,所述特征提取模块根据语义连贯程度确定对所述特征数据的提取包括根据语义连贯程度和预设语义连贯程度的对比结果确定提取比例。
13、进一步地,所述语义连贯程度根据以下公式进行计算,设定,
14、
15、其中,q表示语义连贯程度,(i,j)表示节点,即文本中的关键词向量,wij表示权重系数,所述权重系数根据文本中节点关键词的共同出现的频率确定,s(i,j)表示语义相似度,所述语义相似度通过词嵌入模型来计算两个词的向量表示,并计算这些向量之间的余弦相似度。
16、进一步地,所述特征提取模块根据特征数据的重要程度确定对所述数据特征的提取包括在重要程度评价值大于预设重要程度评价值的条件下根据重要程度评价值与预设重要程度评价值的差值确定对所述特征数据的提取。
17、进一步地,所述特征提取模块根据重要程度评价值与预设重要程度评价值的差值确定对所述特征数据的提取包括根据重要程度评价值与预设重要程度评价值的差值和预设重要程度评价值相对差的对比结果确定提取粒度。
18、进一步地,所述重要程度评价值根据以下公式进行计算,设定,
19、
20、其中,p表示重要程度评价值,n表示影响特征数据的因素总数,si表示第i个因素的评分值,所述评分值根据分析历史任务的历史特征数据进行确定,di表示第i个因素的权重系数,所述权重系数根据每个因素的影响程度进行确定。
21、进一步地,所述模型调整模块在调整次数小于等于预设调整次数的条件下根据调整次数确定预测断点。
22、进一步地,所述模型调整模块根据所述梯度累积数量对所述特征提取模块的提取过程的修正包括在梯度累积数量大于预设梯度累积数量的条件下确定根据修正系数对所述提取比例或所述提取粒度进行修正。
23、进一步地,所述修正系数为其中δn表示梯度累积数量与预设梯度累积数量的差值。
24、进一步地,所述模型调整模块在调整次数大于预设调整次数的条件下,根据调整次数和预设调整次数的差值与预设调整次数相对差的对比结果确定对所述调整过程或所述特征提取模块的提取过程的优化。
25、进一步地,所述模型调整模块在调整次数和预设调整次数的差值小于等于预设调整次数相对差的条件下,所述模型调整模块对历史数据进行替换处理。
26、进一步地,所述模型调整模块在调整次数和预设调整次数的差值大于预设调整次数相对差的条件下,所述模型调整模块根据调整系数对所述预设重要程度评价值进行调整。
27、进一步地,所述调整评估准确率根据以下公式进行计算,设定,
28、
29、其中,a表示调整评估准确率,t表示预训练数据量,tmax表示预训练数据量的最大值,f表示数据质量。
30、进一步地,所述调整系数为其中δc表示调整次数与预设调整次数的差值。
31、与现有技术相比,本发明的有益效果在于,本发明通过设置所述特征提取模块,根据不同的重要程度评价值对特征采取不同的提取方式,能够保证数据特征提取结果更加准确,同时为所述特征匹配模块模糊定级做了良好的基础。采取不同的提取粒度,可以使数据特征提取过程更加灵活、适应性强,并有助于提高系统的性能和模型的泛化能力。
32、进一步地,所述特征提取模块在重要程度评价值小于等于预设重要程度评价值的条件下根据语义连贯程度确定对所述特征数据的提取比例,相对应的,所述语义连贯程度越高,则从文本中提取的特征数据的比例越少,在不同的情况下选择不同的提取比例,能够提高特征数据的提取准确率。
33、进一步地,所述特征提取模块在重要程度评价值小于等于预设重要程度评价值的条件下根据重要程度评价值与预设重要程度评价值的差值确定对所述特征数据的提取粒度,在重要程度评价值较高的情况下,能够提高重要特征数据的提取准确率,为后续的特征匹配做了良好的基础。
34、进一步地,本发明通过设置所述特征匹配模块,能够根据历史任务的资源消耗对待处理任务进行模糊定级和预测模型,能够提高系统的工作效率,更快的确定cpu和gpu的选择。
35、进一步地,本发明通过设置模型调整模块,并确定调整评估准确率,根据调整次数确定预测断点或确定对调整过程和所述特征提取模块的提取过程的优化,能够提高数据处理过程控制的精准性。
36、进一步地,所述模型调整模块根据调整次数与预设调整次数的差值确定对所述调整过程或所述特征提取模块的提取过程采用不同的优化方式,能够提高调整评估准确率,提高模型的泛化能力和应用场景。
37、进一步地,所述模型调整模块在优化所述特征提取模块的提取过程时,采用特定的调整系数对所述预设重要程度评价值进行调整,能够避免出现过度调整的情况。
38、进一步地,系统通过控制数据处理过程的精准度,根据任务计算需求自动切换cpu和gpu作业,能够一定程度上解决cpu和gpu资源浪费的问题,并且能实现不同任务在同一时间区间充分利用有限资源完成任务。
- 还没有人留言评论。精彩留言会获得点赞!