基于深度学习算法进行患者行为的姿态估计方法与流程
本发明是基于深度学习算法进行患者行为的姿态估计方法,属于医疗领域。
背景技术:
1、姿态估计(pose estimation):指通过计算机视觉技术,从图像或视频中推断出人体或物体的姿势和动作信息的过程。在姿态估计中,通常使用计算机算法来检测关键关节点的位置、确定整体的朝向和姿势等。
2、在医疗领域,患者行为姿态的准确评估对于诊断和治疗具有重要意义。传统上,医生通常依赖于主观观察和手动评估来判断患者的行为姿态,这种方法存在主观性高、易受误差影响等问题。随着深度学习技术的发展,利用传感器、摄像头等设备采集患者的运动和姿势数据,并通过深度学习算法进行分析和处理,已经成为一种新的解决方案。深度学习技术通过学习大量数据中的特征,能够自动化地识别和分析患者的行为姿态,从而实现客观化、准确化的评估。
3、目前,基于深度学习的实时姿态估计包括深度学习模型:使用卷积神经网络(cnn)和图卷积网络(gcn)等深度学习模型,对患者的图像或视频数据进行处理,并推断出关节点的位置和姿态信息。数据采集装置:使用摄像头或深度传感器等设备,实时采集患者的图像或视频数据,并传输到深度学习模型进行处理。实时姿态估计算法:在深度学习模型的基础上,设计实时的姿态估计算法,以便在治疗过程中及时获取和更新患者的姿态信息。
4、上述方案的缺点是:
5、1、缺乏准确性和稳定性:现有的姿态估计技术在某些情况下可能存在准确性和稳定性的问题。例如,传统的计算机视觉方法可能对光照变化、遮挡或复杂背景等因素敏感,导致关节点检测不准确或不稳定。深度学习方法虽然在一定程度上提高了准确性,但在较复杂的姿势和动作情况下仍可能存在误检或漏检的问题。
6、2、实时性和延迟:某些姿态估计技术在实时性方面存在挑战。计算复杂的深度学习模型可能需要较长的处理时间,导致实时姿态估计的延迟。这对于需要即时反馈和指导的康复治疗而言是不理想的。
7、3、个性化和多样性:现有技术难以适应不同患者的个体化需求和多样化的姿势变化。每个患者的身体特征和康复目标可能不同,但现有技术往往缺乏对个体差异的充分考虑,无法提供针对性的康复辅助。
技术实现思路
1、针对现有技术存在的不足,本发明目的是提供基于深度学习算法进行患者行为的姿态估计方法,以解决上述背景技术中提出的问题。
2、为了实现上述目的,本发明是通过如下的技术方案来实现:基于深度学习算法进行患者行为的姿态估计方法,包括如下步骤:
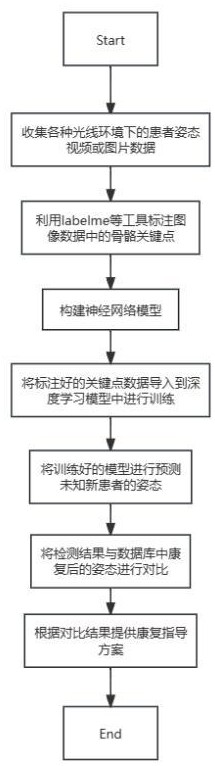
3、步骤1:数据收集与预处理:收集各种光线环境下的患者姿态视频或者图片数据作为训练数据,以确保数据具有多样性;对收集到的数据进行预处理,包括图像去噪、调整大小、对比度、亮度等操作,确保所有图像具有相似的格式、质量和特征,以提高后续模型训练的效果;使用labelme等标注工具对图像中的人物骨骼关键点进行标注,然后将标注格式转换成模型训练的格式;
4、步骤2:构建神经网络结构:基于pytorch深度学习框架构建神经网络模型;
5、步骤3:模型训练:将标注好的数据导入构建好的深度学习模型中,设置训练参数,例如轮次、批次大小、学习率、优化器等参数以保证模型能够快速收敛,模型的性能达到最优,然后进行模型训练;
6、步骤4:模型预测及评估:用训练好的模型测试未知患者的视频或图像数据,然后对预测的结果进行评估;
7、步骤5:测试结果对比:将检测结果与数据库中康复后的姿态进行对比;
8、步骤6:康复指导:根据对比结果提供康复指导方案,以便及时跟进康复情况。
9、具体地,在所述步骤2中,神经网络结构包括backbone主干网络、neck网络和head网络。
10、具体地,所述backbone主干网络用于提取图像特征,backbone主干网络包括c2f模块,c2f模块让backbone主干网络在保证轻量化的同时获得更加丰富的梯度流信息,c2f模块包括cbs模块、bottleneck模块,cbs模块包括卷积conv、批量归一化bn、激活函数silu,卷积conv用于提取输入数据的特征,批量归一化bn 用于改善深度神经网络的训练和收敛性,激活函数silu是一种激活函数,用于引入非线性特性并改善模型的表达能力。
11、具体地,所述bottleneck模块的作用:减少参数和计算量:bottleneck模块通过使用1×1的卷积层来降低输入通道的维度,然后再使用3×3的卷积层进行特征提取,最后再通过1×1的卷积层将通道维度增加回来,这样的设计显著减少模型的参数数量和计算量,在通道较多的情况下效果更为明显;提高模型的表达能力:bottleneck模块在减少参数和计算量的同时,能够保持较大的感受野,通过使用1×1的卷积层来降维和增维,在保持局部特征表达的同时,引入更多非线性变换,并提高模型的表达能力,对于处理复杂的视觉任务和大规模图像数据具有重要意义;深度残差连接:bottleneck模块通常与深度残差连接一起使用,以促进信息的流动和梯度的传播,深度残差连接允许直接的路径将输入特征传递到输出,使得模型可以更轻松地学习残差映射,这种连接方式有助于缓解梯度消失问题,使得深层网络的训练更加稳定和高效。
12、具体地,所述neck网络将backbone主干网络提取的多个特征图进行特征融合,将高层语义特征与低层语义特征进行融合,neck网络包括aifi模块和ccfm模块。
13、具体地,aifi模块:attention-based intra-scale feature interaction,基于注意力的尺度内特征交互,为transformer的encoder层,由注意力机制self-attention和前馈神经网络feed forward neural network组成,作用为:实现尺度内特征交互,编码当前位置的像素特征时,会计算其他位置特征的得分以决定放多少注意力,同时降低多个尺度的特征之间进行注意力运算,计算消耗较大等问题,对于aifi模块,首先将二维的s5特征拉成向量,然后交给aifi模块处理,再将输出reshape回二维,记作f5,以便去完成后续的“跨尺度特征融合”。
14、具体地,ccfm模块:cnn-based cross-scale feature-fusion module,基于cnn的跨尺度特征融合模块,作用为:将经过aifi模块的高层语义特征f5和低层语义特征s3、s4进行“跨尺度特征融合”,关于ccfm模块中的fusion结构包括两个1×1卷积和n个repblock,这里之所以写成n,能通过调整 ccfm中repblock的数量和 encoder 的编码维度分别控制hybrid-encoder的深度和宽度,同时对backbone进行相应的调整即可实现检测器的缩放。
15、具体地,repblock的工作原理:repblock是基于repvgg提出的结构重参数化方法的一种改进,采用了多分支训练和单分支推理的方式,以达到较好的精度-速度权衡;在训练阶段,repblock由多个卷积层组成,其中包括1×1卷积、3×3卷积和relu激活函数,这些卷积层能提取图像的特征信息,并通过残差连接来传递梯度和信息;在推理阶段,repblock转换为3×3卷积层+relu激活函数的堆叠,这样可以利用3×3卷积在cpu和gpu上的优化和计算密度,提高推理速度;repblock的作用:repblock的backbone中起到了增强表征能力和提高推理速度的作用;repblock可以在不同大小的模型中实现精度和效率的平衡。
16、具体地,经过neck网络后得到两个网络头,每个网络头利用每个空间level的双卷积块生成每个网格单元的得分和相应的姿态特征,这些姿态特征用于预测边界框、关键点坐标和可见性,双卷积块包括普通卷积conv和分组卷积gconv。
17、具体地,在所述步骤3中,训练参数设置:seed:随机种子,用于实现可重复性,通过设置相同的随机种子,使得每次运行时的随机过程保持一致,以便于结果的复现;optimizer:选择要使用adamw优化器,adamw是adam优化算法的一种变体,在adam的基础上引入了权重衰减weight decay的修正项,adamw的目的是解决adam算法在优化深度神经网络时可能引起权重衰减不准确的问题。
18、本发明的有益效果:
19、能够准确地检测和跟踪患者的关节点位置和姿态信息,该算法结合了深度学习模型和实时数据处理技术,提供了更高的准确性和稳定性。
20、能够在较低的延迟下进行姿态估计,以满足康复治疗过程中的即时反馈需求,该系统通过优化数据采集和处理流程,实现了快速的姿态估计和实时的康复辅助。
21、能够根据患者的个体差异和康复目标,提供个性化的治疗建议和指导,通过灵活的算法设计和用户界面,系统能够适应不同患者的需求,并提供针对性的康复训练方案。
22、能够收集和分析患者的姿态数据,并生成相关的统计和报告,帮助康复专业人员进行康复进展的评估和治疗效果的监测。
- 还没有人留言评论。精彩留言会获得点赞!