一种基于图挖掘的中央空调系统异常检测方法
本发明属于异常数据检测的,具体涉及一种基于图挖掘的中央空调系统异常检测方法。
背景技术:
1、中央空调系统异常检测是指基于历史数据分析,通过监测、分析和识别中央空调系统运行过程中的与大部分运行状态不同的异常状态或行为,以及与正常运行模式不一致的特征,从而实现对系统异常情况的及时检测和诊断。通过中央空调系统异常检测,可以帮助管理者及时识别异常运行模式,进行调整,提高系统的可靠性、安全性和效率。此外,异常检测还有助于预防性维护,及时发现潜在问题并进行修复,延长设备的使用寿命,降低运维成本,提升用户体验和服务质量。
2、中央空调系统的运行数据存在运行参数多,参数耦合性强,缺乏异常标签数据等问题,运行参数数量与类型的增加可能导致模型的计算量和复杂程度大幅增加。数据之间的强耦合性则增加了空调运行状态异常检测的难度,缺乏异常标签则导致基于有监督学习方法的异常检测模型难以应用于工程实际,限制异常检测的准确性。常用的无监督异常检测方法中,聚类方法不适用于高维数据,常用于设备故障或者传感器故障这样的低维异常检测工作;关联规则挖掘方法对大规模数据集效率较低,缺乏结构信息,挖掘结果相对简单,缺乏直观性和整体性;自组织人工神经网络算法可以有效的处理复杂数据,但需要选择合适特征,且模型缺乏可解释性,难以判断异常原因。
技术实现思路
1、本发明的主要目的在于克服现有技术的缺点与不足,提供一种基于图挖掘的中央空调系统异常检测方法,基于diffi算法的高维数据特征提取方法,克服了常用的特征选择算法针对分类和回归问题的不足,挑选出异常检测的典型特征,以解决设备运行数据高纬度高耦合的问题,提高图挖掘的效率。
2、为了达到上述目的,本发明采用以下技术方案:
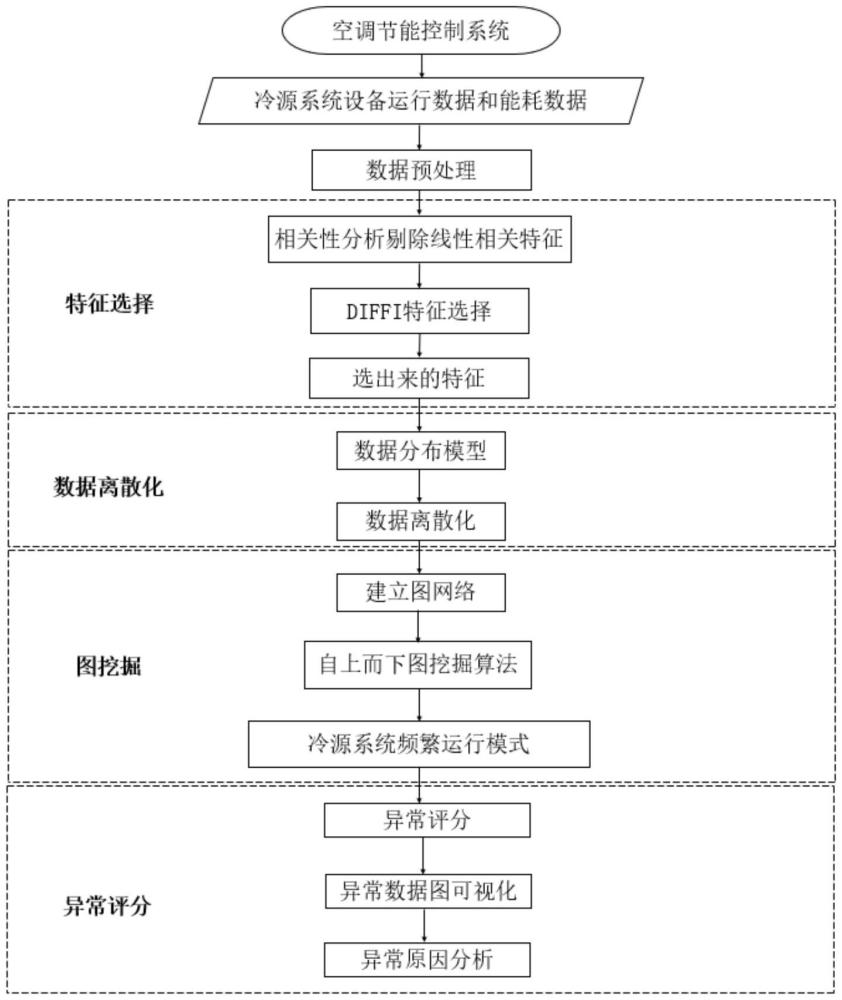
3、第一方面,本发明提供了一种基于图挖掘的中央空调系统异常检测方法,包括下述步骤:
4、获取中央空调系统运行数据和室外气象数据,构建多源数据集;
5、对多源数据集中连续型数据进行数据清洗,并将完成数据清洗的多源数据集进行特征筛选,获取异常检测模型的敏感特征;所述连续型数据包括非稳态数据、突变值、缺失值和逻辑异常值;
6、根据运行数据的分布模式选择数据离散化方法,将敏感特征划分到相应的区间内;
7、对各种敏感特征之间的关联性进行分析,构建数据图网络;对历史的数据图网络进行频繁子图挖掘,获取中央空调系统的频繁运行模式;
8、比较每个时刻的数据图网络和频繁子图,识别异常数据图,计算异常数据图的异常得分;根据异常数据图的拐点确定阈值,标记异常得分超过阈值的频繁运行模式为异常运行模式;
9、标记同种运行模式下数据图网络和频繁子图不匹配的数据。
10、作为优选的技术方案,所述将完成数据清洗的多源数据集进行特征筛选,包括:
11、s21、过皮尔森相关系数进行相关性分析剔除共线性特征;
12、s22、通过基于深度的孤立森林特征选择算法筛选出对异常检测模型最敏感的数据。
13、作为优选的技术方案,所述步骤s22,具体为:
14、构建建立随机树t,计算随机树t中样本的异常得分,得到异常点pi,t和正常点po,t;
15、计算该随机树上每个分割点的iics;
16、更新累计特征重要度cfis值,将正常样本和异常样本在随机树t中经历路径中分隔点的分割效率iics和路径长度归一化组合到一起,并通过累加的方式更新函数值;
17、设置c值统计节点v分割被分割的频次,计算特征重要度gfi值;
18、将特征重要度gfi值排序,选择排名靠前的特征参数。
19、作为优选的技术方案,所述将敏感特征划分到相应的区间内,包括:
20、检测数据集的分布模型,分布模型用于确定数据是否符合特定的概率分布;
21、根据分布模型采用对应的数据离散化方法,对敏感特征划分到相应的区间内;
22、所述离散化方法包括等宽离散化法、等频离散化法、基于kde的自然断点法和基于平均值和标准偏差离散化。
23、作为优选的技术方案,所述对各种敏感特征之间的关联性进行分析,构建数据图网络,包括:
24、分析中央空调冷源系统中不同数据之间的耦合关系,获取关联信息;
25、对于任意数据之间的关联信息,采用三元组形式表示,将具有关联关系的数据连上线,构成图网络模型;
26、所述三元组包括主体变量、客体变量和关联规则部分,如下式:
27、g=(subject,target,action)
28、其中,subject表示一条关联属性中的主体变量,target表示一条关联属性中的客体变量,action表示主体变量和客体变量之间的关联规则。
29、作为优选的技术方案,所述对历史的数据图网络进行频繁子图挖掘,包括:
30、建立四元组,包括节点标签信息和边信息;将每一时刻t形成的数据图网络结构及其边的组合作为边集edg;计算边的支持度,当边的支持度大于设定的频繁边的最小支持度阈值时,则判定为频繁边;
31、对每一时刻形成的数据图网络,移除不频繁边,获取图网络集;判断图网络集是否存在同构图,若存在具有同构图的数据图网络,保留具有同构图的数据图网络中的一个,删除其余同构图;
32、计算数据图网络的图支持度,当图支持度大于设定的频繁子图的支持度阈值时,则判断其为最大频繁子图。
33、作为优选的技术方案,还包括对非频繁图网络的处理,具体为:
34、挖掘比非频繁图网络少一条边的子图,累积计算子图支持度,当该子图支持度大于设定的频繁子图的支持度阈值时,则保留其为最大频繁子图,否则将该子图加入非频繁子图集,在下一次搜索中,继续找比该子图少一条边的子图,并判断该子图是否是频繁子图,直到子图中边的数量为1,停止搜索。
35、作为优选的技术方案,所述计算异常数据图的异常得分,具体为:
36、如果某一时刻的数据图网络与频繁子图不同,则该时刻运行模式异常;计算每个时刻的数据图异常评分,如下式:
37、
38、其中,at表示t时刻数据图的异常评分,y表示频繁子图的个数,ns,j表示jth频繁子图的边和点的总数,dt,j表示t时刻数据图和jth频繁子图不同边和不同点的个数。
39、作为优选的技术方案,所述标记同种异常行模式下数据图网络和频繁子图不匹配的数据,具体为:
40、标记同种运行模式下的数据图网络和频繁子图,当某一时刻的数据图网络的异常评分小于设定的阈值,则该时刻数据图网络和频繁子图为同种运行模式;
41、将异常的数据图网络和同种运行模式下的频繁子图进行比较,采用第一标记方式标记匹配的节点;完成标记后,若存在不匹配的节点,则标记不匹配节点;将没标记节点标记为过滤节点,并通过neo4j实现异常的数据图网络可视化;
42、根据标记后的异常数据图,分析异常原因。
43、作为优选的技术方案,所述标记数据节点不匹配节点,具体为:若异常的数据图网络的节点值比频繁子图的节点值高,则采用第二标记方式标记不匹配的节点;若异常的数据图网络的节点值比频繁子图的节点值低。
44、本发明与现有技术相比,具有如下优点和有益效果:
45、(1)本发明采用图挖掘数据处理技术,利用数据的值和数据之间的关系,构建数据图结构,挖掘不同参数之间的关联模式和频繁运行模式,并通过分析图中的模式来发现潜在的异常情况或非常规运行状态,并提高了模型的可解释性,通过标记可视化图结构中的异常参数,便于运维人员判断异常原因。
46、(2)本发明采用数据预处理和特征选择技术,在尽可能保留正常运行数据有效信息的前提下,降低后续图挖掘模型的计算量。
- 还没有人留言评论。精彩留言会获得点赞!