一种基于知识图谱的大模型训练方法、装置及电子设备与流程
本技术涉及数据处理领域,具体涉及一种基于知识图谱的大模型训练方法、装置及电子设备。
背景技术:
1、随着技术的发展和大数据时代的到来,大模型在处理复杂数据分析和预测任务中扮演了不可替代的角色。这些模型通过学习海量的数据集合,可以在多个领域如自然语言处理、图像识别等方面展现出卓越的性能。然而,随着应用需求的不断深入,单一依赖于大规模非结构化数据的训练策略暴露出其局限性,特别是在理解复杂实体和关系时的不足。
2、目前,传统的大模型训练方法多侧重于从非结构化数据中提取信息,忽略了结构化数据的潜力。这导致了以下问题:模型在训练时无法有效利用存在于结构化数据中的丰富关系和实体信息。
3、因此,亟需一种基于知识图谱的大模型训练方法、装置及电子设备。
技术实现思路
1、本技术提供了一种基于知识图谱的大模型训练方法、装置及电子设备,通过结构化数据和非结构化数据构建和应用知识图谱,使模型能够在训练过程中更好地理解和利用数据之间的关系。
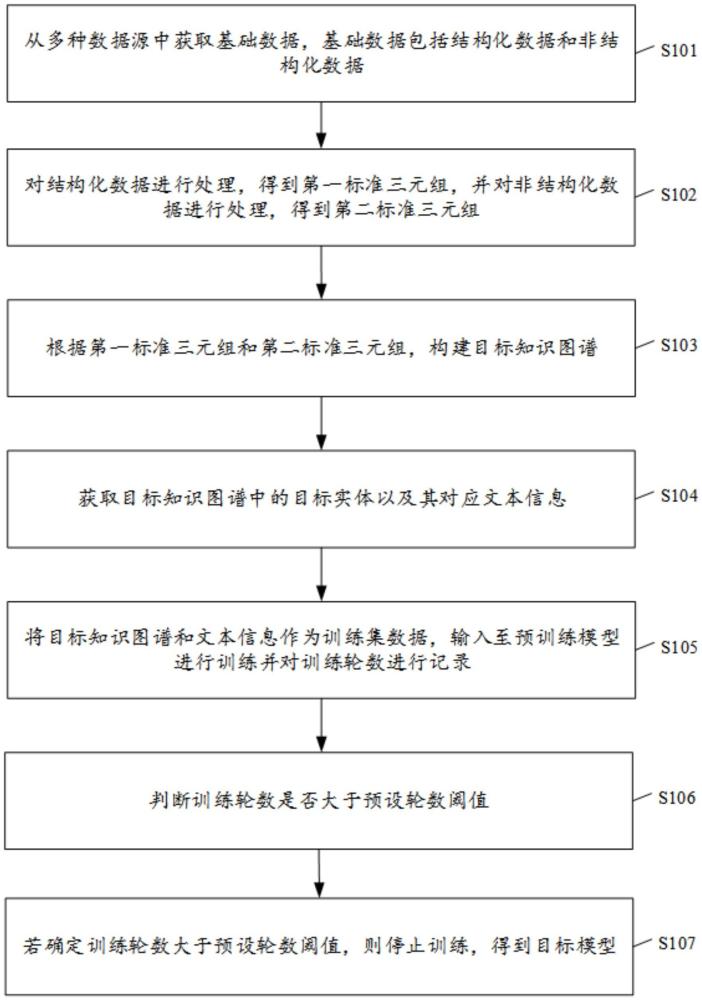
2、在本技术的第一方面提供了一种基于知识图谱的大模型训练方法,该方法包括:从多种数据源中获取基础数据,所述基础数据包括结构化数据和非结构化数据;对所述结构化数据进行处理,得到第一标准三元组,并对所述非结构化数据进行处理,得到第二标准三元组;根据所述第一标准三元组和所述第二标准三元组,构建目标知识图谱;获取所述目标知识图谱中的目标实体以及其对应文本信息;将所述目标知识图谱和所述文本信息作为训练集数据,输入至预训练模型进行训练并对训练轮数进行记录;判断所述训练轮数是否大于预设轮数阈值;若确定所述训练轮数大于所述预设轮数阈值,则停止训练,得到目标模型。
3、通过采用上述技术方案,该方法能够从多种数据源中获取基础数据,包括结构化数据和非结构化数据,从而使得模型能够综合不同类型的信息进行学习,提高了模型的全面性和准确性。基于获取的结构化数据和非结构化数据,该方法能够构建目标知识图谱。目标知识图谱是一种以图形结构存储和表示知识的方式,能够有效地组织和表达实体之间的关系,为模型提供了丰富的语义信息。同时,该方法中提供了一种判断训练轮数是否达到预设轮数阈值的机制。当训练轮数超过了预设阈值时,自动停止训练,以避免过拟合或者提高训练效率。通过将目标知识图谱和其对应的文本信息作为训练数据,可以提高模型对各类数据(结构化数据和非结构化数据)的理解能力。
4、可选的,对所述结构化数据进行处理,得到第一标准三元组,并对所述非结构化数据进行处理,得到第二标准三元组,具体包括:基于预设映射规则,将所述结构化数据中的表、列以及行映射为所述第一标准三元组;对所述非结构化数据进行提取,得到对应的实体、实体的属性以及实体之间的关系,进而得到所述第二标准三元组。
5、通过采用上述技术方案,通过预设映射规则,将结构化数据中的表、列以及行映射为第一标准三元组。这种处理方式能够将数据表中的信息转化为三元组形式,使得数据更容易被模型理解和处理。对非结构化数据进行提取,得到实体、实体的属性以及实体之间的关系,进而生成第二标准三元组。这种处理方式能够从文本等非结构化数据中提取出有用的信息,并将其转化为结构化的表示形式,为模型提供了更丰富的语义信息。生成的第一标准三元组和第二标准三元组具有标准化的表示形式,有利于后续的知识图谱构建和模型训练。
6、可选的,根据所述第一标准三元组和所述第二标准三元组,构建目标知识图谱,具体包括:提取出所述第一标准三元组包括的多个第一实体和所述第二标准三元组包括的多个第二实体;对第一目标实体和第二目标实体进行相似度判断,所述第一目标实体为多个所述第一实体中的任意一个第一实体,所述第二目标实体为多个所述第二实体中的任意一个第二实体;若确定所述第一目标实体和所述第二目标实体的相似度大于或等于预设相似度阈值,则将所述第一标准三元组或者所述第二标准三元组构建为所述目标知识图谱。
7、通过采用上述技术方案,通过比较和融合不同实体和关系(如第一标准三元组和第二标准三元组),促进了不同数据集之间的整合。这对于构建一个综合性更强、视角更全面的知识图谱尤为重要。
8、可选的,对第一目标实体和第二目标实体进行相似度判断之后,所述方法还包括:若确定所述第一目标实体和所述第二目标实体的相似度小于所述预设相似度阈值,则将所述第一标准三元组和所述第二标准三元组构建为所述目标知识图谱。
9、通过采用上述技术方案,即使第一目标实体和所述第二目标实体的相似度低于预设相似度阈值,它们两均会被构建至目标知识图谱中,这样可以确保图谱中包含更多的数据点和关系,从而增强知识图谱的完整性和信息丰富性。
10、可选的,获取所述目标知识图谱中的目标实体以及其对应文本信息,具体包括:将所述目标知识图谱中包含的目标实体作为检索关键字,并根据所述检索关键字在预设文本数据集中进行检索,得到所述检索关键字对应的文本信息。
11、通过采用上述技术方案,通过将目标知识图谱中的目标实体作为检索关键字,在预设文本数据集中进行检索,能够获取与这些实体相关的文本信息。这样做有助于丰富知识图谱中实体的语义信息,提供更全面的实体描述。
12、可选的,将所述目标知识图谱和所述文本信息作为训练集数据,输入至预训练模型进行训练并对训练轮数进行记录之后,所述方法还包括:采用测试集数据对所述目标模型进行性能评估,得到所述目标模型的准确度;若确定所述准确度小于或等于预设准确度阈值,则判断所述训练轮数是否大于预设轮数阈值;若确定所述准确度大于预设准确度阈值,则停止训练,得到所述目标模型。
13、通过采用上述技术方案,通过采用测试集数据对目标模型进行性能评估,可以客观地评估目标模型在未见过的数据上的准确度。当目标模型的准确度低于或等于预设准确度阈值时,会根据预设轮数阈值来判断是否继续训练。当模型的准确度达到了预设准确度阈值时,停止训练,得到目标模型。这种优化与停止策略能够确保模型在达到一定准确度后不再过度训练,防止过拟合,同时也保证了模型的准确性和泛化能力。
14、可选的,对训练轮数进行记录,具体包括:在每个训练轮次结束时,通过日志记录当前的训练轮次编号;对所述训练轮次编号进行个数统计,得到所述训练轮数。
15、通过采用上述技术方案,通过对训练轮次编号进行统计,可以得到训练轮数的数量。这有助于了解目标模型训练所经历的总轮数,为后续的分析和报告提供数据支持。
16、在本技术的第二方面提供了一种基于知识图谱的大模型训练装置,该装置包括:获取模块和处理模块;所述获取模块,用于从多种数据源中获取基础数据,所述基础数据包括结构化数据和非结构化数据;所述处理模块,用于对所述结构化数据进行处理,得到第一标准三元组,并对所述非结构化数据进行处理,得到第二标准三元组;所述处理模块,用于根据所述第一标准三元组和所述第二标准三元组,构建目标知识图谱;所述获取模块,还用于获取所述目标知识图谱中的目标实体以及其对应文本信息;所述处理模块,还用于将所述目标知识图谱和所述文本信息作为训练集数据,输入至预训练模型进行训练并对训练轮数进行记录;所述处理模块,还用于判断所述训练轮数是否大于预设轮数阈值;所述处理模块,还用于若确定所述训练轮数大于所述预设轮数阈值,则停止训练,得到目标模型。
17、在本技术的第三方面提供了一种电子设备,包括处理器、存储器、用户接口以及网络接口,所述存储器用于存储指令,所述用户接口和所述网络接口均用于与其他设备通信,所述处理器用于执行所述存储器中存储的指令,以使所述电子设备执行如上述任意一项所述的方法。
18、在本技术的第四方面提供了一种计算机可读存储介质,所述计算机可读存储介质存储有指令,当所述指令被执行时,执行如上述任意一项所述的方法。
19、综上所述,本技术实施例中提供的一个或多个技术方案,至少具有如下技术效果或优点:
20、1、该方法能够从多种数据源中获取基础数据,包括结构化数据和非结构化数据,从而使得模型能够综合不同类型的信息进行学习,提高了模型的全面性和准确性。基于获取的结构化数据和非结构化数据,该方法能够构建目标知识图谱。知识图谱是一种以图形结构存储和表示知识的方式,能够有效地组织和表达实体之间的关系,为模型提供了丰富的语义信息。通过获取目标知识图谱中的实体及其对应的文本信息,将知识图谱和文本信息作为训练集数据输入至预训练模型进行训练。方法中提供了一种判断训练轮数是否达到预设轮数阈值的机制。当训练轮数超过了预设阈值时,自动停止训练,以避免过拟合或者提高训练效率。
21、2、通过预设映射规则,将结构化数据中的表、列以及行映射为第一标准三元组。这种处理方式能够将数据表中的信息转化为三元组形式,使得数据更容易被模型理解和处理。对非结构化数据进行提取,得到实体、实体的属性以及实体之间的关系,进而生成第二标准三元组。这种处理方式能够从文本等非结构化数据中提取出有用的信息,并将其转化为结构化的表示形式,为模型提供了更丰富的语义信息。生成的第一标准三元组和第二标准三元组具有标准化的表示形式,有利于后续的知识图谱构建和模型训练。
22、3、通过精确地选择相似度高的实体对进行知识图谱的构建,可以确保所构建的知识图谱在内容上更为准确和相关,从而提升知识图谱的质量和实用性。通过比较和融合来自不同源的实体和关系(如第一和第二标准三元组),促进了不同数据集之间的整合。这对于构建一个综合性更强、视角更全面的知识图谱尤为重要。
- 还没有人留言评论。精彩留言会获得点赞!